

CREATE TABLE `staff` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`name` varchar(64) NOT NULL COMMENT '姓名',
`age` int(4) NOT NULL COMMENT '年龄',
`city` varchar(64) NOT NULL COMMENT '城市',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8 COMMENT='员工表';
explain select city ,count(*) as num from staff group by city;

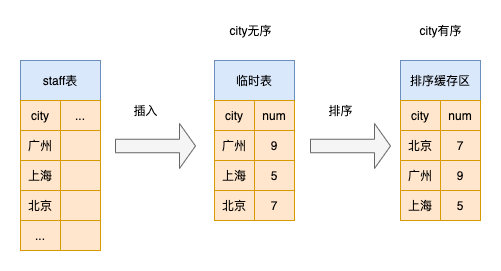
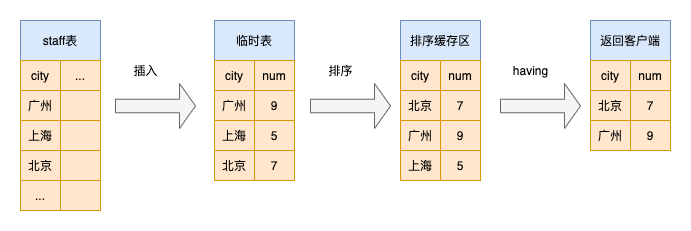
group by 优化
order by null 不排序
explain select city ,count(*) as num from staff group by city order by null

只有Using temporary 没有 Using filesort,说明没有进行排序
分组字段加索引
alter table staff add index idx_city(city)
explain select city ,count(*) as num from staff group by city

Using index,表明索引覆盖,type为inde,表明遍历了索引idx_city
Using temporary 和 Using filesort 全都没有了
DROP INDEX idx_city ON staff
尽量使用内存临时表
使用SQL_BIG_RESULT
explain select SQL_BIG_RESULT city ,count(*) as num from staff group by city

参考博客
[1]https://mp.weixin.qq.com/s/EybebcYX4i13r5nDRG14fg
[2]https://juejin.cn/post/7053966777088213005
本文标题:MySQL实战:group by 语句怎么优化?
本文链接:https://blog.quwenai.cn/post/9038.html
版权声明:本文不使用任何协议授权,您可以任何形式自由转载或使用。

:支持的数据类型")
:常用 SQL 语句大全")
:几条运行监控命令")
还没有评论,来说两句吧...