
进程
第一,进程是一个实体。每一个进程都有它自己的地址空间,一般情况下,包括文本区域(text region)、数据区域(data region)和堆栈(stack region)。文本区域存储处理器执行的代码;数据区域存储变量和进程执行期间使用的动态分配的内存;堆栈区域存储着活动过程调用的指令和本地变量。第二,进程是一个“执行中的程序”。程序是一个没有生命的实体,只有处理器赋予程序生命时(操作系统执行之),它才能成为一个活动的实体,我们称其为进程。
进程是进程实体的运行过程,是系统进行资源分配和调度的一个独立单元。
进程的特征
- 动态性:进程的实质是程序在多道程序系统中的一次执行过程,进程是动态产生,动态消亡的。
- 并发性:任何进程都可以同其他进程一起并发执行
- 独立性:进程是一个能独立运行的基本单位,同时也是系统分配资源和调度的独立单位;
- 异步性:由于进程间的相互制约,使进程具有执行的间断性,即进程按各自独立的、不可预知的速度向前推进
结构特征
进程由程序、数据和进程控制块三部分组成。
线程
最直接的理解就是“轻量级进程”,它是一个基本的CPU执行单元。
多核CPU下,各个线程也可以分派到不同的CPU上并行执行,也是程序执行流的最小单元,由线程ID,程序计数器,寄存器集合和堆栈组成。线程是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,但它可以和同属一个进程的其他线程共享进程所拥有的系统资源。一个线程可以创建和撤销另一个线程,同一进程中的多个线程之间可以并发执行。由于线程之间的互相制约,导致线程在运行中呈现间断性。
线程又分为:用户级线程和内核级线程
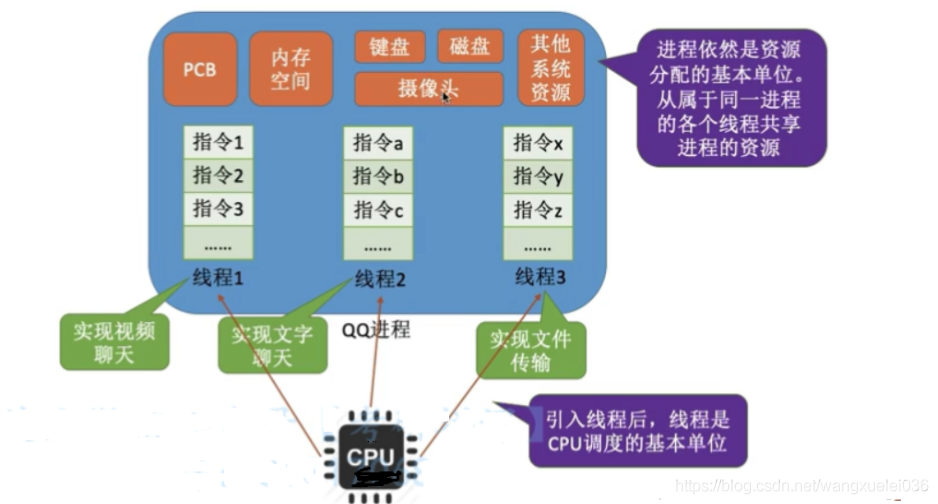
引入线程之后,进程是资源分配的基本单位。而线程几乎不拥有资源,只拥有极少量的资源(线程控制块TCB,寄存器信息,堆栈等),线程是调度的基本单元
?思考:进程也是独立的可并发等特性,为什么还要引入线程呢?
