
一、HDFS概述
基于hadoop2.6
HDFS被设计能够运行在通用硬件上、提供流式数据操作、能够处理超大文件的分布式文件系统。
特点:高容错和高吞吐量、易扩展、高可靠性
HDFS的四个核心模块:namenode节点、datanode节点、客户端、HDFS协议(RPC协议、流式接口协议:HTTP和TCP)
这里一些基本的概念我们就不重复叙述了,毕竟都是看源码的人了,连基本操作都不会我肯定是不信的所以我们直接进入正题
二、nameNode 之 httpServer启动源码分析
源码分析是一个缓慢的过程,这里我们先从namenode启动开始
hadoop是使用java语言编写的,因此,在启动hdfs命令中,存在在一个启动命令去启动java 线程的main方法,默认的情况下,启动的进程的名字和类名一致,顺着这个线性我们直接找到NameNode类
这里我使用的是hadoop2.6.5的版本。目录结构如下:
找到nameNode类
hadoop-hdfs-project -> hadoop-hdfs -> src -> main -> java -> org.apache.hadoop.hdfs.server.namenode -> NameNode.java
在这是看源码的时候,在看到比较关键的组件或者类的时候,建议把注释看一下,因为一般来说开源的注释都写得很详细,有着很高的参考价值,如果你英语不太好,也可以使用翻译软件翻译一下,配合上自己强大的技术功能,大概也能明白七七八八。
先把注释翻译放在这里,同时加入一些自己的理解
/**********************************************************
* NameNode server 的作用就是作为 目录命名空间 namespace 元数据管理器
* 以及 Hadoop DFS 的 inode table,
* 在任何DFS部署中都有一个独立 NameNode 运行。
* 例外 备份/故障转移NameNode,或者使用联邦NameNode。
*
* * NameNode serves as both directory namespace manager and
* "inode table" for the Hadoop DFS. There is a single NameNode
* running in any DFS deployment. (Well, except when there
* is a second backup/failover NameNode, or when using federated NameNodes.)
*
* NameNode 管理的两个核心关键表 :
* 1) 文件名 -》 映射 block 序列集 一个文件会拆分为多个128MB的BLOCK 文件,
* 分布在各个dataNode中 这份映射数据,可以理解为 namespace
* 2) block -》 映射 dataNode 集合 一个block 会有多个副本 这个映射数据就是inodes
*
* The NameNode controls two critical tables:
* 1) filename->blocksequence (namespace)
* 2) block->machinelist ("inodes")
*
* 'NameNode'既指这个类,也指'NameNode服务器'。 因为我们最终是以进程的方式在运行。
* 'FSNamesystem'类实际上执行了大部分文件系统管理。说明还有一个比较关键的类。
* NameNode类本身主要是涉及向外部公开IPC接口和HTTP服务器,以及一些配置管理。
*
* 'NameNode' refers to both this class as well as the 'NameNode server'.
* The 'FSNamesystem' class actually performs most of the filesystem
* management. The majority of the 'NameNode' class itself is concerned
* with exposing the IPC interface and the HTTP server to the outside world,
* plus some configuration management.
*
* NameNode 实现了 ClientProtocol 接口,该接口主要是让client端访问DFS服务,
* ClientProtocol 设计并不是让客户端直接使用,用户最终是使用FileSystem类
*
* NameNode implements the
* {@link org.apache.hadoop.hdfs.protocol.ClientProtocol} interface, which
* allows clients to ask for DFS services.
* {@link org.apache.hadoop.hdfs.protocol.ClientProtocol} is not designed for
* direct use by authors of DFS client code. End-users should instead use the
* {@link org.apache.hadoop.fs.FileSystem} class.
*
* NameNode也实现了DatanodeProtocol 接口,用于实际存储DFS数据块的datanode实例。
* 这些方法在DFS集群中 由datanode 调用。(里面是一些注册 心跳相关的接口)
*
* NameNode also implements the
* {@link org.apache.hadoop.hdfs.server.protocol.DatanodeProtocol} interface,
* used by DataNodes that actually store DFS data blocks. These
* methods are invoked repeatedly and automatically by all the
* DataNodes in a DFS deployment.
