
消息存储是RocketMQ中最为复杂和最为重要的一部分,本文会简单介绍下RocketMQ的消息存储整体架构、以及发送一条消息时的基本存储流程
整体架构
存储文件介绍
消息存储的架构设计中,有3个重要的存储文件,分别是CommitLog、ConsumeQueue、IndexFile
分别展开说明下
- CommitLog: CommitLog是存储消息内容的存储主体,Producer发送的消息都会顺序写入CommitLog文件。由于需要存储的消息随着时间推移会变得很大,因此CommitLog将日志做了拆分,每个CommitLog文件大小为1G,文件名(长度20位,左边补0)为该文件中的消息起始偏移量,比如第一个CommitLog起始偏移量为0,其文件名为(00000000000000000000),1G=1073741824,故第二个文件的起始偏移量为1073741824,文件名为00000000001073741824。
commitLog文件存储路径为$HOME/store/commitLog,如图所示
2. ConsumeQueue:ConsumeQueue(逻辑消费队列)是消息消费队列,由于CommitLog中为了消息的存储性能考虑,所有消息都是顺序写入的(即不同Topic的消息混淆存储),但Consumer消费端又是根据Topic来订阅消费消息,如果要根据Topic来订阅消息,势必遍历CommitLog中存储的消息来过滤Topic,这种方式的性能是非常差的。因此MQ中设计了ConsumeQueue来提高消息消费性能,consumequeue文件可以看成是基于topic的commitlog索引文件。即每个Topic下的每个queueId对应一个Consumequeue,其中存储了消息对应在CommitLog文件中的物理偏移量offset,消息大小size,消息Tag的hash值
ConsumeQueue文件的存储路径为$HOME/store/consumequeue,其下文件夹组织方式为topic/queueId/consumequeue文件
先看第一层topic
第二层存储某个topic下的queueId
在queueId下才是具体的consumequeue文件
对应到代码里的数据结构就是
