
105. 从前序与中序遍历序列构造二叉树
难度中等597收藏分享切换为英文关注反馈
根据一棵树的前序遍历与中序遍历构造二叉树。
注意:
你可以假设树中没有重复的元素。
例如,给出
前序遍历 preorder = [3,9,20,15,7]
中序遍历 inorder = [9,3,15,20,7]
返回如下的二叉树:
3
/ \
9 20
/ \
15 7
分析
二叉树相关的很多问题的解决思路都有分治法的思想在里面。我们复习一下分治法的思想:把原问题拆解成若干个与原问题结构相同但规模更小的子问题,待子问题解决以后,原问题就得以解决,“归并排序”和“快速排序”都是分治法思想的应用,其中“归并排序”先无脑地“分”,在“合”的时候就麻烦一些;“快速排序”开始在 partition 上花了很多时间,即在“分”上使了很多劲,然后就递归处理下去就好了,没有在“合”上再花时间。
抓住“前序遍历的第 1 个元素一定是二叉树的根结点”,不难写出代码。关键还是拿 LeetCode 上面的例子画一个图,思路就很清晰了。
前序遍历数组的第 1 个数(索引为 0)的数一定是二叉树的根结点,于是可以在中序遍历中找这个根结点的索引,然后把“前序遍历数组”和“中序遍历数组”分为两个部分,就分别对应二叉树的左子树和右子树,分别递归完成就可以了。
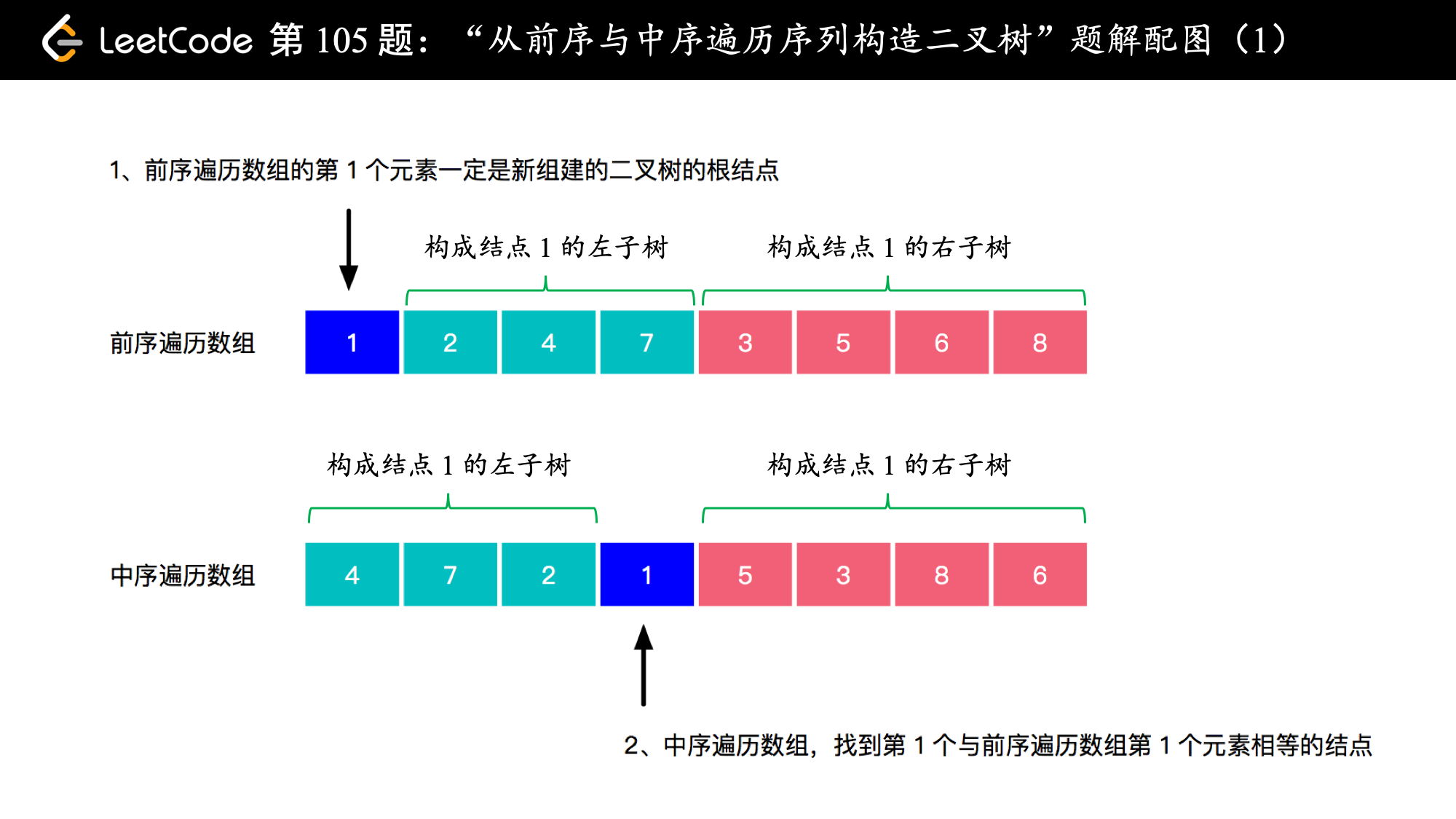
下面是一个具体的例子,演示了如何计算数组子区间的边界:
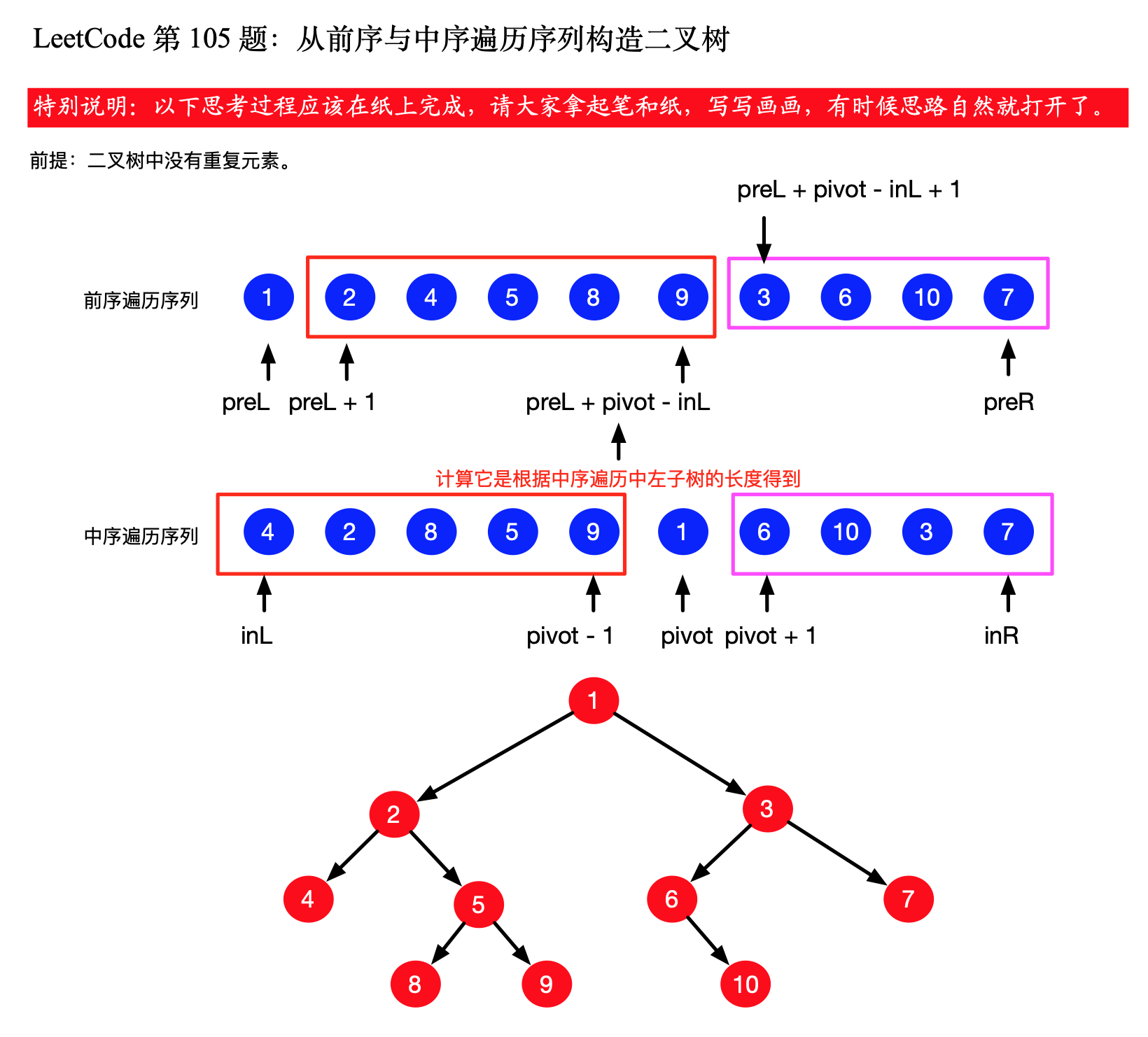
这道题完成了以后可以顺便把 「力扣」 第 106 题:从中序与后序遍历序列构造二叉树也一起做了。
参考代码 1:
- Java
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) {
val = x;
}
}
public class Solution {
public TreeNode buildTree(int[] preorder, int[] inorder) {
int preLen = preorder.length;
int inLen = inorder.length;
if (preLen != inLen) {
throw new RuntimeException("Incorrect input data.");
}
return buildTree(preorder, 0, preLen - 1, inorder, 0, inLen - 1);
}
/**
* 使用数组 preorder 在索引区间 [preLeft, preRight] 中的所有元素
* 和数组 inorder 在索引区间 [inLeft, inRight] 中的所有元素构造二叉树
*
* @param preorder 二叉树前序遍历结果
