

概述
继续跟中华石杉老师学习ES,第47篇
课程地址: https://www.roncoo.com/view/55
官方说明
Cardinality Aggregation:戳这里
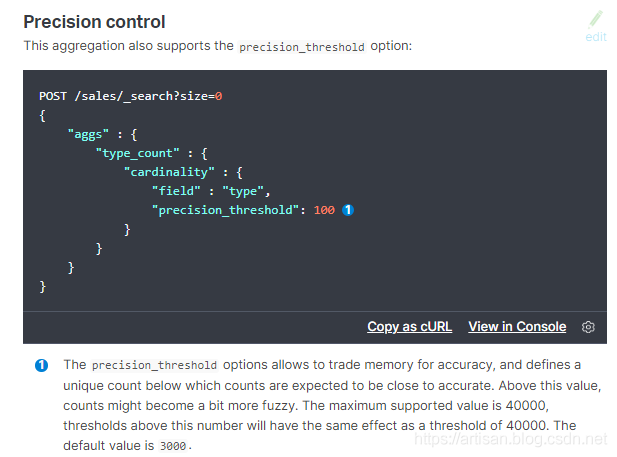
precision_threshold优化准确率和内存开销
原始数据:
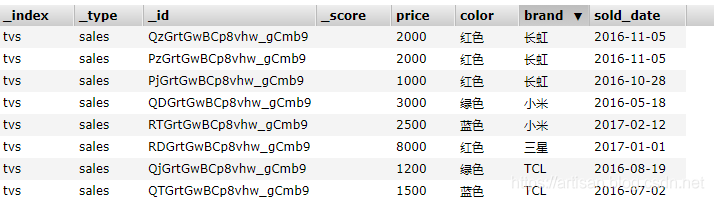
统计下有多少个不同的品牌
DSL:
GET /tvs/sales/_search
{
"size" : 0,
"aggs" : {
"distinct_brand" : {
"cardinality" : {
"field" : "brand",
"precision_threshold" : 100
}
}
}
}
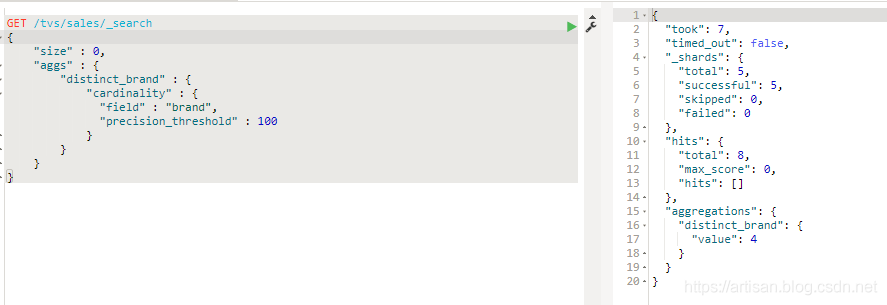
注意下 "precision_threshold" : 100 的意思是: brand去重,如果brand的unique value,在100个以内,小米,长虹,三星,TCL,HTL。。。 在多少个unique value以内,cardinality,几乎保证100%准确 。
cardinality算法,会占用precision_threshold * 8 byte 内存消耗,100 * 8 = 800个字节 占用内存很小。。。而且unique value如果的确在值以内,那么可以确保100%准确
precision_threshold,值设置的越大,占用内存越大, 假设设置 1000,那么1000 * 8 = 8000 / 1000 = 8KB,可以确保更多unique value的场景下,100%的准确
field,去重,count,这时候,unique value,10000, precision_threshold=10000,10000 * 8 = 80000个byte,80KB
HyperLogLog++ (HLL)算法性能优化
cardinality底层算法:HLL算法,HLL算法的性能会对所有的uqniue value取hash值,通过hash值近似去求distcint count,存在误差 .
默认情况下,发送一个cardinality请求的时候,会动态地对所有的field value,取hash值;

优化的话: 将取hash值的操作,前移到建立索引的时候 ,如下
PUT /tvs/
{
"mappings": {
"sales": {
"properties": {
"brand": {
"type": "text",
"fields": {
"hash": {
"type": "murmur3"
}
}
}
}
}
}
}
这样在执行同样的查询的话,就不会在请求的时候执行hash值了。
GET /tvs/sales/_search
{
"size" : 0,
"aggs" : {
"distinct_brand" : {
"cardinality" : {
"field" : "brand.hash",
"precision_threshold" : 100
}
}
}
}




还没有评论,来说两句吧...