private final ConcurrentMap<String/* topic */, ConcurrentMap<Integer/* queueId */, ConsumeQueue>> consumeQueueTable;
- IndexFile:顾名思义,IndexFile是索引文件,其提供了根据消息的key值,时间区间来快速检索消息的方法。底层是HashMap的文件索引实现。IndexFile的名称是创建时间的时间戳,存储路径为$HOME/store/index,如下图所示

设计思路
介绍完消息存储中的3个关键存储文件后,引用官方的一张设计图来说明下MQ的存储设计思路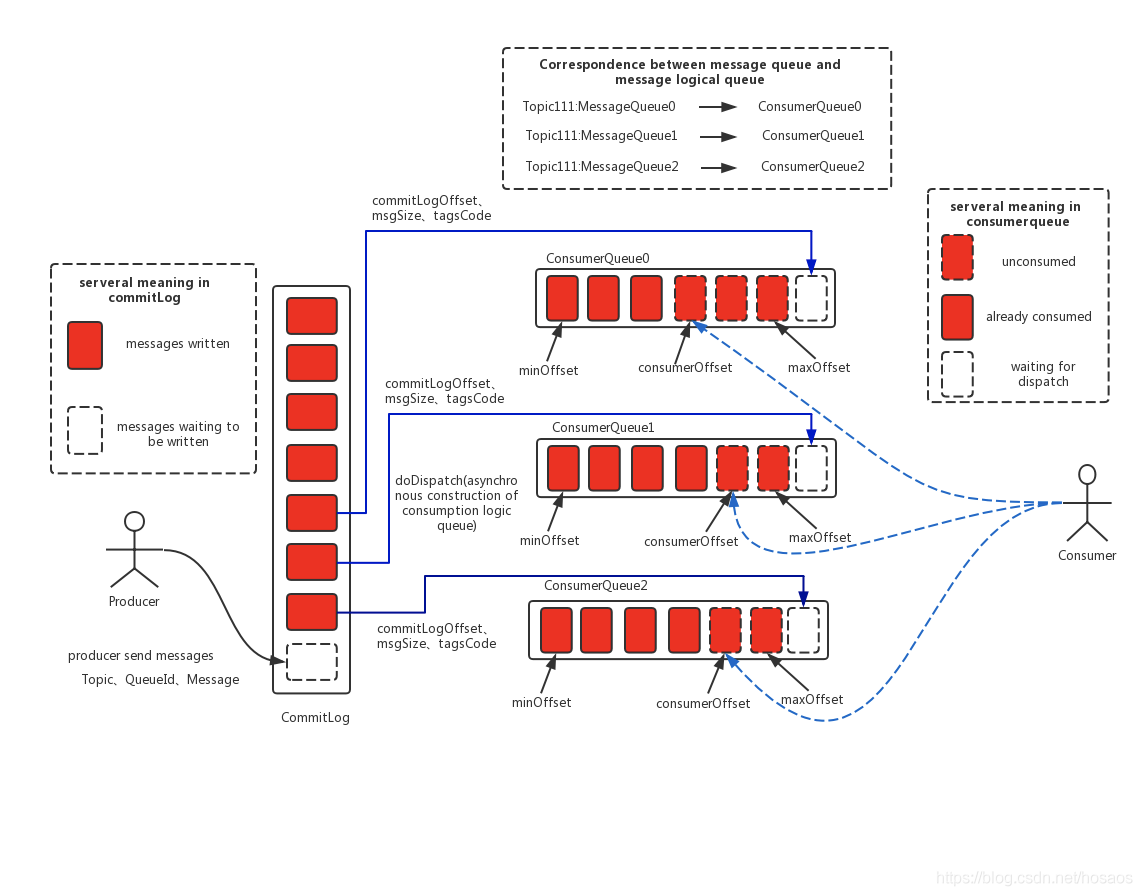
下面简单介绍下这张架构图中的几个关键设计思路
- 单个Broker实例中,所有的队列共享一个CommitLog文件,即所有消息顺序写入CommitLog文件
- 通过CommitLogDispatcher.dispatch方法异步分发请求并构建出ComsumerQueue文件和IndexFile文件
存储流程
写入MappedFile
Producer端将消息发送到Broker端后,会调用CommitLog#putMessage方法对消息进行持久化存储
先看下这个方法里都有啥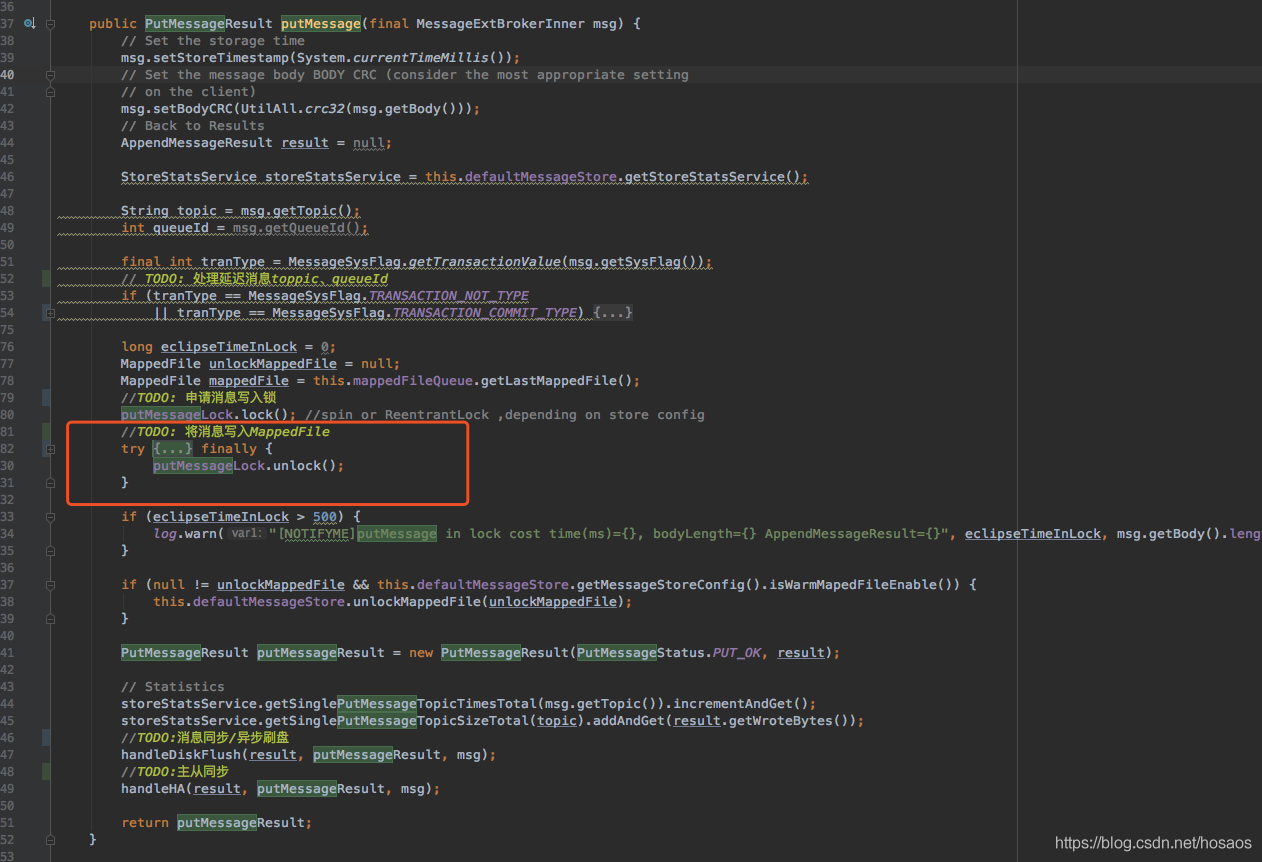
针对我代码中TODO黄色注释部分,这里分开详细说明
- 处理延迟消息toppic、queueId
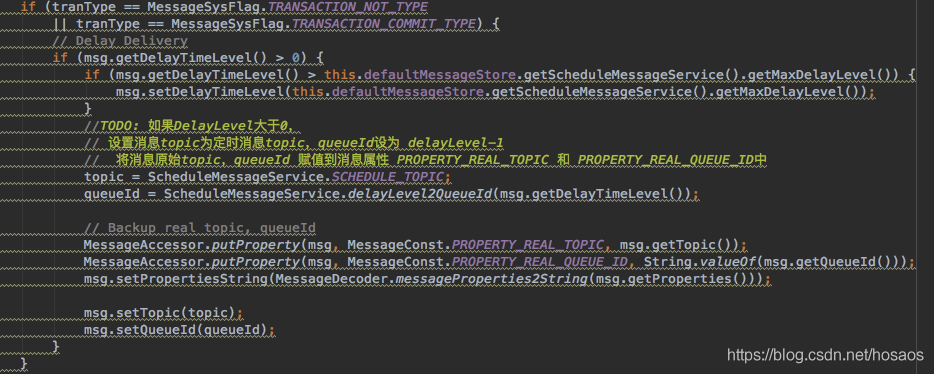
延迟消息之所以不会被立马消费,就是因为消息存储时其原有topic,queueId被存储起来,同时修改其topic为”SCHEDULE_TOPIC_XXXX“。 - putMessageLock申请消息写入锁
broker端消息顺序写入CommitLog,因此通过加锁来同步保证消息写入顺序
putMessageLock有两个实现
第一个是基于ReentrantLock实现的重入锁
第二个则是基于Atomic原子类中的CAS操作实现的自旋锁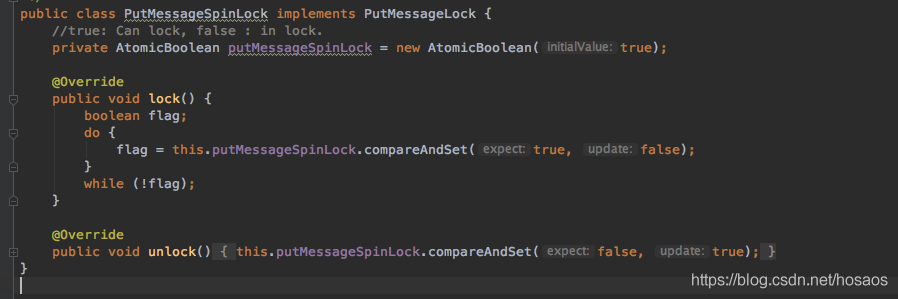
- 将消息写入MappedFile