*
* NameNode 也实现了NamenodeProtocol 协议接口,主要用于备份的nameNode,获取监控nameNode状态。
* NameNode also implements the
* {@link org.apache.hadoop.hdfs.server.protocol.NamenodeProtocol} interface,
* used by secondary namenodes or rebalancing processes to get partial
* * NameNode state, for example partial blocksMap etc.
**********************************************************/
@InterfaceAudience.Private
public class NameNode implements NameNodeStatusMXBean {这里我再单独把自己的理解写一下:
namenode是用来管理文件系统的namespace,以及block dataNode相关的元数据信息。
主要管理两类数据(tables,数据表格,数据映射),两个核心表映射:
1) 文件名 -》 映射 block 序列集 一个文件会拆分为多个128MB的BLOCK 文件, 分布在各个dataNode中 这份映射数据,可以理解为 namespace
namespace是存放在磁盘上的,同时也存放在内存里
2) block -》 映射 dataNode 集合 一个block 会有多个副本 这个映射数据就是inodes
inodes(那些block是在哪些datanode上),这份数据,是在每次namenode启动之后,由datanode来汇报过来的,而且datanode在运行期间会每隔一段时间都汇报一下自己有哪些block,汇报给namenode
然后我们又看到了几个比较核心的关键词 : NameNode、NameNodeServer、FSNamesystem。其实也就是比较核心的几个组件概念
什么意思呢?大概猜测一下,我们的nameNode 是以服务存在,肯定是要提供对面请求接口:
NameNode : 主要是干两件事情,第一件事情就是处理一些配置属性,第二件事情就是启动NameNodeServer,NameNodeHttpServer,NameNodeRpcServer,这个两个server其实就是对外监听了某个端口,datanode、dfsclient都可以通过两个server来请假端口,发起这个请求。
NameNodeServer :NameNodeHttpServer、NameNodeRpcServer,http请求,rpc请求,datanode、dfsclient都可以来请求他们,比如说请求这两个server来创建目录、上传文件、下载文件、dfsadmin管理性的操作
FSNamesystem:负责管理元数据,其实是他在管理文件系统的操作,或者内存里元数据的管理,诸如此类的一些操作
注释大概看完了,现在直接找到入口,那么就是main方法
/**
* 入口
*/
public static void main(String argv[]) throws Exception {
//一些帮助命令打印,其实就是看你是不是需要命令解释help,并不是需要分析的代码
if (DFSUtil.parseHelpArgument(argv, NameNode.USAGE, System.out, true)) {
System.exit(0);
}
try {
//就是简单的输出一下日志消息,同时注册一个hook 用于关闭的时候 打印一下关闭日志,没什么关键代码
StringUtils.startupShutdownMessage(NameNode.class, argv, LOG);
//根据传入的参数进行构建NameNode 一看就是比较关键的地方
NameNode namenode = createNameNode(argv, null);
if (namenode != null) {
namenode.join();
}
} catch (Throwable e) {
LOG.fatal("Failed to start namenode.", e);
terminate(1, e);
}
}上面中代码
(1)看你是不是命令帮助,如果是命令帮助,打印,就直接结束进程
(2)打印一下启动日志,并注册一个结束时候的hook 回调打印日志的功能
(3)核心: 构建NameNode
构建核心代码
public static NameNode createNameNode(String argv[], Configuration conf)
throws IOException {
LOG.info("createNameNode " + Arrays.asList(argv));
if (conf == null)
conf = new HdfsConfiguration();
// Parse out some generic args into Configuration.
//解析一些通用参数到配置中。
GenericOptionsParser hParser = new GenericOptionsParser(conf, argv);
argv = hParser.getRemainingArgs();
// Parse the rest, NN specific args.
