
46. 全排列
难度中等825收藏分享切换为英文关注反馈
给定一个 没有重复 数字的序列,返回其所有可能的全排列。
示例:
输入: [1,2,3]
输出:
[
[1,2,3],
[1,3,2],
[2,1,3],
[2,3,1],
[3,1,2],
[3,2,1]
]
分析
请读者带着以下问题理解回溯搜索算法的思想。
1、什么是“树形问题”?为什么是在树形问题上使用“深度优先遍历”?不用深度优先遍历我们还可以用什么?
2、什么是“回溯”?为什么需要回溯?
3、不回溯可以吗?
首先介绍“回溯”算法的应用。“回溯”算法也叫“回溯搜索”算法,主要用于在一个庞大的空间里搜索我们所需要的问题的解。我们每天使用的“搜索引擎”就是帮助我们在庞大的互联网上搜索我们需要的信息。“搜索”引擎的“搜索”和“回溯搜索”算法的“搜索”意思是一样的。
“回溯”指的是“状态重置”,可以理解为“回到过去”、“恢复现场”,是在编码的过程中,是为了节约空间而使用的一种技巧。而回溯其实是“深度优先遍历”特有的一种现象。之所以是“深度优先遍历”,是因为我们要解决的问题通常是在一棵树上完成的,在这棵树上搜索需要的答案,一般使用深度优先遍历。
“全排列”就是一个非常经典的“回溯”算法的应用。我们知道,N 个数字的全排列一共有 N! 这么多个。
大家可以尝试一下在纸上写 3 个数字、4 个数字、5 个数字的全排列,相信不难找到这样的方法。
以数组 [1, 2, 3] 的全排列为例。
- 我们先写以 1 开头的全排列,它们是:
[1, 2, 3], [1, 3, 2]; - 再写以 2 开头的全排列,它们是:
[2, 1, 3], [2, 3, 1]; - 最后写以 3 开头的全排列,它们是:
[3, 1, 2], [3, 2, 1]。
我们只需要按顺序枚举每一位可能出现的情况,已经选择的数字在接下来要确定的数字中不能出现。按照这种策略选取就能够做到不重不漏,把可能的全排列都枚举出来。
- 在枚举第一位的时候,有 3 种情况。
- 在枚举第二位的时候,前面已经出现过的数字就不能再被选取了;
- 在枚举第三位的时候,前面 2 个已经选择过的数字就不能再被选取了。
这样的思路,我们可以用一个树形结构表示。看到这里的朋友,建议自己先尝试画一下“全排列”问题的树形结构。
使用编程的方法得到全排列,就是在这样的一个树形结构中进行编程,具体来说,就是执行一次深度优先遍历,从树的根结点到叶子结点形成的路径就是一个全排列。
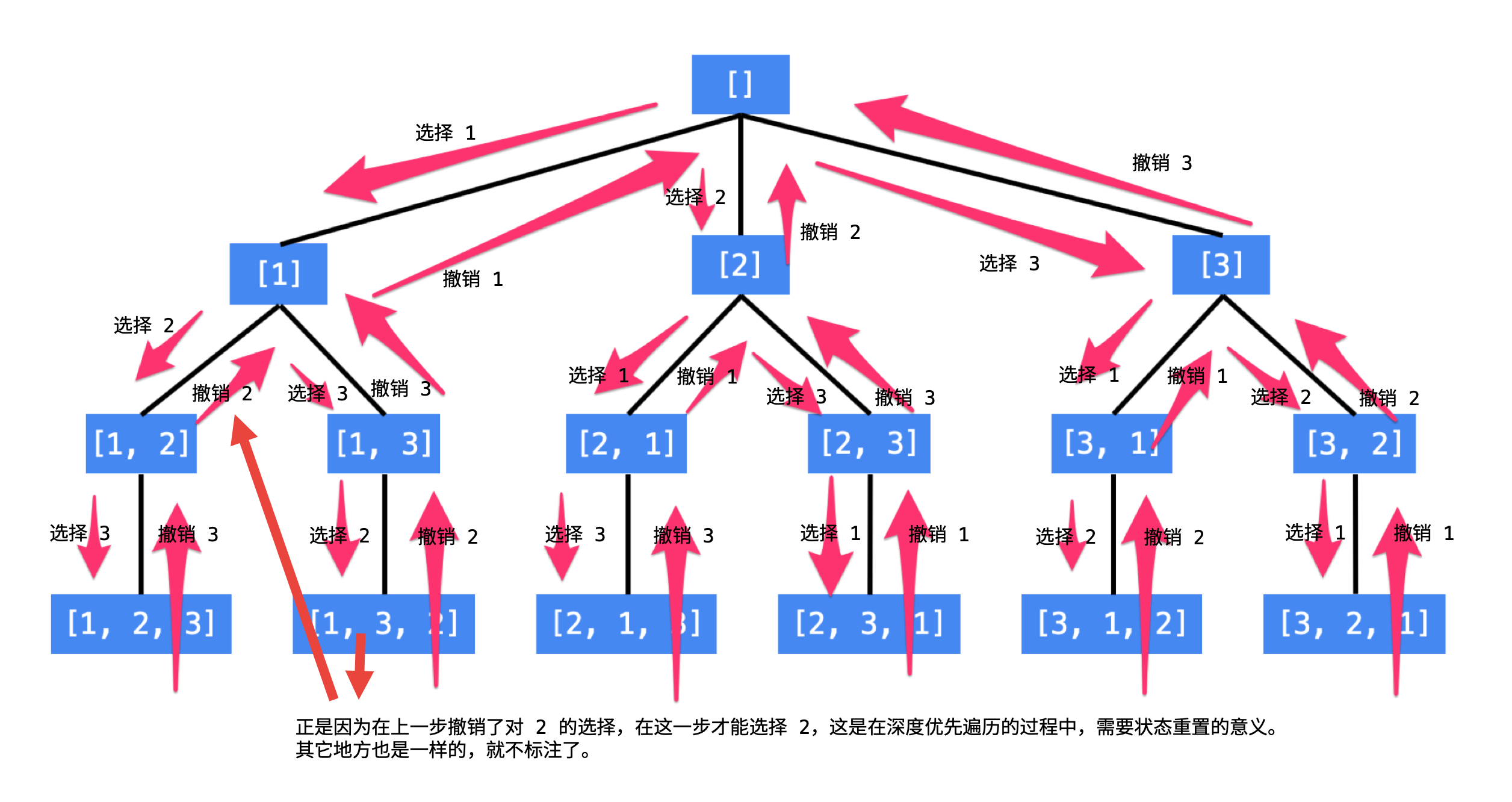
说明:
1、每一个结点表示了“全排列”问题求解的不同阶段,这些阶段通过变量的“不同的值”体现;
2、这些变量的不同的值,也称之为“状态”;
3、使用深度优先遍历有“回头”的过程,在“回头”以后,状态变量需要设置成为和先前一样;
4、因此在回到上一层结点的过程中,需要撤销上一次选择,这个操作也称之为“状态重置”;
5、深度优先遍历,可以直接借助系统栈空间,为我们保存所需要的状态变量,在编码中只需要注意遍历到相应的结点的时候,状态变量的值是正确的,具体的做法是:往下走一层的时候,path 变量在尾部追加,而往回走的时候,需要撤销上一次的选择,也是在尾部操作,因此 path 变量是一个栈。
