
139. 单词拆分
难度中等
给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。
说明:
- 拆分时可以重复使用字典中的单词。
- 你可以假设字典中没有重复的单词。
示例 1:
输入: s = "leetcode", wordDict = ["leet", "code"]
输出: true
解释: 返回 true 因为 "leetcode" 可以被拆分成 "leet code"。
示例 2:
输入: s = "applepenapple", wordDict = ["apple", "pen"]
输出: true
解释: 返回 true 因为 "applepenapple" 可以被拆分成 "apple pen apple"。
注意你可以重复使用字典中的单词。
示例 3:
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"]
输出: false
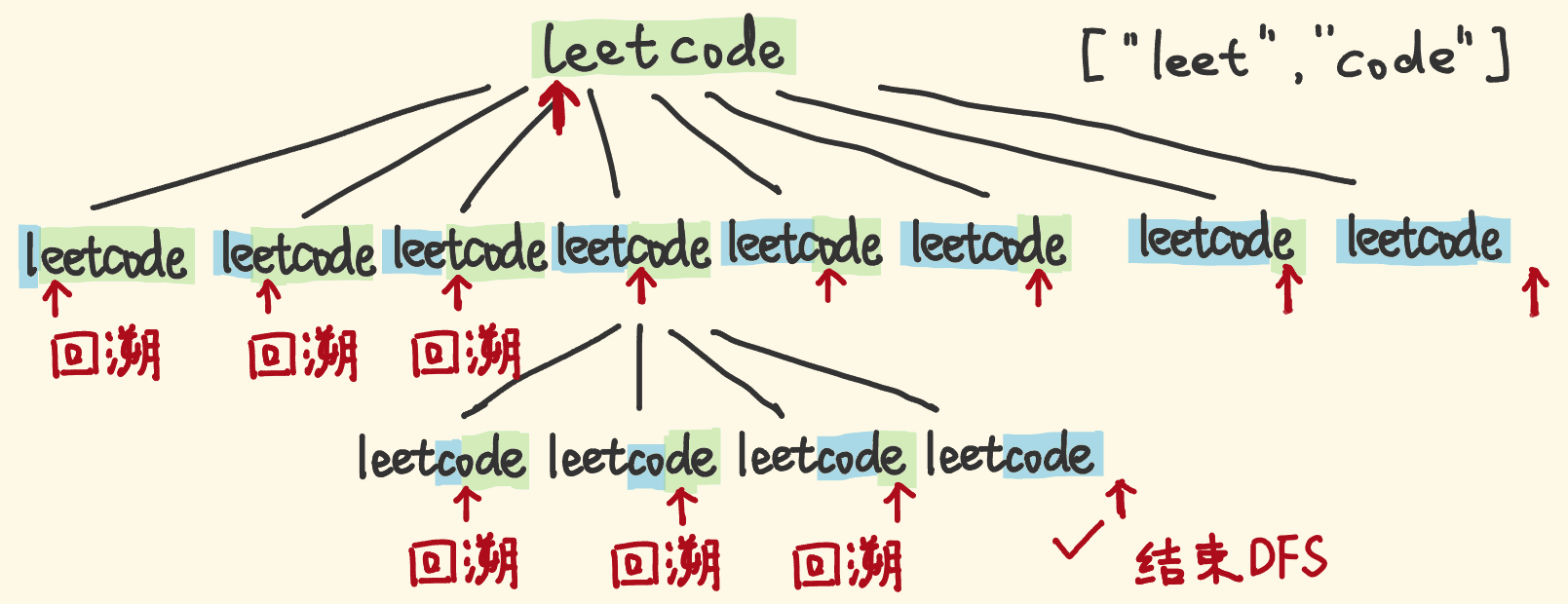
DFS 思路
- "leetcode"能否break,可以拆分为:"l"是否是单词表的单词、剩余子串能否break,"le"是否是单词表的单词、剩余子串能否break……
- 用 DFS 回溯,考察所有的拆分可能,指针从左往右扫描 s 串:
- 如果指针的左侧部分,是单词表中的单词,则对以指针为开头的剩余子串,递归考察。
- 如果指针的左侧部分,不是单词表的单词,不用看了,回溯,考察别的分支。
DFS 代码 超时
通过23/36个用例,遇到这个测试用例超时了:
"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaab,[“a”,“aa”,“aaa”,“aaaa”,“aaaaa”,“aaaaaa”,“aaaaaaa”,“aaaaaaaa”,“aaaaaaaaa”,“aaaaaaaaaa”]
const wordBreak = (s, wordDict) => {
const wordSet = new Set(wordDict);
const check = (s, wordSet, start) => { // 检查从start开始的子串能否break