//解析剩下的 用于nameNode 特定的参数 就是将传入的参数 转为 内部业务的指令
//里面是 比如 -format 参数 就转为XXX , 如果 -clusterid 就XXXX option
StartupOption startOpt = parseArguments(argv);
if (startOpt == null) {
printUsage(System.err);
return null;
}
//设置启动参数 以及一些选项命令
setStartupOption(conf, startOpt);
//根据启动的选项 构建一个 NameNode返回
switch (startOpt) {
case FORMAT: {
boolean aborted = format(conf, startOpt.getForceFormat(),
startOpt.getInteractiveFormat());
terminate(aborted ? 1 : 0);
return null; // avoid javac warning
}
case GENCLUSTERID: {
System.err.println("Generating new cluster id:");
System.out.println(NNStorage.newClusterID());
terminate(0);
return null;
}
case FINALIZE: {
System.err.println("Use of the argument '" + StartupOption.FINALIZE +
"' is no longer supported. To finalize an upgrade, start the NN " +
" and then run `hdfs dfsadmin -finalizeUpgrade'");
terminate(1);
return null; // avoid javac warning
}
case ROLLBACK: {
boolean aborted = doRollback(conf, true);
terminate(aborted ? 1 : 0);
return null; // avoid warning
}
case BOOTSTRAPSTANDBY: {
String toolArgs[] = Arrays.copyOfRange(argv, 1, argv.length);
int rc = BootstrapStandby.run(toolArgs, conf);
terminate(rc);
return null; // avoid warning
}
case INITIALIZESHAREDEDITS: {
boolean aborted = initializeSharedEdits(conf,
startOpt.getForceFormat(),
startOpt.getInteractiveFormat());
terminate(aborted ? 1 : 0);
return null; // avoid warning
}
case BACKUP:
case CHECKPOINT: {
NamenodeRole role = startOpt.toNodeRole();
DefaultMetricsSystem.initialize(role.toString().replace(" ", ""));
return new BackupNode(conf, role);
}
case RECOVER: {
NameNode.doRecovery(startOpt, conf);
return null;
}
case METADATAVERSION: {
printMetadataVersion(conf);
terminate(0);
return null; // avoid javac warning
}
case UPGRADEONLY: {
DefaultMetricsSystem.initialize("NameNode");
new NameNode(conf);
terminate(0);
return null;
}
//正常情况会直接到这里 直接创建一个nameNode实例对象
default: {
DefaultMetricsSystem.initialize("NameNode");
return new NameNode(conf);
}
}
}1)将参数转为内部识别的option选项
2) 根据选项构建NameNode,正常来说都是直接构建default 分治
构建NameNode 代码分析
protected NameNode(Configuration conf, NamenodeRole role)
throws IOException {
this.conf = conf;
this.role = role;
setClientNamenodeAddress(conf);
String nsId = getNameServiceId(conf);
String namenodeId = HAUtil.getNameNodeId(conf, nsId);
this.haEnabled = HAUtil.isHAEnabled(conf, nsId);
state = createHAState(getStartupOption(conf));
this.allowStaleStandbyReads = HAUtil.shouldAllowStandbyReads(conf);
this.haContext = createHAContext();
try {
initializeGenericKeys(conf, nsId, namenodeId);
//核心初始化 nameNode
initialize(conf);
try {
haContext.writeLock();
state.prepareToEnterState(haContext);
state.enterState(haContext);
} finally {
haContext.writeUnlock();
}
} catch (IOException e) {
this.stop();
throw e;
} catch (HadoopIllegalArgumentException e) {
this.stop();
throw e;
}
this.started.set(true);
}构建中,里面大部分都是一些参数设置和处理,核心是 initialize(conf); 代码
/**
* Initialize name-node.
*
* @param conf the configuration
*/
protected void initialize(Configuration conf) throws IOException {
//其实这些配置 就是对应着我们配置的 hdfs-site.xml 或者 core-default.xml或者其他文件中一些配置信息
//这些一般也不是很重要
if (conf.get(HADOOP_USER_GROUP_METRICS_PERCENTILES_INTERVALS) == null) {
String intervals = conf.get(DFS_METRICS_PERCENTILES_INTERVALS_KEY);
if (intervals != null) {
conf.set(HADOOP_USER_GROUP_METRICS_PERCENTILES_INTERVALS,
intervals);
}
}
UserGroupInformation.setConfiguration(conf);
loginAsNameNodeUser(conf);
NameNode.initMetrics(conf, this.getRole());
StartupProgressMetrics.register(startupProgress);
//如果是nameNode 启动一个httpServer
if (NamenodeRole.NAMENODE == role) {
startHttpServer(conf);
}
this.spanReceiverHost = SpanReceiverHost.getInstance(conf);
loadNamesystem(conf);
rpcServer = createRpcServer(conf);
if (clientNamenodeAddress == null) {
// This is expected for MiniDFSCluster. Set it now using
// the RPC server's bind address.