6、深度优先遍历通过“回溯”操作,实现了全局使用一份状态变量的效果。
下面我们解释如何编码:
1、首先这棵树除了根结点和叶子结点以外,每一个结点做的事情其实是一样的,即在已经选了一些数的前提,我们需要在剩下还没有选择的数中按照顺序依次选择一个数,这显然是一个递归结构;
2、递归的终止条件是,数已经选够了,因此我们需要一个变量来表示当前递归到第几层,我们把这个变量叫做 depth;
3、这些结点实际上表示了搜索(查找)全排列问题的不同阶段,为了区分这些不同阶段,我们就需要一些变量来记录为了得到一个全排列,程序进行到哪一步了,在这里我们需要两个变量:
(1)已经选了哪些数,到叶子结点时候,这些已经选择的数就构成了一个全排列;
(2)一个布尔数组 used,初始化的时候都为 false 表示这些数还没有被选择,当我们选定一个数的时候,就将这个数组的相应位置设置为 true ,这样在考虑下一个位置的时候,就能够以 O(1) 的时间复杂度判断这个数是否被选择过,这是一种“以空间换时间”的思想。
我们把这两个变量称之为“状态变量”,它们表示了我们在求解一个问题的时候所处的阶段。
4、在非叶子结点处,产生不同的分支,这一操作的语义是:在还未选择的数中依次选择一个元素作为下一个位置的元素,这显然得通过一个循环实现。
5、另外,因为是执行深度优先遍历,从较深层的结点返回到较浅层结点的时候,需要做“状态重置”,即“回到过去”、“恢复现场”,我们举一个例子。
从 [1, 2, 3] 到 [1, 3, 2] ,深度优先遍历是这样做的,从 [1, 2, 3] 回到 [1, 2] 的时候,需要撤销刚刚已经选择的数 3,因为在这一层只有一个数 3 我们已经尝试过了,因此程序回到上一层,需要撤销对 2 的选择,好让后面的程序知道,选择 3 了以后还能够选择 2。
这种在遍历的过程中,从深层结点回到浅层结点的过程中所做的操作就叫“回溯”。
下面来看看代码应该如何编写:
参考代码 1:(注意:这个代码是错误的,希望读者能自己运行一下测试用例自己发现原因,然后再阅读后面的内容)
import java.util.ArrayList;
import java.util.List;
public class Solution {
public List<List<Integer>> permute(int[] nums) {
// 首先是特判
int len = nums.length;
// 使用一个动态数组保存所有可能的全排列
List<List<Integer>> res = new ArrayList<>();
if (len == 0) {
return res;
}
boolean[] used = new boolean[len];
List<Integer> path = new ArrayList<>();
dfs(nums, len, 0, path, used, res);
return res;
}
private void dfs(int[] nums, int len, int depth,
List<Integer> path, boolean[] used,
