
1>> 从MySQL的架构上看
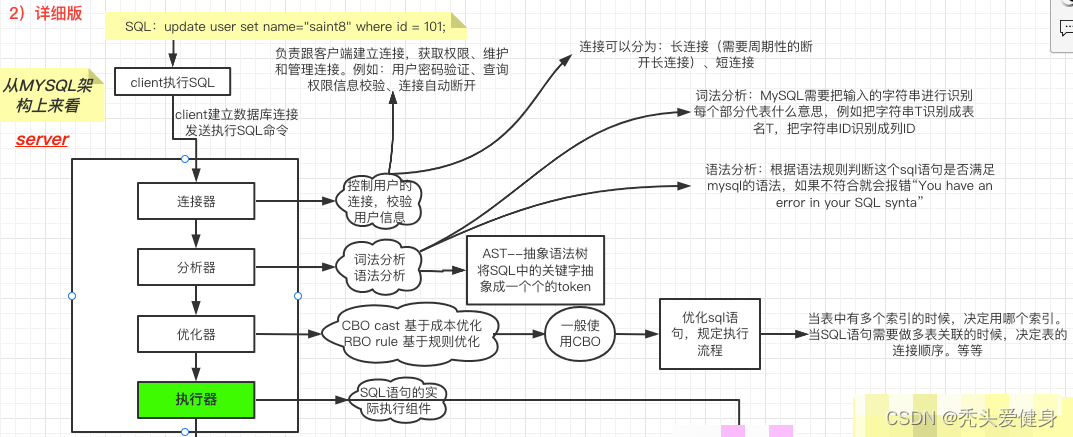
- client建立数据库连接,发送执行SQL命令到MySQL-Server的连接器;
- 连接器负责跟客户端建立连接,获取权限、维护和管理连接。
- 例如:用户密码验证、查询权限信息校验、连接自动断开
- 查询缓存;key 为 SQL 语句,value 为查询结果,如果查到就直接返回。
- 不建议使用次缓存,在 MySQL 8.0 版本已经将查询缓存删除,也就是说 MySQL 8.0 版本后不存在此功能。
- 分析器;分为词法分析和语法分析;核心在于:AST–抽象语法树将SQL中的关键字抽象成一个个的token;一般语法错误在此阶段;
- 词法分析:MySQL需要把输入的字符串进行识别/解析,每个部分代表什么意思,例如把字符串T识别成表名T,把字符串ID识别成列ID。
- 语法分析:根据语法规则判断这个sql语句是否满足mysql的语法,如果不符合就会报错“You have an error in your SQL synta”。
- 优化器;分两种优化:
- CBO cast 基于成本优化
- RBO rule 基于规则优化
- 一般使用CBO,优化sql语句,规定执行流程;
- 当表中有多个索引的时候,决定用哪个索引。
- 当SQL语句需要做多表关联(join)的时候,决定表的连接顺序等等
- 执行器;前面通过分析器解析出SQL要干嘛,通过优化器知道该怎么做;到这里开始真正执行SQL语句;
2>> 真正的执行SQL语句操作
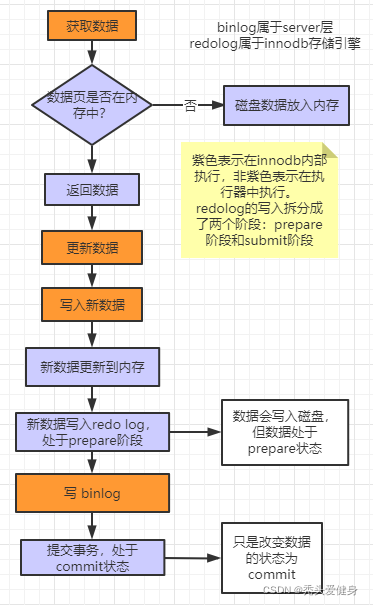
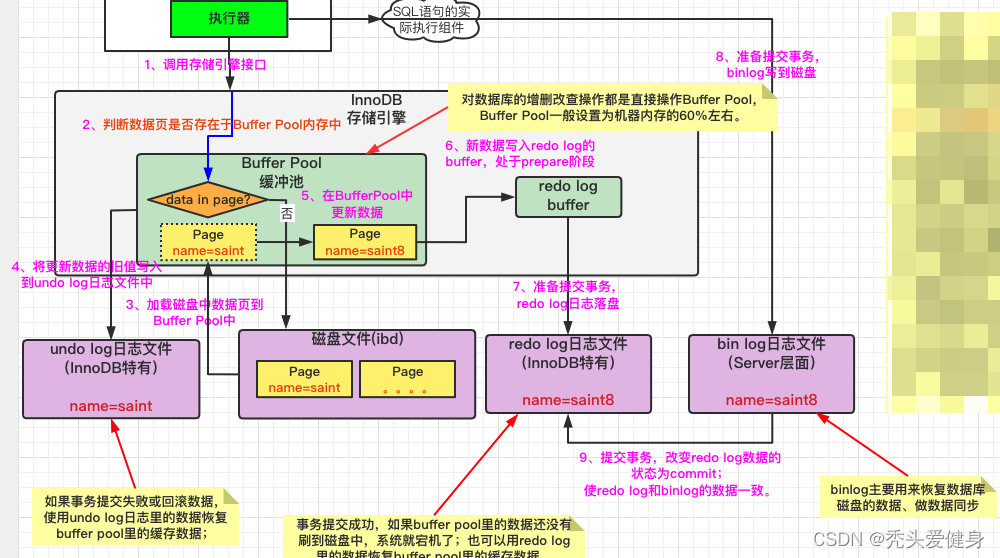
具体流程如下:
-
执行器调用存储引擎接口;
-
判断数据页是否存在于Buffer Pool内存中。
对数据库的增删改查操作都是直接操作Buffer Pool,Buffer Pool一般设置为机器内存的60%左右。 -
如果数据页不在BufferPool内存中,则调用存储引擎的接口从磁盘文件中取数据,然后将其缓存到buffer Pool中。
-
存储引擎将要更新数据的旧值写入到undo log磁盘文件;
- 如果事务提交失败或回滚数据,使用undo log日志里的数据恢复buffer pool里的缓存数据;
-
执行器更新数据,并调用存储引擎将新数据写入Buffer Pool中;
-
接着存储引擎将新数据写入redo log buffer中,此时处于prepare阶段;
-
准备提交事务时,将redo log buffer中的redo log刷到磁盘中;
-
执行器将数据对应的binlog写入到磁盘;
- binlog主要用来恢复数据库磁盘的数据、做主从数据同步;
-
提交事务,改变磁盘中redo log数据的状态为commit;使redo log和binlog的数据一致;
- 事务提交成功,如果buffer pool里的数据还没有刷到磁盘中,系统就宕机了;也可以用redo log里的数据恢复buffer pool里的缓存数据。
3>> 最后,update又分两种情况
-
不更新主键
这其中又分为两种情况:
- old_value和new_value的空间长度一样,复用空间
- old_value空间长度 <> new_value空间长度
- 先删除内存空间占用
- 申请新的内存空间,页空间也不足的话,会进行
页分裂。
-
更新主键
- 第一步先delete。
- 第二步将更新后的每列的值创建为一个新的记录并插入。
本文标题:居然可以这样聊MySQL的数据更新流程(update)
本文链接:https://blog.quwenai.cn/post/9590.html
版权声明:本文不使用任何协议授权,您可以任何形式自由转载或使用。
:Tomcat 打破双亲委派")



还没有评论,来说两句吧...