* @param preLeft 二叉树前序遍历结果的左边界
* @param preRight 二叉树前序遍历结果的右边界
* @param inorder 二叉树中序遍历结果
* @param inLeft 二叉树中序遍历结果的左边界
* @param inRight 二叉树中序遍历结果的右边界
* @return 二叉树的根结点
*/
private TreeNode buildTree(int[] preorder, int preLeft, int preRight,
int[] inorder, int inLeft, int inRight) {
// 因为是递归调用的方法,按照国际惯例,先写递归终止条件
if (preLeft > preRight || inLeft > inRight) {
return null;
}
// 先序遍历的起点元素很重要
int pivot = preorder[preLeft];
TreeNode root = new TreeNode(pivot);
int pivotIndex = inLeft;
// 严格上说还要做数组下标是否越界的判断 pivotIndex < inRight
while (inorder[pivotIndex] != pivot) {
pivotIndex++;
}
root.left = buildTree(preorder, preLeft + 1, pivotIndex - inLeft + preLeft,
inorder, inLeft, pivotIndex - 1);
root.right = buildTree(preorder, pivotIndex - inLeft + preLeft + 1, preRight,
inorder, pivotIndex + 1, inRight);
return root;
}
}
复杂度分析:
(这里感谢用户 @duanxiaodai 的纠正。)
- 时间复杂度:O(N^2),这里 NN 是二叉树的结点个数,每调用一次递归方法创建一个结点,一共创建 NN 个结点,在中序遍历中找到根结点在中序遍历中的位置,是与 NN 相关的,这里不计算递归方法占用的时间。
- 空间复杂度:O(1),这里不计算递归方法占用的空间。
参考代码 2:可以将中序遍历的值和索引存在一个哈希表中,这样就可以一下子找到根结点在中序遍历数组中的索引。
- Java
import java.util.HashMap;
import java.util.Map;
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) {
val = x;
}
}
public class Solution {
private int[] preorder;