// 指针越界,结束递归
if (start == s.length) return true;
for (let end = start + 1; end <= s.length; end++) {
// end指针划分两部分,word是前缀部分
const word = s.slice(start, end);
// 如果前缀部分是单词表的词,且剩余子串能break,则返回true
if (wordSet.has(word) && check(s, wordSet, end)) return true;
}
// end指针怎么划分都没返回true,则返回false
return false;
};
return check(s, wordSet, 0);
};
给递归增加记忆化
- 下面这个例子中,做了大量重复计算:
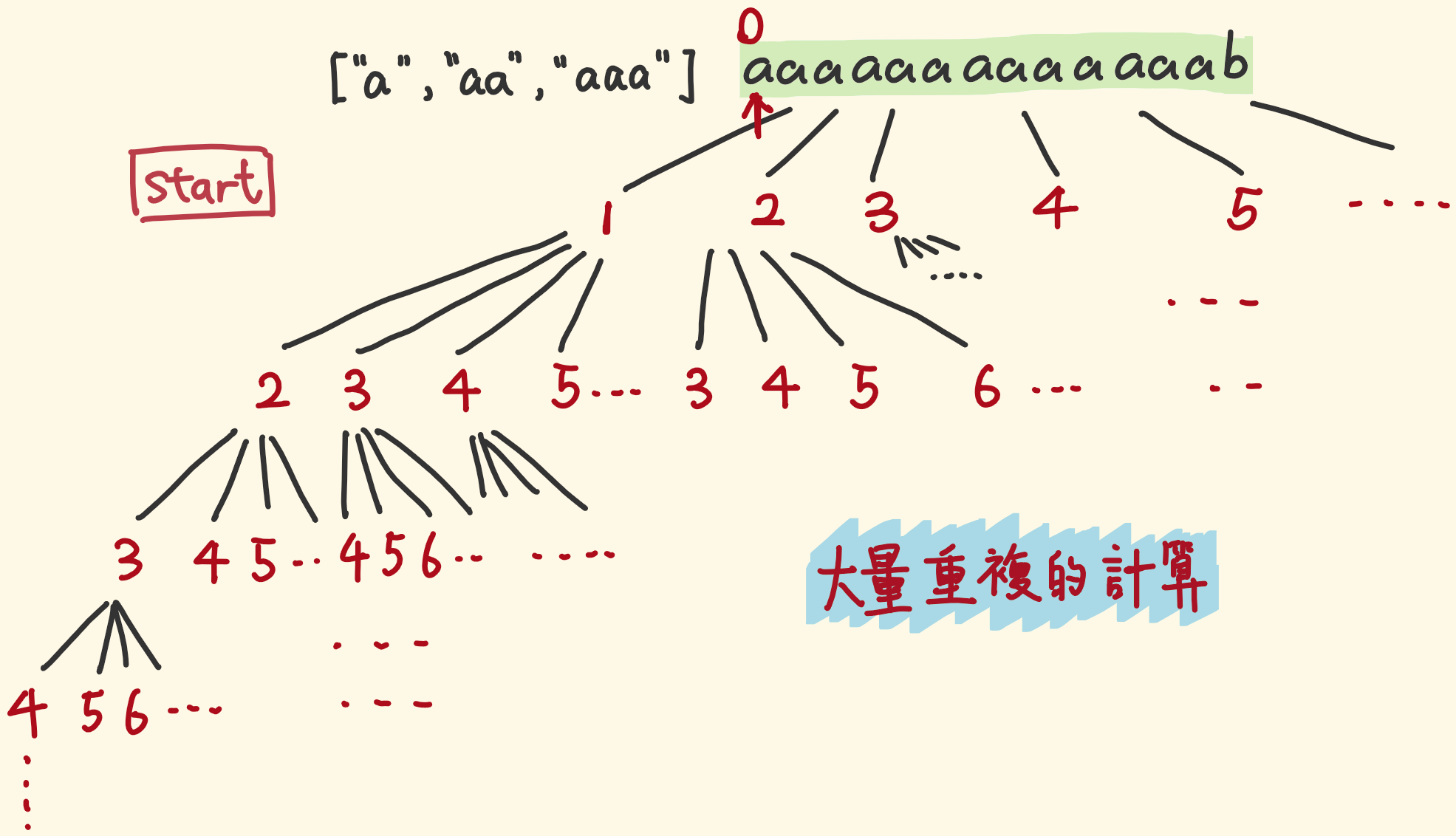
- 这个递归是前序遍历的,遍历到右侧子树时,前面其实都已经计算过了
- 用一个数组,去存之前计算的结果,数组索引对应指针位置,值对应子调用的结果。下次遇到相同的子问题,直接返回数组中的缓存值
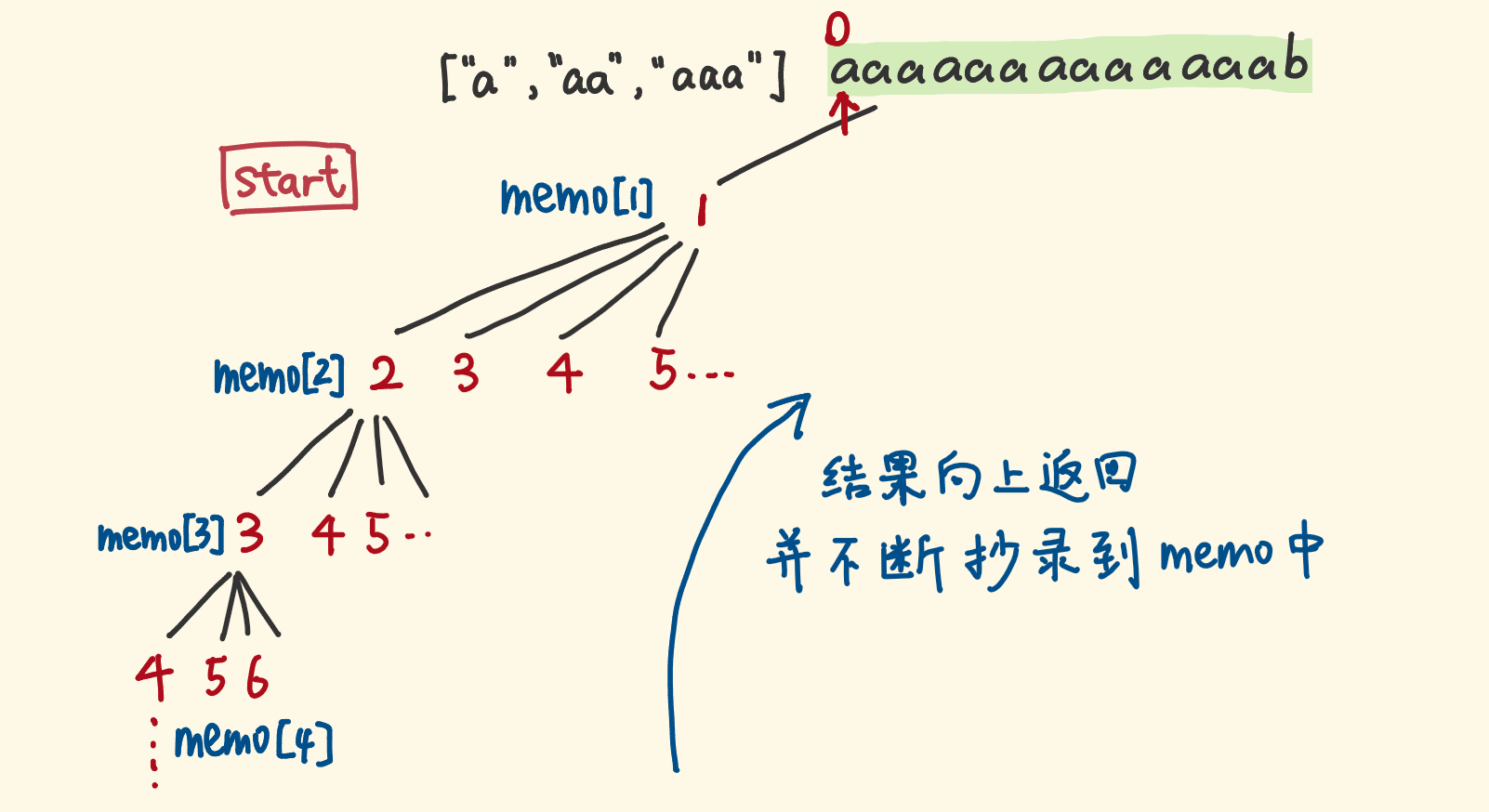
DFS + 记忆化 代码
const wordBreak = (s, wordDict) => {
const wordSet = new Set(wordDict);
const memo = new Array(s.length);
const check = (s, wordSet, start, memo) => {
if (start == s.length) return true;
if (memo[start] !== undefined) return memo[start];
for (let end = start + 1; end <= s.length; end++) {
const word = s.slice(start, end);
if (wordSet.has(word) && check(s, wordSet, end, memo)) {
return memo[start] = true;
}
}
return memo[start] = false;
