
ES的读取分为GET和Search两种操作,这两种读取操作有较大的差异,本章我们主要分析下GET/MGET读取操作。
GET/MGET
GET/MGET必须指定三元组:_index、_type、_id(http://127.0.0.1:9200/_index/_type/_id),也就是说,根据文档id从正排索引中获取内容。GET操作只能对单个文档进行处理,MGET是对GET的进一步封装(封装了多个GET请求),由_index,_type,_id三元组来确定唯一文档。
http://127.0.0.1:9200/_index/_type/_id -> 相应的文档
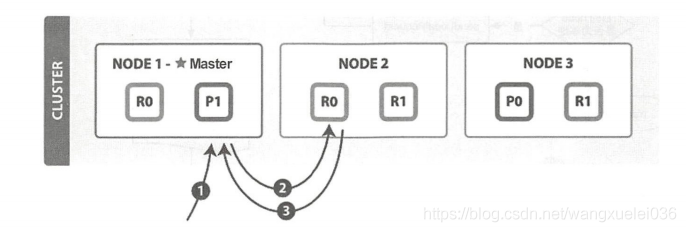
GET请求流程如下:
(1)客户端向NODE1发送读请求(此时NODE1作为协调节点)
(2)NODE1是同文档ID来确定文档属于分片0,通过集群状态中的内容路由表信息获取分片0有三个副本数据,位于三个节点中,此时它可以通过将请求发送到任意节点,图上所示是将请求发送到NODE2。
(3)NODE2将文档返回给NODE1,NODE1将文档返回给客户端(因为只是获取单个数据信息,不会涉及协调节点的聚合等操作)
注:GET/MGET详细的设计原理可以参考:ES GET/MGET 设计理解
注:ElasticSearch中同时保存了正排索引和倒排索引,对该知识不清楚的可以参考:
?思考:那么对于一些复杂的操作,而且不知道文档ID,应该如何进行查询?
这也是我们下面所讲的Search操作。
Search操作
ES中的数据可以分为两类:
- 精确值:比如日期和用户id,ip等信息
- 全文:☞文章内容,比如一跳日志,或者邮件的内容。
这两种类型的数据在查询的时候也是不相同的:对精确值的比较是二进制,查询要么匹配,要么不匹配;全文内容的查询无法给出“有”还是“没有”的结果,它只能找到结果是“看起来像”你要查询的东西,因此把查询结果按相似度排序,评分越高,相似度越大