private Map<Integer, Integer> hash;
public TreeNode buildTree(int[] preorder, int[] inorder) {
int preLen = preorder.length;
int inLen = inorder.length;
if (preLen != inLen) {
throw new RuntimeException("Incorrect input data.");
}
this.preorder = preorder;
this.hash = new HashMap<>();
for (int i = 0; i < inLen; i++) {
hash.put(inorder[i], i);
}
return buildTree(0, preLen - 1, 0, inLen - 1);
}
private TreeNode buildTree(int preLeft, int preRight, int inLeft, int inRight) {
// 因为是递归调用的方法,按照国际惯例,先写递归终止条件
if (preLeft > preRight || inLeft > inRight) {
return null;
}
// 先序遍历的起点元素很重要
int pivot = preorder[preLeft];
TreeNode root = new TreeNode(pivot);
int pivotIndex = hash.get(pivot);
root.left = buildTree(preLeft + 1, pivotIndex - inLeft + preLeft,
inLeft, pivotIndex - 1);
root.right = buildTree(pivotIndex - inLeft + preLeft + 1, preRight,
pivotIndex + 1, inRight);
return root;
}
}
复杂度分析:
- 时间复杂度:O(N),这里 NN 是二叉树的结点个数,每调用一次递归方法创建一个结点,一共创建 N 个结点,这里不计算递归方法占用的时间。
- 空间复杂度:O(N),这里忽略递归方法占用的空间,因为是对数级别的,比 N 小。
本文标题:【leetcode】105.从前序和中序遍历序列构造二叉树(详细图解,java实现)
本文链接:https://blog.quwenai.cn/post/4696.html
版权声明:本文不使用任何协议授权,您可以任何形式自由转载或使用。

100. 相同的树,98. 验证二叉搜索树,28. 对称的二叉树")
141.环形链表I,142.环形链表II")
11.盛水最多的容器,283.移动零,15.三数之和")
还没有评论,来说两句吧...