List<List<Integer>> res) {
if (depth == len) {
res.add(path);
return;
}
for (int i = 0; i < len; i++) {
if (!used[i]) {
path.add(nums[i]);
used[i] = true;
dfs(nums, len, depth + 1, path, used, res);
// 注意:这里是状态重置,是从深层结点回到浅层结点的过程,代码在形式上和递归之前是对称的
used[i] = false;
path.remove(path.size() - 1);
}
}
}
public static void main(String[] args) {
int[] nums = {1, 2, 3};
Solution solution = new Solution();
List<List<Integer>> lists = solution.permute(nums);
System.out.println(lists);
}
}
这段代码在运行的时候输出如下:
[[], [], [], [], [], []]
原因出现在递归终止条件这里:
if (depth == len) {
res.add(path);
return;
}
path 这个变量所指向的对象在递归的过程中只有一份,深度优先遍历完成以后,因为回到了根结点(因为我们之前说了,从深层结点回到浅层结点的时候,需要撤销之前的选择),因此 path 这个变量回到根结点以后都为空。
在 Java 中,因为都是值传递,对象类型变量在传参的过程中,复制的都是变量的地址。(Python 我不是很清楚 Python 中方法变量的传递机制,所以暂时没有写,欢迎知道的朋友补充,但是从实验的结果上看和 Java 很像。)这些地址被添加到 res 变量,但实际上指向的是同一块内存地址,因此我们会看到 6 个空的列表对象。解决的方法很简单,在 res.add(path); 这里做一次拷贝即可。
修改的部分:
if (depth == len) {
res.add(new ArrayList<>(path));
return;
}
此时再提交到「力扣」上就能得到一个 Accept 了。
复杂度分析:(这部分内容可以不掌握,增加学习负担,并且可能有错误,欢迎指处)。
回溯算法的时间复杂度一般都比较高,有些问题分析起来很复杂,我个人觉得没有必要掌握,而且剪枝剪得好的话,复杂度会降得很低,因此分析的最坏时间复杂度的意义也不是很大,视情况而定。
- 时间复杂度:O(N \times N!)O(N×N!)
(1) 非叶子结点的个数,依次为(按照层数来)
1+AN1+AN2+⋯+ANN−1=1+N!(N−1)!+N!(N−2)!+⋯+N!1 + A_N^1 + A_N^2 + \cdots + A_N^{N-1} = 1 + \cfrac{N!}{(N - 1)!} + \cfrac{N!}{(N - 2)!} + \cdots + N!1+AN1+AN2+⋯+ANN−1=1+(N−1)!N!+(N−2)!N!+⋯+N!