先明确一点,什么是MappedFile,前面介绍CommitLog文件存储时介绍到,实际文件系统中CommitLog是分成了1个个定长的子文件的。MappedFile就可以理解为这些定长子文件在内存中的映射。MappedFile内部持有NIO中的MappedByteBuffer对文件进行读写操作,将对文件的操作转化为内存地址进行操作,提高了文件读写效率(因为需要使用内存映射机制,因此CommitLog文件采用定长结构存储,方便将文件映射到内存)
MappedFile类中关键字段如下
//文件写指针
protected final AtomicInteger wrotePosition = new AtomicInteger(0);
//ADD BY ChenYang
//文件提交指针
protected final AtomicInteger committedPosition = new AtomicInteger(0);
//文件flush指针
private final AtomicInteger flushedPosition = new AtomicInteger(0);
//文件大小
protected int fileSize;
//NIO文件通道
protected FileChannel fileChannel;
//堆内存
protected ByteBuffer writeBuffer = null;
//堆内存池
protected TransientStorePool transientStorePool = null;
//文件名称
private String fileName;
//物理文件对应的内存映射
private MappedByteBuffer mappedByteBuffer;
回到文中代码,看下try方法中的写入MappedFile的实现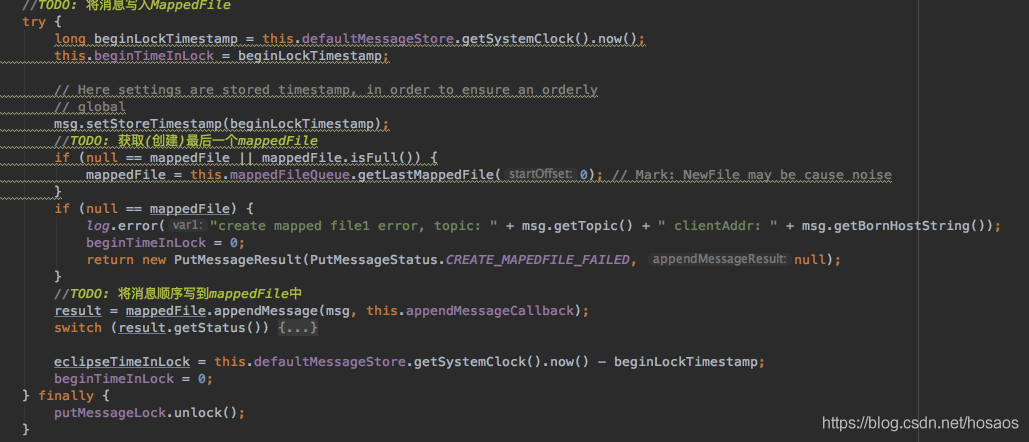
首先尝试获取最新的一个mappedFile,如果没有mappedFile,则新建一个mappedFile。
然后调用mappedFile.appendMessage方法顺序追加消息
消息刷盘

handleDiskFlush方法即为刷盘的具体实现,这里不具体展开