clientNamenodeAddress =
NetUtils.getHostPortString(rpcServer.getRpcAddress());
LOG.info("Clients are to use " + clientNamenodeAddress + " to access"
+ " this namenode/service.");
}
//如果是NameNode 设置NameNodeAddress 以及 FsImage
if (NamenodeRole.NAMENODE == role) {
httpServer.setNameNodeAddress(getNameNodeAddress());
httpServer.setFSImage(getFSImage());
}
pauseMonitor = new JvmPauseMonitor(conf);
pauseMonitor.start();
metrics.getJvmMetrics().setPauseMonitor(pauseMonitor);
startCommonServices(conf);
}这里我们主要是看NameNode server 的启动,关于其他的先忽略,我们看如何启动htppServer
进入到startHttpServer
private void startHttpServer(final Configuration conf) throws IOException {
//构建一个NameNodeHttpServer, getHttpServerBindAddress(conf) 获取对外暴露的地址
//获取对外暴露的地址
InetSocketAddress httpServerBindAddress = getHttpServerBindAddress(conf);
//构建httpServer
httpServer = new NameNodeHttpServer(conf, this, httpServerBindAddress);
httpServer.start();
httpServer.setStartupProgress(startupProgress);
}这里我自己把代码改了一下方便逻辑看
1.获取对外暴露的绑定端口地址
2.构建httpServer
3.启动httpServer
这里我们到底对外暴露的端口是多少?我们自己看一看
protected InetSocketAddress getHttpServerBindAddress(Configuration conf) {
//明显是从配置文件中获取绑定给的端口 默认是 50070
InetSocketAddress bindAddress = getHttpServerAddress(conf);
//如果配置了我们自己配置了 dfs.namenode.http-bind-host,那么就会覆盖
// If DFS_NAMENODE_HTTP_BIND_HOST_KEY exists then it overrides the
// host name portion of DFS_NAMENODE_HTTP_ADDRESS_KEY.
final String bindHost = conf.getTrimmed(DFS_NAMENODE_HTTP_BIND_HOST_KEY);
if (bindHost != null && !bindHost.isEmpty()) {
bindAddress = new InetSocketAddress(bindHost, bindAddress.getPort());
}
return bindAddress;
}/** @return the NameNode HTTP address. */
public static InetSocketAddress getHttpAddress(Configuration conf) {
return NetUtils.createSocketAddr(
conf.get(DFS_NAMENODE_HTTP_ADDRESS_KEY, DFS_NAMENODE_HTTP_ADDRESS_DEFAULT));
}
默认50070端口,同时也允许我们通过自定义端口覆盖
httpServer.start()启动服务,到这里我们的服务终于启动了
/**
* @see DFSUtil#getHttpPolicy(org.apache.hadoop.conf.Configuration)
* for information related to the different configuration options and
* Http Policy is decided.
*/
void start() throws IOException {
HttpConfig.Policy policy = DFSUtil.getHttpPolicy(conf);
final String infoHost = bindAddress.getHostName();
final InetSocketAddress httpAddr = bindAddress;
final String httpsAddrString = conf.get(
DFSConfigKeys.DFS_NAMENODE_HTTPS_ADDRESS_KEY,
DFSConfigKeys.DFS_NAMENODE_HTTPS_ADDRESS_DEFAULT);
InetSocketAddress httpsAddr = NetUtils.createSocketAddr(httpsAddrString);
if (httpsAddr != null) {
// If DFS_NAMENODE_HTTPS_BIND_HOST_KEY exists then it overrides the
// host name portion of DFS_NAMENODE_HTTPS_ADDRESS_KEY.
