
1.什么是SPI
SPI全称Service Provider Interface,是Java提供的一套用来被第三方实现或者扩展的接口,它可以用来启用框架扩展和替换组件。 SPI的作用就是为这些被扩展的API寻找服务实现。
- 本质是 将接口实现类的全限定名配置在文件中,并由服务加载器读取配置文件,加载实现类。这样可以在运行时,动态为接口替换实现类。
2.基本思想
其实Java SPI 实际上是“基于接口的编程+策略模式+配置文件”组合实现的动态加载机制。
系统设计的各个抽象,往往有很多不同的实现方案,在面向的对象的设计里,一般推荐模块之间基于接口编程,模块之间不对实现类进行硬编码。一旦代码里涉及具体的实现类,就违反了可拔插的原则,如果需要替换一种实现,就需要修改代码。为了实现在模块装配的时候能不在程序里动态指明,这就需要一种服务发现机制。 Java SPI就是提供这样的一个机制:为某个接口寻找服务实现的机制。有点类似IOC的思想,就是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要。所以SPI的核心思想就是解耦。
概括地说,适用于:调用者根据实际使用需要,启用、扩展、或者替换框架的实现策略
3.SPI和API的使用场景
API (Application Programming Interface)在大多数情况下,都是实现方制定接口并完成对接口的实现,调用方仅仅依赖接口调用,且无权选择不同实现。 从使用人员上来说,API 直接被应用开发人员使用。
SPI (Service Provider Interface)是调用方来制定接口规范,提供给外部来实现,调用方在调用时则选择自己需要的外部实现。 从使用人员上来说,SPI 被框架扩展人员使用。
4.直接上代码 看下效果
定义一个接口
package org.alexsotob.reader;
public interface Decode {
boolean isEncodingNameSupported(String encodingName);
String decode(String data);
}
定义接口实现类(这里我定义了两个,可以根据自己需要定义)
RSADecoder 实现类
package org.alexsotob.reader.impl;
import org.alexsotob.reader.Decode;
public class RSADecoder implements Decode {
public static final String ENCODING_NAME = "RSA";
public RSADecoder() {
System.out.println("RSADecode init !!!");
}
@Override
public boolean isEncodingNameSupported(String encodingName) {
return ENCODING_NAME.equals(encodingName.trim());
}
@Override
public String decode(String data) {
return String.format("RSA decode %s", data);
}
}
AESDecoder实现类
package org.alexsotob.reader.impl;
import org.alexsotob.reader.Decode;
public class AESDecoder implements Decode {
public static final String ENCODING_NAME = "AES";
public AESDecoder() {
System.out.println("AESDecoder init!!!");
}
@Override
public boolean isEncodingNameSupported(String encodingName) {
return ENCODING_NAME.equals(encodingName.trim());
}
@Override
public String decode(String data) {
return String.format("AES decode %s",data);
}
}
重要的一步 :需要在resources目录下新建META-INF/services目录,并且在这个目录下新建一个与上述接口的全限定名一致的文件,在这个文件中写入接口的实现类的全限定名:
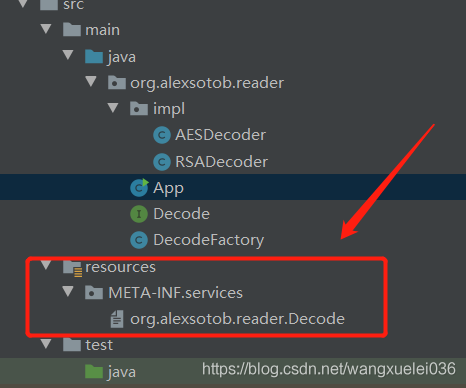
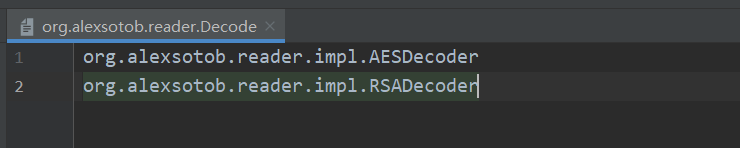
为了方便使用我们再定义一个工厂类,用于获取对象
package org.alexsotob.reader;
import java.io.UnsupportedEncodingException;
import java.util.ServiceLoader;
public class DecodeFactory {
private static ServiceLoader<Decode> decodeSetLoader = ServiceLoader.load(Decode.class);
public static Decode getDecoder(String encodingName) throws UnsupportedEncodingException {
for (Decode decode : decodeSetLoader) {
if(decode.isEncodingNameSupported(encodingName)) {
return decode;
}
}
throw new UnsupportedEncodingException();
}
}
编写调用类,进行测试
package org.alexsotob.reader;
import java.io.UnsupportedEncodingException;
import java.util.Arrays;
/**
* Hello world!