说明:根结点为 11,计算复杂度的时候忽略;A_N^1A**N1 表示排列数,计算公式为 Anm=n!(n−m)!A_n^m = \cfrac{n!}{(n - m)!}Anm=(n−m)!n!
在第 1 层,结点个数为 NN 个数选 1 个的排列,故为 AN1A_N^1AN1
在第 2 层,结点个数为 NN 个数选 2 个的排列,故为 AN2A_N^2AN2
N!(N−1)!+N!(N−2)!+⋯+N!=N!(1(N−1)!+1(N−2)!+⋯+1)≤N!(1+12+13+⋯+1N−1)<2\cfrac{N!}{(N - 1)!} + \cfrac{N!}{(N - 2)!} + \cdots + N! = N! \left( \cfrac{1}{(N - 1)!} + \cfrac{1}{(N - 2)!} + \cdots + 1 \right) \le N! \left( 1 + \cfrac{1}{2} + \cfrac{1}{3} + \cdots + \cfrac{1}{N - 1} \right) < 2(N−1)!N!+(N−2)!N!+⋯+N!=N!((N−1)!1+(N−2)!1+⋯+1)≤N!(1+21+31+⋯+N−11)<2
将常系数 22 视为 11,每个内部结点循环 NN 次,故非叶子结点的时间复杂度为 O(N×N!)O(N \times N!)O(N×N!)
(2) 最后一层共 N!个叶节点,在叶子结点处拷贝需要 O(N)O(N),叶子结点的时间复杂度也为 O(N×N!)O(N \times N!)O(N×N!)
- 空间复杂度:O(N×N!),O(N \times N!),O(N×N!),(1)递归树深度 logN\log NlogN;(2)全排列个数 N!,每个全排列占空间 N。取较大者。
希望大家能够通过这个例子理解“回溯”这个方法在搜索问题中起到的作用。
下面我们对这一版的代码做以下几个说明:
1、如果在每一个非叶子结点分支的尝试,我都创建新的变量表示状态,那么(1)在回到上一层结点的时候不需要“回溯”;(2)在递归终止的时候也不需要做拷贝。
这样的做法虽然可以得到解,但也会创建很多中间变量,这些中间变量很多时候是我们不需要的,会有一定空间和时间上的消耗。为了验证上面的说明,我们写如下代码进行实验:
参考代码 2:
import java.util.ArrayList;
import java.util.List;
public class Solution {
public List<List<Integer>> permute(int[] nums) {
// 首先是特判
int len = nums.length;
// 使用一个动态数组保存所有可能的全排列
List<List<Integer>> res = new ArrayList<>();
if (len == 0) {
return res;
}
boolean[] used = new boolean[len];
List<Integer> path = new ArrayList<>();
dfs(nums, len, 0, path, used, res);
return res;
}
private void dfs(int[] nums, int len, int depth,
List<Integer> path, boolean[] used,
List<List<Integer>> res) {
if (depth == len) {
// 3、不用拷贝,因为每一层传递下来的 path 变量都是新建的
res.add(path);
return;
}
for (int i = 0; i < len; i++) {
if (!used[i]) {
// 1、每一次尝试都创建新的变量表示当前的"状态"
List<Integer> newPath = new ArrayList<>(path);
newPath.add(nums[i]);
boolean[] newUsed = new boolean[len];
System.arraycopy(used, 0, newUsed, 0, len);
newUsed[i] = true;
dfs(nums, len, depth + 1, newPath, newUsed, res);
// 2、无需回溯
}
}
}
}
这就好比我们在实验室里做“对比实验”,每一个步骤的尝试都要保证使用的材料是一样的。我们有两种办法:
(1)每做完一种尝试,都把实验材料恢复成做上一个实验之前的样子,只有这样做出的对比才有意义;
(2)每一次尝试都使用同样的新的材料做实验。
在生活中做实验对材料有破坏性,这个过程通常不可逆。而在计算机的世界里,“恢复现场”和“回到过去”是相对容易的。
在一些字符串的“回溯”问题中,有时不需要回溯的原因是这样的:字符串变量在拼接的过程中会产生新的对象(针对 Java 和 Python 语言,其它语言我并不清楚)。
如果你使用 Python 语言,会知道有这样一种语法:[1, 2, 3] + [4] 也是创建了一个新的列表对象,我们已经在“参考代码 2”中展示这种写法。
2、也可以不使用 used 数组,在遍历的过程中,对于一个数是否使用过,就得遍历 path 里的每一个元素,这个操作的时间复杂度是 O(N),整体复杂度变大。一般情况下,没有必要节约这个空间。“全排列”问题还有一种经典的实现方式,是基于交换实现的,可以节约 used 数组,其他朋友写的题解中有这种做法,欢迎大家查看。
3、ArrayList 是 Java 中的动态数组,Java 建议我们如果一开始就知道这个集合里需要保存元素的大小,可以在初始化的时候直接传入。