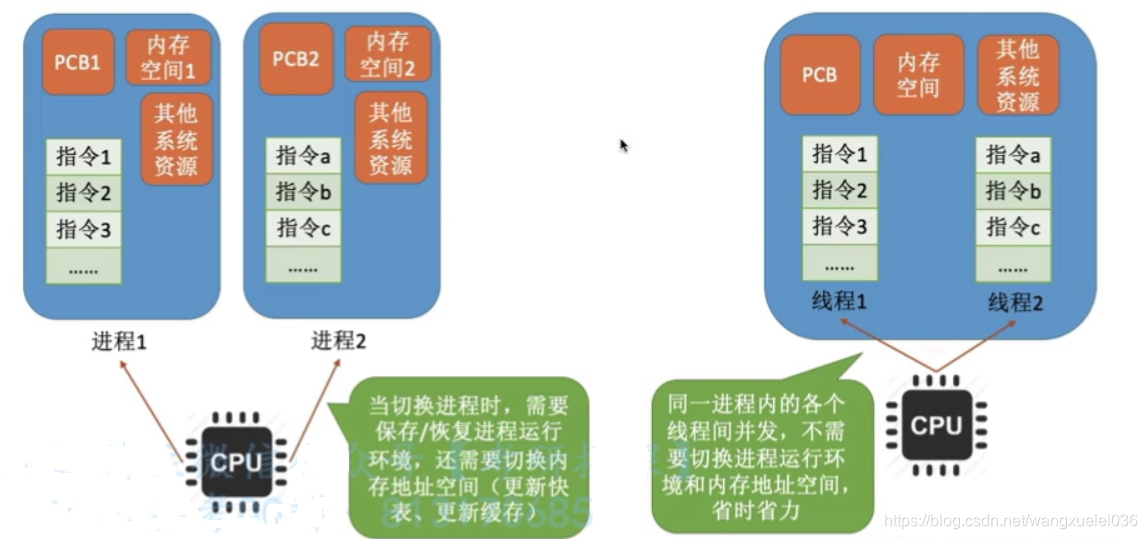
进程地址空间资源时独立的,在进行切换时需要保存/恢复进程运行时环境,还需要切换内存地址空间(更新块表,更新缓存),开销很大,引入线程的最主要原因就是为了降低切换时候的消耗(注:线程切换也有消耗,线程的运行时环境等信息)
另外进程间通信必须请求操作系统服务(CPU需要切换到核心态),开销大(注:不同进程的线程间通信,也需要请求操作系统)
协程
协程不是进程或线程,其执行过程更类似于子例程,或者说不带返回值的函数调用。
思考?:为什么要引入协程?线程之间是如何进行协作的呢?
最经典的例子就是生产者/消费者模式:
若干个生产者线程向队列中写入数据,若干个消费者线程从队列中消费数据。
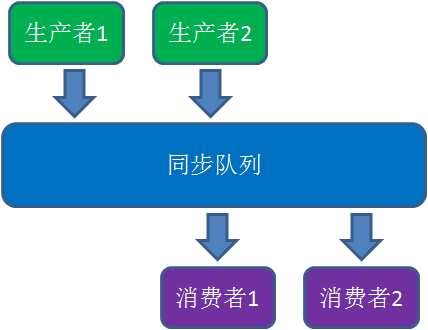
?思考:生产者/消费者模式确实能实现线程之间的协作,但是却并不是一个高性能的实现。为什么性能不高呢?原因如下:
- 涉及到同步锁。
- 涉及到线程阻塞状态和可运行状态之间的切换。
- 涉及到线程上下文的切换。
以上涉及到的任何一点,都是非常耗费性能的操作。
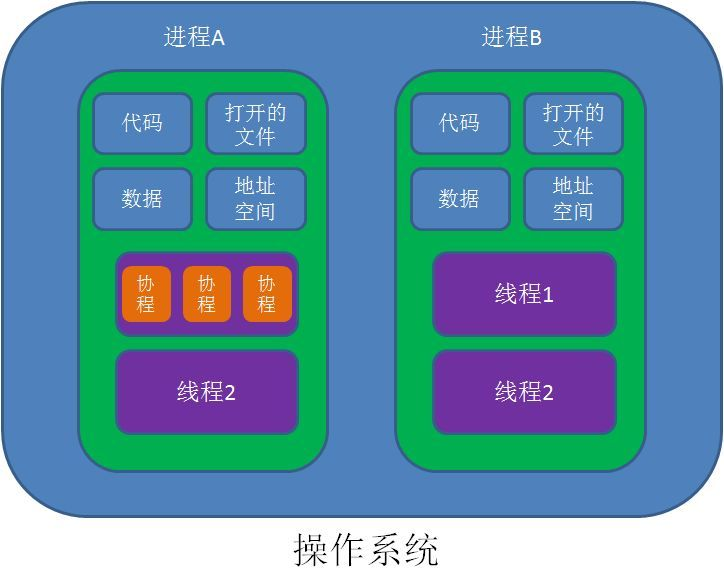
最重要的是,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行,操作系统运行分为内核态和用户态,切换的时候也会涉及资源消耗)。
这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
既然协程这么好,它到底是怎么来使用的呢?
由于Java的原生语法中并没有实现协程(某些开源框架实现了协程,但是很少被使用),所以我们来看一看python当中对协程的实现案例,同样以生产者消费者模式为例:

这段代码十分简单,即使没用过python的小伙伴应该也能基本看懂。
代码中创建了一个叫做consumer的协程,并且在主线程中生产数据,协程中消费数据。
其中 yield 是python当中的语法。当协程执行到yield关键字时,会暂停在那一行,等到主线程调用send方法发送了数据,协程才会接到数据继续执行。
但是,yield让协程暂停,和线程的阻塞是有本质区别的。协程的暂停完全由程序控制,线程的阻塞状态是由操作系统内核来进行切换。
因此,协程的开销远远小于线程的开销。
参考
百度百科
什么是协程



还没有评论,来说两句吧...