大致流程如下:
(1)客户端发送请求协调节点
(2)因为查询的时候不知道文档位于哪个分片,因此索引的所有分片(某个副本)都要参与搜索,调节点计算出索引的分片位置进行搜索(也就是查询阶段)。
(3)协调节点进行结果合并,根据获取到返回的文档ID,再次访问并获取文档内容。比如:有5个分片,查询前10个匹配度最高的文档,那么每个分片都能查询出分片的TOP10,协调节点将5*10=50的结果再次排序,返回最红TOP10的结果给客户。
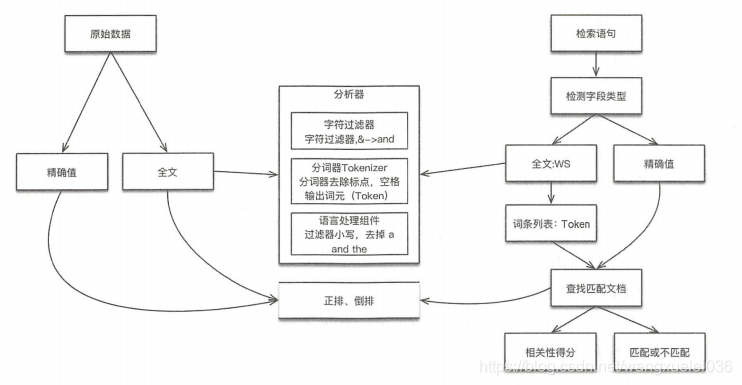
ES对数据建立索引和执行搜索的原理如下图:
建立索引
如果是全文数据,则对文本内容进行分析,这项工作在ES中由分析器实现。分析器实现如下:
(1)字符过滤器。主要针对字符串进行预处理,比如:去掉HTML,将&转换为and等
(2)分词器(Tokenizer)。将字符串分割为单个词条,例如,根据空格和标点符号分割(ES内置了很多分词器,也可以自定义),输出的词条称为词元(Token)
(3)Token过滤器(分词过滤器)。这些分词过滤器将一个词元作为输入,根据需要进行修改,添加或者是删除。最为有用的和常用的分词过滤器是小写分词过滤器(将输入的分词变为小写,搜索词条“nosql”的时候,可以发现关于“NoSql”的聚合),分词过滤器还可以删除像“and”等常用词,也可以将“tools”作为“technologies”的同义词进行添加
(4)建立分词索引:当分词经历了零个或者多个分词过滤器,他们将被发送到Lucene进行文档的索引。这些分词组将组成倒排索引
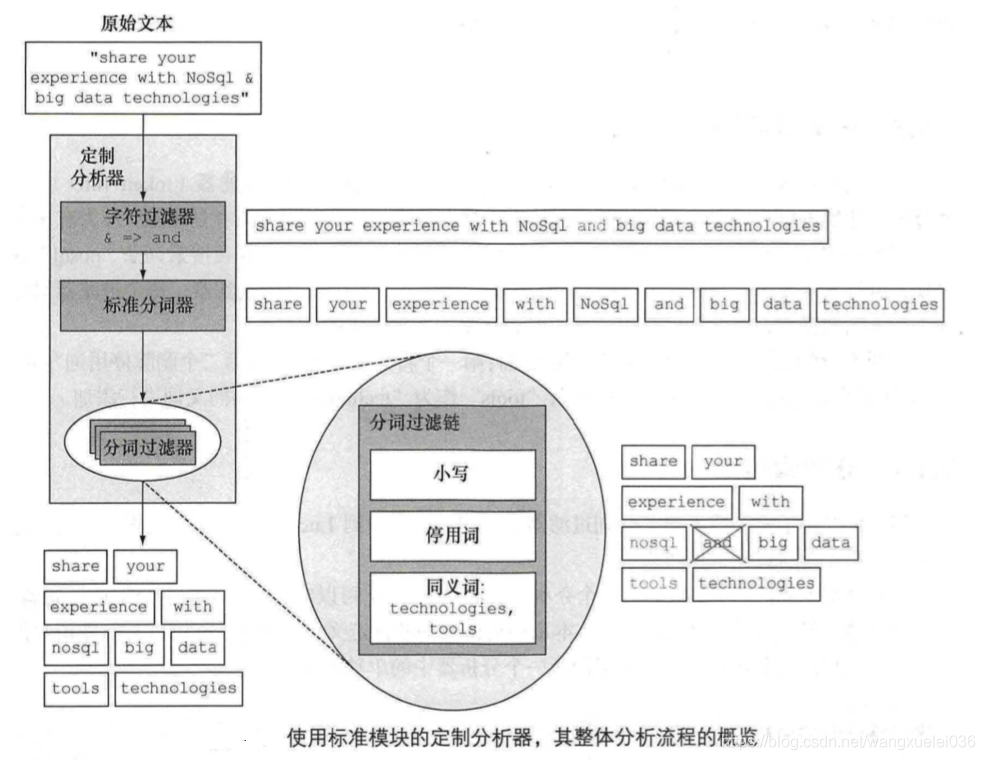 注:在搜索在索引中执行之前,根据所使用的查询类型,分析统一可以运用到搜索的文本
注:在搜索在索引中执行之前,根据所使用的查询类型,分析统一可以运用到搜索的文本
搜索建立
搜索调用Lucene 完成,如果是全文搜索,则:
