
很多高性能的应用都会对关联查询进行分解。阿里巴巴开发手册上面也明确的说当涉及三张以上的关联查询的时候,应该在应用层对业务进行拆分。
思考?:为什么以前说是让数据库进行完成多的业务操作?而现在又让我们自己在应用层拆分呢?
对于上诉问题,我们应该分析下,在哪些地方发生变化:
最明显的改变如下:
地方就是,以前的单次请求返回变成了多次的请求返回,增加了网络开销
业务代码又要调整,而且代码了还变多了,唉.....
但换来的是数据库每次运行的业务的变得简单化,每次请求的时间变短。
?思考:那么增加了网络开销,但是每次执行时间又变短了,那么性能是更好了还是更坏了呢?
拍一拍脑瓜就知道肯定是性能变好了,那么我们肯定会想,为什么以前不进行拆分复杂关联查询来提升性能呢?
没错,为什么?因为科学技术的快速发展,千万不要忽略了科技的发展,不然你最终会被如今快速发展的社会所淘汰。
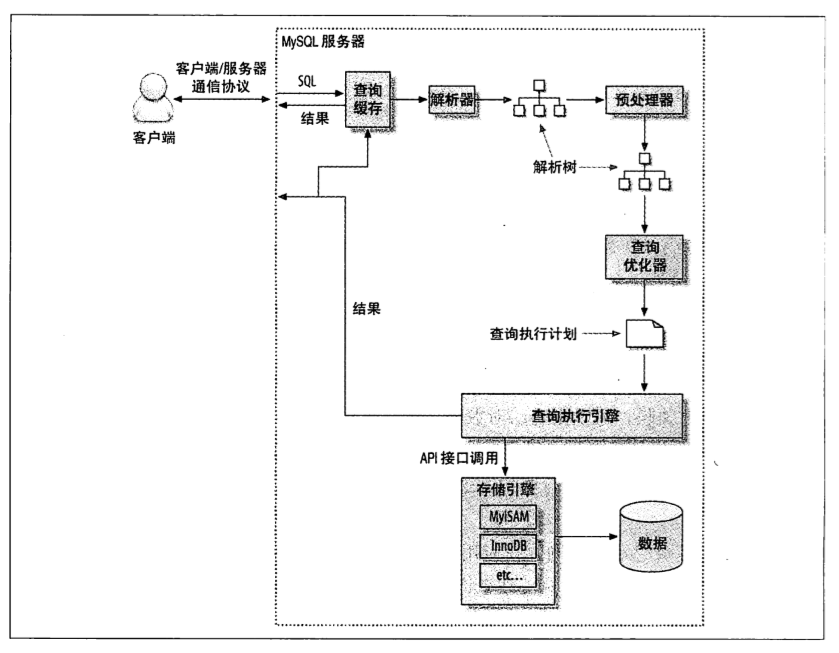
在多年以前,最好的方案是让数据库尽可能多的去完成复杂的工作,那是因为在那时的环境下,重视强调网络通信慢,多次网络请求开销大,数据库查询解析和优化花费代价很高,综合考虑下得出的最优的方案是:让数据库一次性多干活。
但是对于现在的Mysql并不适用,网络通信性能的提升(带宽和延迟),mysql连接和断开很轻量级,分析和优化代价更小,让返回小结果集更加高效,之前的网络限制也不再是问题的关键,那么我们就应该转变思维,改成多次请求,反而会更快速,更高效。
那改成多次请求后,究竟在哪些地方带来了更高效的性能提升了。
注:最优的方案只是在限定条件下是最优的,哪怕是任何一个条件发生了变动,我们都应该考虑之前的方案是否还是最优解。
事实上分解关联查询的方式重构查询的优势有:
- 让缓存的效率更高。我们知道执行一条sql的时候,会先去查询缓存中查找。那么许多应用程序可以方便地缓存单表查询对应的结果对象。如果关联查询,那么关联中的某个表发生了变化,那么就无法使用查询缓存,而拆分后,如果某个表很少改变,那么基于该表的查询就可以重复利用查询缓存结果了。
- 将查询拆分后,执行单个查询可以减少锁的竞争。
- 在应用层做关联,可以更容易对数据库进行拆分,在现如今分库分表普遍使用的情景下,更容易做到高性能和可扩展。
- 查询本身效率也可能会有所提升。比如:让某些查询用IN()代替关联查询,可以让Mysql按照ID顺序进行查询,着可能比随机的关联要更搞笑。
- 可以减少冗余记录的查询。在应用层做关联,意味着对于某条记录应用只需要查询一次,而在数据库中做关联查询,则可能徐娅重复地访问一部分数据。从这方面看,这样的重构还可能会减少网络和内存的消耗。
- 分解关联查询,相当于在应用中实现了哈希关联,而不是使用Mysql的类似嵌套循环关联。某些场景哈希关联的效率更高效
本文标题:为什么要分解Mysql复杂的关联查询?在应用层实现多次请求?
本文链接:https://blog.quwenai.cn/post/2844.html
版权声明:本文不使用任何协议授权,您可以任何形式自由转载或使用。




还没有评论,来说两句吧...