*/
public class App {
public static void main(String[] args) throws UnsupportedEncodingException {
String[] encodeNameArray = new String[]{"AES","RSA"};
String data = "data";
for (int i = 0; i < 10; i++) {
System.out.println(String.format("次数:%s",i));
Decode decoder = DecodeFactory.getDecoder(encodeNameArray[i%2]);
System.out.println(String.format("内容 : %s",decoder.decode(data)));
}
}
}
显示结果
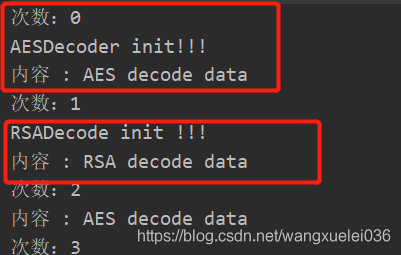
注:因为实现采用的是懒加载,在进行实例化的时候,会先去缓存cache中查找(因此对象是单例的),如果还没有被实例化 就会使用反射进行实例化
实际上,个人观点是 宁愿开始的时候就消耗点资源和时间将所有类都加载完毕,也不希望在项目运行中因为类实例化而消耗性能影响线上项目或者引起程序崩溃,如果程序崩溃,那么更应该在启动的时候提前暴露(当然也不绝对,具体根据项目情况)。
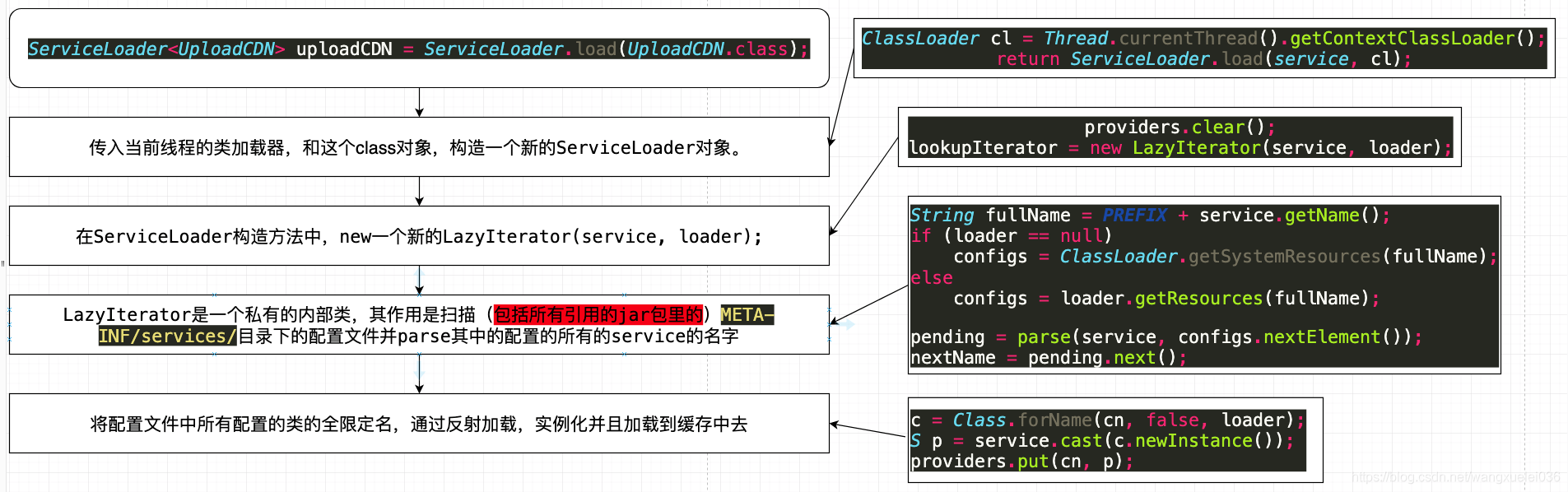
上面的代码只贴出了部分关键的实现,有兴趣的读者可以自己去研究,下面贴出比较直观的spi加载的主要流程供参考:
public final class ServiceLoader<S> implements Iterable<S> {
//扫描目录前缀
private static final String PREFIX = "META-INF/services/";
// 被定位 加载 实例化 的类或接口
private final Class<S> service;
// 用于定位、加载和实例化实现方实现的类的类加载器
private final ClassLoader loader;
// 上下文对象
private final AccessControlContext acc;
// 按照实例化的顺序缓存已经实例化的类
private LinkedHashMap<String, S> providers = new LinkedHashMap<>();
// 懒查找迭代器 内部实现类,
private java.util.ServiceLoader.LazyIterator lookupIterator;
// 私有内部类,提供对所有的service的类的加载与实例化
//懒加载机制,在真正使用的时候利用反射进行实例化对象
private class LazyIterator implements Iterator<S> {
Class<S> service;
ClassLoader loader;
Enumeration<URL> configs = null;
String nextName = null;
//...
private boolean hasNextService() {
if (configs == null) {
try {
//获取目录下所有的类
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
//...
}
//....
}
}
private S nextService() {
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
//反射加载类
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
}
try {
//实例化
S p = service.cast(c.newInstance());
//放进缓存
providers.put(cn, p);
return p;
} catch (Throwable x) {
//..
}
//..
}
}
}
从上面的java spi的原理中可以了解到,java的spi机制有着如下的弊端:
- 只能遍历所有的实现,并全部实例化。
- 配置文件中只是简单的列出了所有的扩展实现,而没有给他们命名。导致在程序中很难去准确的引用它们(注:当然我们在例子中使用了简单的工厂模式,重写了判定条件简单的实现了该功能,但java SPI 本省是不支持的)。
- 扩展如果依赖其他的扩展,做不到自动注入和装配。
- 扩展很难和其他的框架集成,比如扩展里面依赖了一个Spring bean,原生的Java SPI不支持。
接下来我们将继续讨论Dubbo SPI 机制以及源码实现:
Dubbo SPI 基本操作与源码深入理解
参考
https://www.cnblogs.com/jy107600/p/11464985.html

![[并发编程] - Executor框架#ThreadPoolExecutor源码解读02](https://blog.quwenai.cn/zb_users/upload/2022/03/20220327124158164835611866353.png "[并发编程] - Executor框架#ThreadPoolExecutor源码解读02")


还没有评论,来说两句吧...