};
return check(s, wordSet, 0, memo);
};
BFS 方法
- 能用DFS遍历节点当然也可以用BFS。维护一个队列,依然用指针代表节点的状态。
- 如下图,起初 0 入列,然后它出列,考察指针 1,2,3,4,5,6,7,8。它们分别与指针 0 围成前缀部分,如果不是单词表的单词,对应的指针就不入列,否则入列。
- 指针出列,考察它的子节点,能入列的就入列、再出列……重复。
- 直到没有指针可入列,即指针越界,如果此时的前缀部分是单词表单词,返回 true,或从始至终没有返回 true,则返回 false。
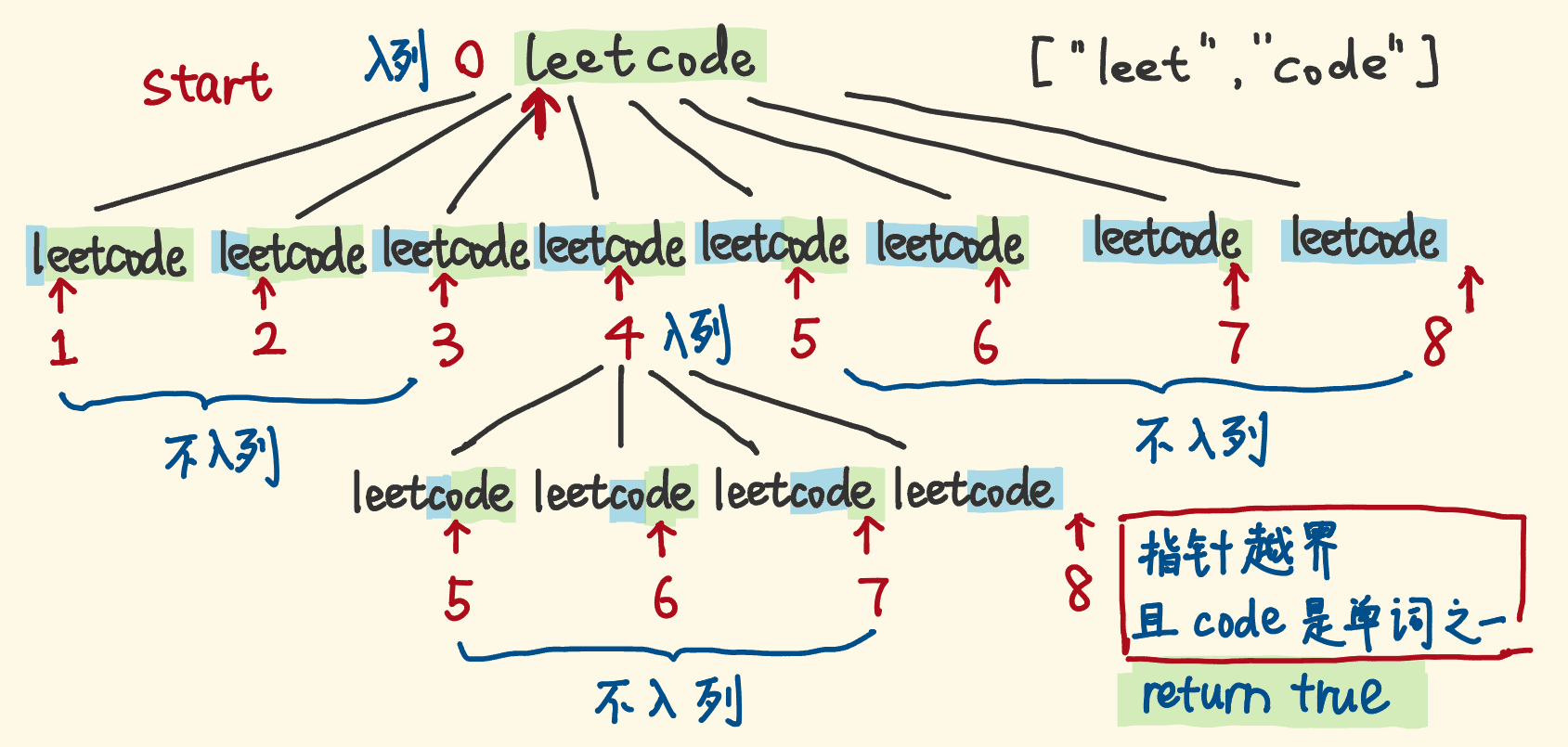
BFS 代码
const wordBreak = (s, wordDict) => {
const wordSet = new Set(wordDict);
const queue = [0];
while (queue.length) {
// 考察出列的节点
const start = queue.shift();
for (let end = start + 1; end <= s.length; end++) {
// end指针去划分两部分,下面是前缀部分
const word = s.slice(start, end);
// 前缀部分是单词表单词
if (wordSet.has(word)) {
// 前缀部分是单词表单词,end指针又越界,说明前缀部分是一整个单词,直接返回true
if (end == s.length) return true;
// 否则,前缀部分是单词表单词,end还没越界,end入列,作为下一层待考察的节点
queue.push(end);
}
// 前缀部分不是单词表的单词,直接死刑,剩下的就不用看了,不用入列
}
}
// 遍历完所有节点也没有返回true,则返回false
return false;
};
看似没有问题,但同样的,遇到下面的例子就超时:
BFS 避免访问重复的节点
- 未剪枝的DFS会重复遍历节点,BFS也一样,为了避免,用一个 visited 数组记录访问过的节点,作用其实和 memo 一样
- 出列考察一个节点时,将它存入visited,索引存指针位置,值存true
