
消息是kafka中最基本的数据单元,在kafka中一条消息由以下三部分构成:
- topic:消息属于哪个消息集合
- value:消息具体内容
- key:与分区算法一起决定当前消息发送到那个partition
消息在 kafka-client 的具体实现就是 ProducerRecord 类,下面是它的构造函数: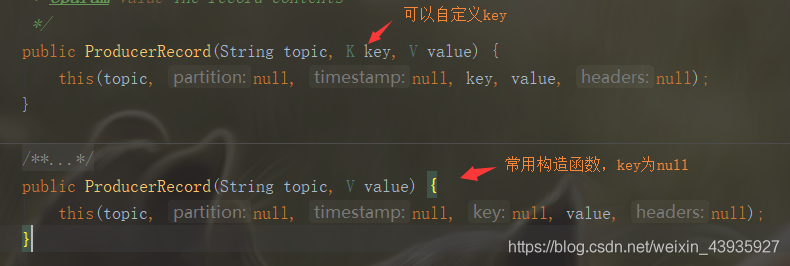
1.默认分发规则
默认情况下,kafka采用的是hash取模的分区算法。
- key不为null:就直接根据分区数取模
- key为null:则会随机分配一个分区。这个随机是在这个参数”metadata.max.age.ms”的时间范围内随机选择一个。对于这个时间段内,如果key为 null,则只会发送到唯一的分区。这个值默认情况下是10分钟更新一次。
关于Metadata,简单理解就是Topic/Partition和broker的映射关系,每一个topic的每一个partition,需要知道对应的broker列表是什么,leader是谁、follower是谁。这些信息都是存储在Metadata这个类里面。
2.自定义分发
1). 自定义分区规则,实现Partitioner接口
public class MyPartition implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[]
valueBytes, Cluster cluster) {
// 通过集群cluster获取当前topic的所有分区信息
List<PartitionInfo> partitionInfos = cluster.partitionsForTopic(topic);
// 获取分区数
int numOfPartition = partitionInfos.size();
int partitionNum = 0;
// 如果没有传入key,就随机分配
if (key == null) {
partitionNum = new Random().nextInt(numOfPartition);
} else { // 否则通过key取模得到分区
partitionNum = Math.abs(key.hashCode()) % numOfPartition;
}
// 返回分区值
return partitionNum;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
2). 在Producer添加分区策略配置(全类名)
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "com.xupt.yzh.testkafka.MyPartition")
本文标题:【Kafka】原理分析:Producer分发规则
本文链接:https://blog.quwenai.cn/post/9981.html
版权声明:本文不使用任何协议授权,您可以任何形式自由转载或使用。




还没有评论,来说两句吧...