在 res 变量初始化的时候,最好传入 len 的阶乘,让 ArrayList 在代码执行的过程中不发生扩容行为。同理,在 path 变量初始化的时候,最好传入 len,这个路径变量最长也就到 len 为止。
4、path 变量我们发现只是对它的末尾位置进行增加和删除的操作,显然它是一个栈,因此,使用栈语义会更清晰。但同时 Stack 这个类的文档我们,由于一些设计上的问题,建议我们使用:
- Java
Deque<Integer> stack = new ArrayDeque<Integer>();
这一点让我很奔溃,Deque 是双端队列,它提供了更灵活的接口,同时破坏了语义,一不小心,如果用错了接口,就会导致程序错误。我采用的做法是接受官方的建议,但是在程序变量命名和使用的接口时让语义清晰:
这里 path 我需要表示它是从根结点到叶子结点的路径,我认为这个语义更重要,因此不改名为 stack。而在末尾添加元素和删除元素的时候,分别使用 addLast() 和 removeLast() 方法这两个最直接的方法强调只在 path 变量的末尾操作。
5、布尔数组在这题里的作用是判断某个位置上的元素是否已经使用过。有两种等价的替换方式:
(1)哈希表;
(2)位掩码,即使用一个整数表示布尔数组。此时可以将空间复杂度降到 O(1)(不包括 path 变量和 res 变量和递归栈空间消耗)。
参考代码 3:
- Java
- Python
import java.util.ArrayDeque;
import java.util.ArrayList;
import java.util.Deque;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class Solution {
public List<List<Integer>> permute(int[] nums) {
int len = nums.length;
List<List<Integer>> res = new ArrayList<>(factorial(len));
if (len == 0) {
return res;
}
// 使用哈希表检测一个数字是否使用过
Set<Integer> used = new HashSet<>(len);
Deque<Integer> path = new ArrayDeque<>(len);
dfs(nums, len, 0, path, used, res);
return res;
}
private int factorial(int n) {
int res = 1;
for (int i = 2; i <= n; i++) {
res *= i;
}
return res;
}
private void dfs(int[] nums, int len, int depth,
Deque<Integer> path, Set<Integer> used,
List<List<Integer>> res) {
if (depth == len) {
res.add(new ArrayList<>(path));
return;
}
for (int i = 0; i < len; i++) {
if (!used.contains(i)) {
used.add(i);
path.addLast(nums[i]);
dfs(nums, len, depth + 1, path, used, res);
path.removeLast();
used.remove(i);
}
}
}
}
参考代码 4:
- Java
- Python
import java.util.ArrayDeque;
import java.util.ArrayList;
import java.util.Deque;
import java.util.List;
public class Solution {
public List<List<Integer>> permute(int[] nums) {
int len = nums.length;
List<List<Integer>> res = new ArrayList<>(factorial(len));
if (len == 0) {
return res;
}
int used = 0;
Deque<Integer> path = new ArrayDeque<>(len);
dfs(nums, len, 0, path, used, res);
return res;
}
private int factorial(int n) {
int res = 1;
for (int i = 2; i <= n; i++) {
res *= i;
}
return res;
}
private void dfs(int[] nums, int len, int depth,
Deque<Integer> path, int used,
List<List<Integer>> res) {
if (depth == len) {
res.add(new ArrayList<>(path));
return;
}
for (int i = 0; i < len; i++) {
if (((used >> i) & 1) == 0) {
path.addLast(nums[i]);
used ^= (1 << i);
dfs(nums, len, depth + 1, path, used, res);
used ^= (1 << i);
path.removeLast();
}
}
}
}
总结
下面回答在最开始提出的问题,其实我们上面的说明中也已经回答了。
1、为什么使用深度优先遍历?