优化后的 BFS 代码
const wordBreak = (s, wordDict) => {
const wordSet = new Set(wordDict);
const visited = new Array(s.length);
// 先考察start位置0
const queue = [0];
while (queue.length) {
const start = queue.shift();
// 如果访问过了,就跳过
if (visited[start] === true) continue;
// 现在访问了 记录一下
visited[start] = true;
for (let end = start + 1; end <= s.length; end++) {
const word = s.slice(start, end);
if (wordSet.has(word)) {
// 前缀部分是单词表单词,end指针又越界,说明前缀部分是一整个单词,直接返回true
if (end == s.length) return true;
// 否则,前缀部分是单词表单词,end还没越界,end入列,作为下一层待考察的节点
queue.push(end);
}
// 前缀部分不是单词表的单词,直接死刑,剩下的就不用看了,不用入列
}
}
return false;
};
方法3:动态规划
- 题目说:s 串能否分解为单词表里的单词,即:前 s.length 个字符的 s 串能否分解为单词表里的单词
- 将大问题分解为子问题:
- 前 x 个字符的子串能否分解成单词表里的单词 + 剩余子串是否为单词表中的单个单词

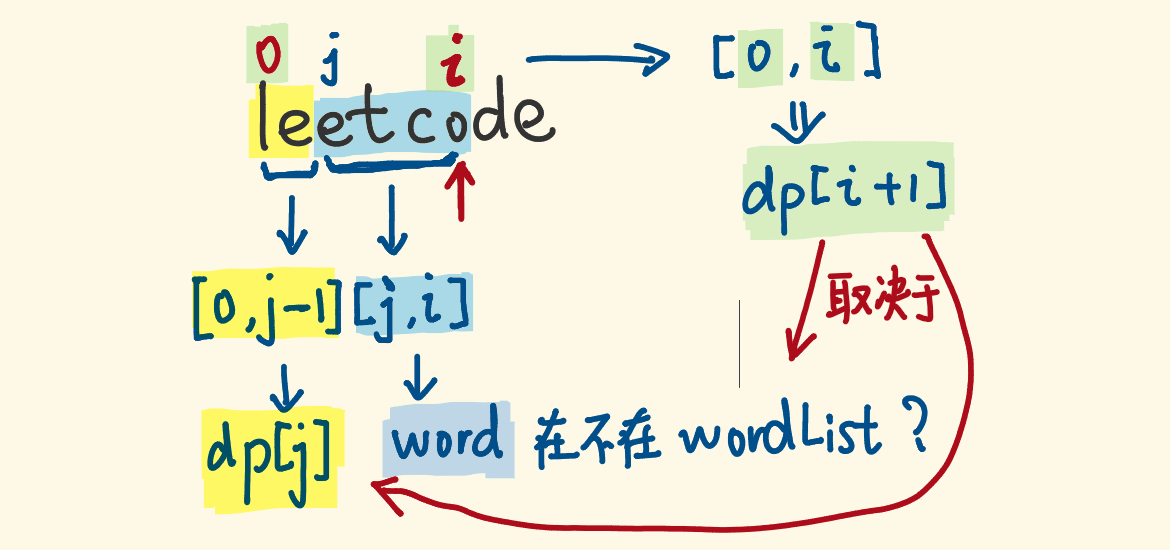
状态转移方程
-
用指针 jj 去划分这两部分
-
[0, i][0,i]
区间子串 的
dp[i+1]d**p[i+1]
是否为真,取决于两部分:
- 它的前缀子串 [0, j-1][0,j−1] 的 dp[j]d**p[j] 是否为真
- 剩余子串 [j,i][j,i] 是否是一个合格的单词
base case
- dp[0] = true。长度为 0 的子串是由单词表的单词组成的。是很诡异。