(1)对检索字段使用建立索引时相同的分析器进行分析,产生Token列表;
(2)根据查询语句的语法规则转换成一个语法树
(3)查找符合语法树的文档
(4)对匹配到的文档列表进行相关性评分,评分策略一般使用TF/IDF
(5)根据评分结果进行排序
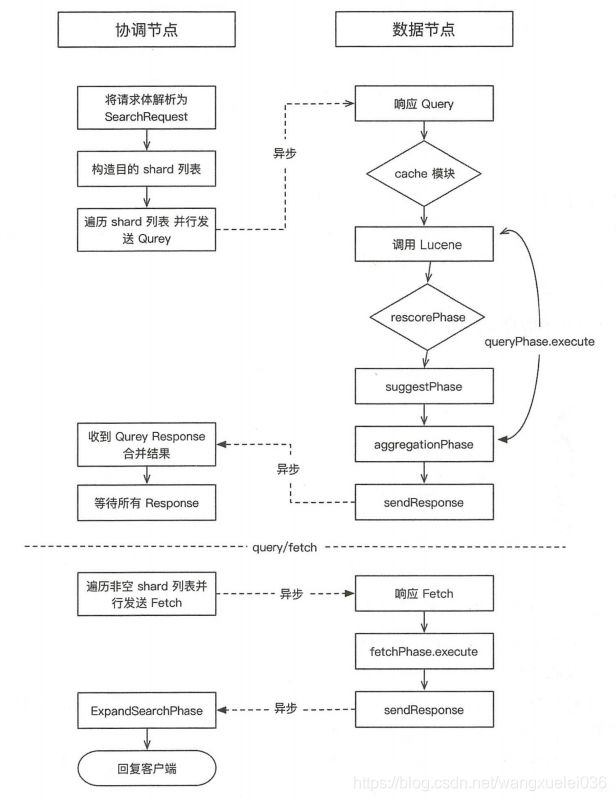
整个搜索过程分为两个步骤:query 和 fetch ,整体流程如下图所示:
query阶段
在初始查询阶段,查询会广播到索引中每一个分片副本(主分片或副分片)。每个分片在本地执行搜索并构建一个匹配文档的优先队列(优先队列是一个由topN匹配文档的有序列表。优先队列大小为分页参数from+size)。
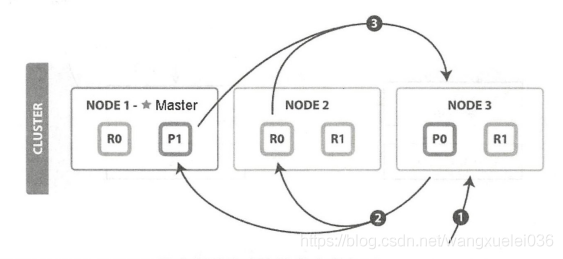
(1)客户端发送search请求到NODE3。
(2)Node3将查询请求转发到索引的每个主分片或者副分片
(3)每个分片在本地执行查询,并使用本地的Term/Document Frequency信息进行打分,添加结果到大小为from + size的本地有序优先队列中。
(4)每个分片返回个自己优先队列中所有文档的ID和排序值给协调节点,协调节点合并这些值到自己的优先队列中,产生一个全局排序后的列表
注:查询阶段并不会对搜索请求的内容进行解析,无论搜索什么内容,只看本次搜索需要命重哪些shard,然后针对每个特定shard选择一个复杂,转发搜索请求
Fetch 阶段
Query阶段知道了要取哪些数据,但是并没有获取具体的数据,这个步骤在Fetch阶段实现
Fetch阶段如图:
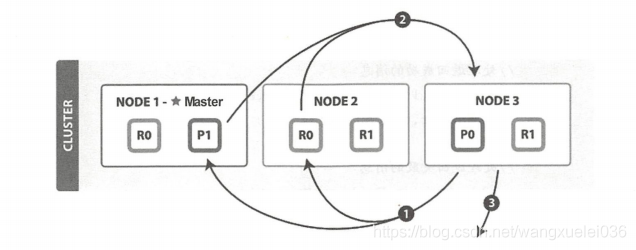
Fetch阶段由以下步骤完成:
(1)协调节点向相关NODE发送GET请求。
(2)分片所在节点向协调节点返回数据。
(3)协调节点等待所有文档被取得,然后返回给客户端
注:聚合时在ES中实现的,而非Lucene
")



还没有评论,来说两句吧...