
介绍
极简计算机发展史
我们知道,计算机CPU和内存的交互是最频繁的,内存是我们的高速缓存区。而刚开始用户磁盘和CPU进行交互,CPU运转速度越来越快,磁盘远远跟不上CPU的读写速度,才设计了内存,但是随着CPU的发展,内存的读写速度也远远跟不上CPU的读写速度,因此,为了解决这一矛盾,CPU厂商在每颗CPU上加入了高速缓存,用来缓解这种症状,因此,现在CPU同内存交互就变成了下面的样子。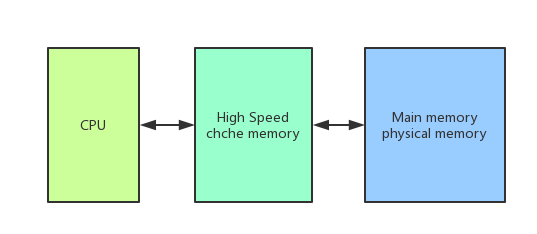
单核CPU的性能不可能无限制的增长,要想很多的提升新能,需要多个处理器协同工作。 基于高速缓存的存储交互很好的解决了处理器与内存之间的矛盾,也引入了新的问题:缓存一致性问题。在多处理器系统中,每个处理器有自己的高速缓存,而他们又共享同一块内存(下文成主存,main memory 主要内存),当多个处理器运算都涉及到同一块内存区域的时候,就有可能发生缓存不一致的现象。为了解决这一问题,需要各个处理器运行时都遵循一些协议,在运行时需要用这些协议保证数据的一致性。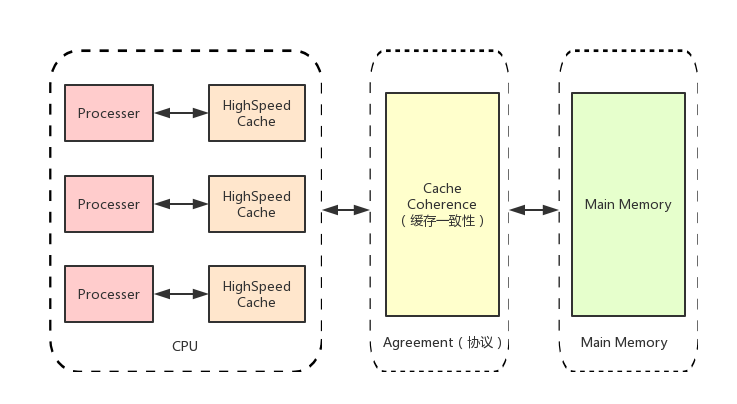
缓存一致性协议中最出名的就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存设置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中该变量是无效状态,那么它就会从内存重新读取
Java内存模型的抽象结构
Java的内存模型和上面的结构还是挺相似的,此时在看工作内存和主内存关系,从逻辑上,高速缓存对应工作内存,每个线程分配到CPU时间片时,独自享有高速缓存的使用能力。主内存对应存储的物理内存。特别注意,这只是逻辑上的对等关系,物理的上具体对应关系十分复杂,这里不讨论。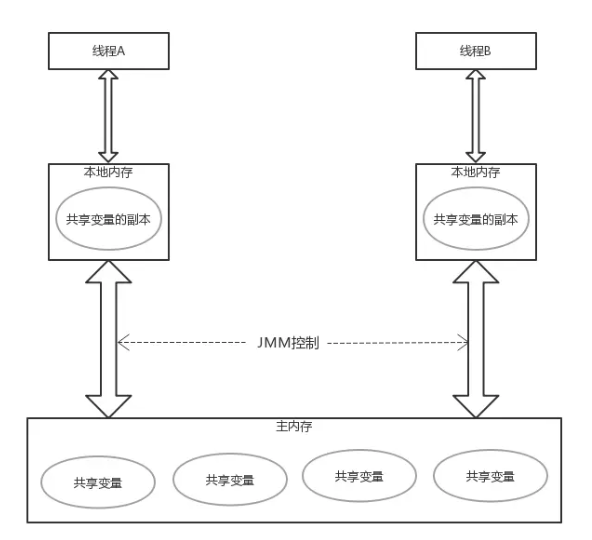
在java中,共享变量是指所有存储在堆内存中的实例字段,静态字段和数组对象元素,因为堆内存是所有线程共享的数据区。而局部变量,方法定义参数,异常处理参数不会在线程之间共享,它们不存在内存可见性问题,也不会受到Java内存模型的影响。
从上图来看,如果线程A和线程B之间要通信的话,必须要经历下面的两个过程:
1.线程A把本地内存A中更新过的共享变量刷新到主内存中去。
2.线程B到主内存中去读取线程A之前已更新过的共享变量。
示意图如下: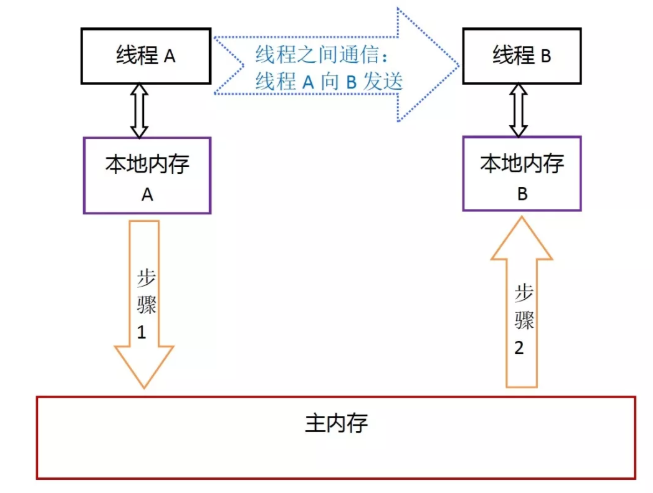
本地内存 A 和 B 有主内存共享变量 X 的副本。假设一开始时,这三个内存中 X 的值都是 0。线程 A 正执行时,把更新后的 X 值(假设为 1)临时存放在自己的本地内存 A 中。当线程 A 和 B 需要通信时,线程 A 首先会把自己本地内存 A 中修改后的 X 值刷新到主内存去,此时主内存中的 X 值变为了 1。随后,线程 B 到主内存中读取线程 A 更新后的共享变量 X 的值,此时线程 B 的本地内存的 X 值也变成了 1。
整体来看,这两个步骤实质上是线程 A 再向线程 B 发送消息,而这个通信过程必须经过主内存。JMM 通过控制主内存与每个线程的本地内存之间的交互,来为 Java 程序员提供内存可见性保证。
Java内存模型中的重排序
Java内存模型中的内存屏障
为了保证内存可见性,Java 编译器在生成指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序。JMM 把内存屏障指令分为下列四类:
参考博客
[1]https://juejin.im/post/5d6d2429f265da03b638c728
[2]https://mp.weixin.qq.com/s/y0jwjxo4k_8yok9D9qC21g



.getHostAddress()获取到的IP地址为127.0.0.1,解决措施。")
还没有评论,来说两句吧...