- 但这纯粹是为了让边界情况也能满足状态转移方程,即上图:当黄色部分为空字符串时,dp[i+1]d**p[i+1] 全然取决于 [0,i][0,i] 子串是否是单词表的单词
- 所以我们让 dp[0] = true
动态规划 代码
const wordBreak = (s, wordDict) => {
const wordSet = new Set(wordDict);
const len = s.length;
const dp = new Array(len + 1).fill(false);
dp[0] = true;
// i从1开始到len
for (let i = 1; i <= len; i++) {
// j去划分成两部分
for (let j = i - 1; j >= 0; j--) {
// 后缀部分[j,i-1]
const word = s.slice(j, i);
// 后缀部分是单词,且左侧子串[0,j-1]的dp[j]为真
if (wordSet.has(word) && dp[j] == true) {
// 共同决定了当前长度为i的子串的dp项为真
dp[i] = true;
// i长度的子串已经可以break成单词表的单词了,不需要j继续划分子串
break;
}
}
}
return dp[s.length];
};
动态规划 优化 代码
- 遇到 dp[i] == true ,直接break
- 遇到 dp[j] == false, dp[i] 没有 true 的可能,continue,考察下一个 j
- 这么优化,体现到结果好像并没有多优化
var wordBreak = function (s, wordDict) {
const wordSet = new Set(wordDict);
const len = s.length;
const dp = new Array(len + 1).fill(false);
dp[0] = true;
for (let i = 1; i <= len; i++) {
for (let j = i - 1; j >= 0; j--) {
if (dp[i] == true) break;
if (dp[j] == false) continue;
const word = s.slice(j, i);