消息写到MappedFile中时,实际还留存在Java内存中,因此需要将消息持久化(刷盘)到文件系统中,消息刷盘分为同步、异步两种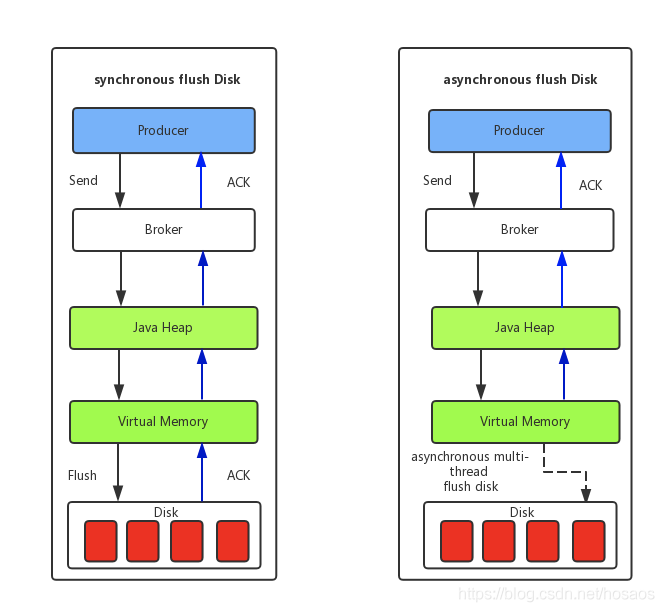
(1) 同步刷盘:如上图所示,只有在消息真正持久化至磁盘后RocketMQ的Broker端才会真正返回给Producer端一个成功的ACK响应。同步刷盘对MQ消息可靠性来说是一种不错的保障,但是性能上会有较大影响,一般适用于金融业务应用该模式较多。
(2) 异步刷盘:能够充分利用OS的PageCache的优势,只要消息写入PageCache即可将成功的ACK返回给Producer端。消息刷盘采用后台异步线程提交的方式进行,降低了读写延迟,提高了MQ的性能和吞吐量,但可能会丢失部分消息。
主从同步
刷盘完成后,消息完成了在单点Broker上的持久化。但是从高可用角度讲,消息持久化在一个Broker节点中并不满足高可用的要求。
RocketMq中针对消息高可用的实现,有如下方案
- 多Master多Slave模式-异步复制
每个Master配置一个Slave,有多对Master-Slave,HA采用异步复制方式,主备有短暂消息延迟(毫秒级)
- 优点:即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,同时Master宕机后,消费者仍然可以从Slave消费,而且此过程对应用透明,不需要人工干预,性能同多Master模式几乎一样;
- 缺点:Master宕机,磁盘损坏情况下会丢失少量消息。
默认RocketMq的实现方案即为异步复制,客户端启动HAclient以每隔5s的间隔时间向Master服务端拉取消息,代码实现在HAService中
- 多Master多Slave模式-同步双写
每个Master配置一个Slave,有多对Master-Slave,HA采用同步双写方式,即只有主备都写成功,才向应用返回成功,这种模式的优缺点如下:
- 优点:数据与服务都无单点故障,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高;
- 性能比异步复制模式略低(大约低10%左右),发送单个消息的RT会略高,且目前版本在主节点宕机后,备机不能自动切换为主机。

handleHA方法即为同步双写的实现方法
")

")

还没有评论,来说两句吧...