final String bindHost =
conf.getTrimmed(DFSConfigKeys.DFS_NAMENODE_HTTPS_BIND_HOST_KEY);
if (bindHost != null && !bindHost.isEmpty()) {
httpsAddr = new InetSocketAddress(bindHost, httpsAddr.getPort());
}
}
//hadoop 自己实现了一套服务器
HttpServer2.Builder builder = DFSUtil.httpServerTemplateForNNAndJN(conf,
httpAddr, httpsAddr, "hdfs",
DFSConfigKeys.DFS_NAMENODE_KERBEROS_INTERNAL_SPNEGO_PRINCIPAL_KEY,
DFSConfigKeys.DFS_NAMENODE_KEYTAB_FILE_KEY);
httpServer = builder.build();
if (policy.isHttpsEnabled()) {
// assume same ssl port for all datanodes
InetSocketAddress datanodeSslPort = NetUtils.createSocketAddr(conf.get(
DFSConfigKeys.DFS_DATANODE_HTTPS_ADDRESS_KEY, infoHost + ":"
+ DFSConfigKeys.DFS_DATANODE_HTTPS_DEFAULT_PORT));
httpServer.setAttribute(DFSConfigKeys.DFS_DATANODE_HTTPS_PORT_KEY,
datanodeSslPort.getPort());
}
initWebHdfs(conf);
httpServer.setAttribute(NAMENODE_ATTRIBUTE_KEY, nn);
httpServer.setAttribute(JspHelper.CURRENT_CONF, conf);
//这里很关键,这里是将一些servlet 与 server 进行绑定,如果你不知道servlet 是什么 这就很尴尬了
//里面其实就是 比如 http://XXXX:50070/listPath/ 交给哪个servlet处理
setupServlets(httpServer, conf);
//启动
httpServer.start();
int connIdx = 0;
if (policy.isHttpEnabled()) {
httpAddress = httpServer.getConnectorAddress(connIdx++);
conf.set(DFSConfigKeys.DFS_NAMENODE_HTTP_ADDRESS_KEY,
NetUtils.getHostPortString(httpAddress));
}
if (policy.isHttpsEnabled()) {
httpsAddress = httpServer.getConnectorAddress(connIdx);
conf.set(DFSConfigKeys.DFS_NAMENODE_HTTPS_ADDRESS_KEY,
NetUtils.getHostPortString(httpsAddress));
}
}
1)通过构建者模式构建一个hadoop自己实现的一套httpServer2 对外服务器
2)将servlet 与 httpServer 进行绑定,里面其实就是 url 映射 servlet ,比如 http://XXXX:50070/listPath/ 交给哪个servlet处理
3) 最后真正的启动。
其实这里我先讲的很粗糙,为什么?因为一下上来直接给你讲细致了 你也懵,不如先来个大致的思路,我们总结下
1.main方法调用createNameNode 尝试构建NameNode
2.args 参数转为内部能识别的option选项 真正的构建NameNode
3.NameNode 内部构建的时候 调用initialize(conf); 进行核心初始化
4.构建NameNodeHttpServer,获取对外端口地址 默认50070
5.NameNodeHttpServer.start()内部 再次构建hadoop自己实现的一套HttpServer2 服务机制
6.讲处理url请求的servlet 与 httpServer 绑定
7.真正的启动服务
其实真正处理请求的是 NameNodeHttpServer 中的 HttpServer2 中的 HttpServlet
这里我们简单画个图 理解下
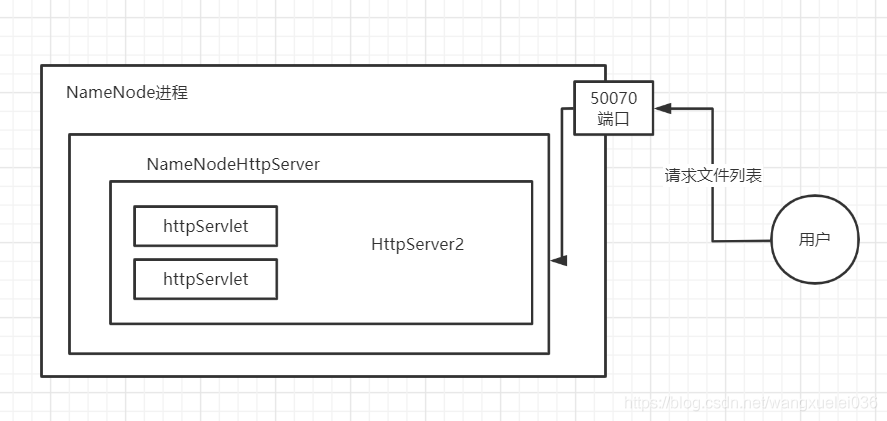
到这,我们也清除了基本一个NameNode 的一个服务结构,但是还有很多其他的核心需要分析。
本章关键词 NameNode NameNodeHttpServer HttpServer2 HttpServlet InetSocketAddress




还没有评论,来说两句吧...