if (wordSet.has(word) && dp[j] == true) {
dp[i] = true;
break;
}
}
}
return dp[s.length];
};
java版本代码
// BFS
public boolean wordBreak(String s, List<String> wordDict) {
Queue<Integer> queue = new LinkedList<>();
queue.add(0);
int slength = s.length();
boolean[] visited = new boolean[slength + 1];
while (!queue.isEmpty()) {
int size = queue.size();
for (int i = 0; i < size; i++) {
int start = queue.poll().intValue();
for (String word : wordDict) {
int nextStart = start + word.length();
if (nextStart > slength || visited[nextStart]) {
continue;
}
if (s.indexOf(word, start) == start) {
if (nextStart == slength) {
return true;
}
queue.add(nextStart);
visited[nextStart] = true;
}
}
}
}
return false;
}
// DFS
public boolean wordBreak(String s, List<String> wordDict) {
boolean[] visited = new boolean[s.length() + 1];
return dfs(s, 0, wordDict, visited);
}
private boolean dfs(String s, int start, List<String> wordDict, boolean[] visited) {
for (String word : wordDict) {
int nextStart = start + word.length();
if (nextStart > s.length() || visited[nextStart]) {
continue;
}
if (s.indexOf(word, start) == start) {
if (nextStart == s.length() || dfs(s, nextStart, wordDict, visited)) {
return true;
}
visited[nextStart] = true;
}
}
return false;
}
// DP
public class Solution {
public boolean wordBreak(String s, List<String> wordDict) {
Set<String> wordDictSet = new HashSet(wordDict);
boolean[] dp = new boolean[s.length() + 1];
dp[0] = true;
for (int i = 1; i <= s.length(); i++) {
for (int j = 0; j < i; j++) {
if (dp[j] && wordDictSet.contains(s.substring(j, i))) {
dp[i] = true;
break;
}
}
}
return dp[s.length()];
}
}
];
dp[0] = true;
for (int i = 1; i <= s.length(); i++) {
for (int j = 0; j < i; j++) {
if (dp[j] && wordDictSet.contains(s.substring(j, i))) {
dp[i] = true;
break;
}
}
}
return dp[s.length()];
}
}
本文标题:【leetcode】139.单词拆分 (DFS+BFS+动态规划图文详解,java实现)
本文链接:https://blog.quwenai.cn/post/4745.html
版权声明:本文不使用任何协议授权,您可以任何形式自由转载或使用。




还没有评论,来说两句吧...