(1)首先是正确性,只有遍历状态空间,才能得到所有符合条件的解;
(2)在深度优先遍历的时候,不同状态之间的切换很容易,可以再看一下上面有很多箭头的那张图,每两个状态之间的差别只有 1 处,因此回退非常方便,这样全局才能使用一份状态变量完成搜索;
(3)如果使用广度优先遍历,从浅层转到深层,状态的变化就很大,此时我们不得不在每一个状态都新建变量去保存它,从性能来说是不划算的;
(4)如果使用广度优先遍历就得使用队列,然后编写结点类。使用深度优先遍历,我们是直接使用了系统栈,系统栈帮助我们保存了每一个结点的状态信息。于是我们不用编写结点类,不必手动编写栈完成深度优先遍历。大家可以尝试使用广度优先遍历实现一下,就能体会到这一点。
2、不回溯可不可以?
可以。搜索问题的状态空间一般很大,如果每一个状态都去创建新的变量,时间复杂度是 O(N)。在候选数比较多的时候,在非叶子结点上创建新的状态变量的性能消耗就很严重。
就本题而言,只需要叶子结点的那个状态,在叶子结点执行拷贝,时间复杂度是 O(N)。路径变量在深度优先遍历的时候,结点之间的转换只需要 O(1)。
最后,由于回溯算法的时间复杂度很高,因此,如果在遍历的时候,如果能够提前知道这一条分支不能搜索到满意的结果,就可以提前结束,这一步操作称之为剪枝。
回溯算法会大量应用“剪枝”技巧达到以加快搜索速度。有些时候,需要做一些预处理工作(例如排序)才能达到剪枝的目的。预处理工作虽然也消耗时间,但一般而且能够剪枝节约的时间更多。还有正是因为回溯问题本身时间复杂度就很高,所以能用空间换时间就尽量使用空间。否则时间消耗又上去了。
下面提供一些我做过的“回溯”算法的问题,以便大家学习和理解“回溯”算法。
我做题的时候,第 1 步都是先画图,画图是非常重要的,只有画图才能帮助我们想清楚递归结构,想清楚如何剪枝。就拿题目中的示例,想一想人手动操作是怎么做的,一般这样下来,这棵递归树都不难画出。
即在画图的过程中思考清楚:
1、分支如何产生;
2、题目需要的解在哪里?是在叶子结点、还是在非叶子结点、还是在从跟结点到叶子结点的路径?
3、哪些搜索是会产生不需要的解的?例如:产生重复是什么原因,如果在浅层就知道这个分支不能产生需要的结果,应该提前剪枝,剪枝的条件是什么,代码怎么写?
| 题目 | 提示 |
|---|---|
| 47. 全排列 II | 思考一下,为什么造成了重复,如何在搜索之前就判断这一支会产生重复,从而“剪枝”。 |
| 17 .电话号码的字母组合 | |
| 22. 括号生成 | 这是字符串问题,没有显式回溯的过程。这道题广度优先遍历也很好写,可以通过这个问题理解一下为什么回溯算法都是深度优先遍历,并且都用递归来写。 |
| 39. 组合总和 | 使用题目给的示例,画图分析。 |
| 40. 组合总和 II | |
| 51. N皇后 | 其实就是全排列问题,注意设计清楚状态变量。 |
| 60. 第k个排列 | 利用了剪枝的思想,减去了大量枝叶,直接来到需要的叶子结点。 |
| 77. 组合 | 组合问题按顺序找,就不会重复。并且举一个中等规模的例子,找到如何剪枝,这道题思想不难,难在编码。 |
| 78. 子集 | 为数不多的,解不在叶子结点上的回溯搜索问题。解法比较多,注意对比。 |
| 90. 子集 II | 剪枝技巧同 47 题、39 题、40 题。 |
| 93. 复原IP地址 | |
| 77. 组合 | 组合问题按顺序找,就不会重复。并且举一个中等规模的例子,找到如何剪枝,这道题思想不难,难在编码。 |
| 78. 子集 | 为数不多的,解不在叶子结点上的回溯搜索问题。解法比较多,注意对比。 |
| 90. 子集 II | 剪枝技巧同 47 题、39 题、40 题。 |
| 93. 复原IP地址 | |
| 784. 字母大小写全排列 |

100. 相同的树,98. 验证二叉搜索树,28. 对称的二叉树")
141.环形链表I,142.环形链表II")

还没有评论,来说两句吧...