
ES的读取分为GET和Search两种操作,这两种读取操作有较大的差异,本章我们主要分析下GET/MGET读取操作。
GET/MGET必须指定三元组:_index、_type、_id(http://127.0.0.1:9200/_index/_type/_id),也就是说,根据文档id从正排索引中获取内容。
注:ElasticSearch中同时保存了正排索引和倒排索引,对该知识不清楚的可以参考:
GET基本流程
搜索和读取文档都属于读操作,可以从主分片或副分片中读取数据。
读取单个文档的流程(图片来自官网)可如下图:
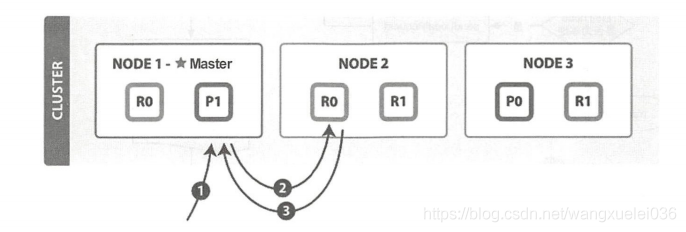
注:其中P->primary shard(主分片),R->replication shard (副分片)
步骤如下:
(1)客户端向NODE1发送读请求(此时NODE1作为协调节点)
(2)NODE1是同文档ID来确定文档属于分片0,通过集群状态中的内容路由表信息获取分片0有三个副本数据,位于三个节点中,此时它可以通过将请求发送到任意节点,图上所示是将请求发送到NODE2。
(3)NODE2将文档返回给NODE1,NODE1将文档返回给客户端(因为只是获取单个数据信息,不会涉及协调节点的聚合等操作)
注:NODE1在此流程中作为协调节点,将客户端请求轮询发送到集群的所有副本来实现负载均衡
了解ElasticSearch中节点角色也是很重要的,对节点角色不清楚的,可以参考:
?思考:如果副分片还没来得及同步主分片的最新数据或者其他原因导致还未同步怎么办?
在读取时,如果文档可能以及存在于主分片,但是还没有复制到副分片。在这种情况下,读请求命重副分片时可能会报告文档不存在,但是命中主分片可能成功返回文档,一旦写请求成功返回给客户端,则意味着文档正在主分片和副分片都是可用的。
下面我们展示下GET详细的流程图:
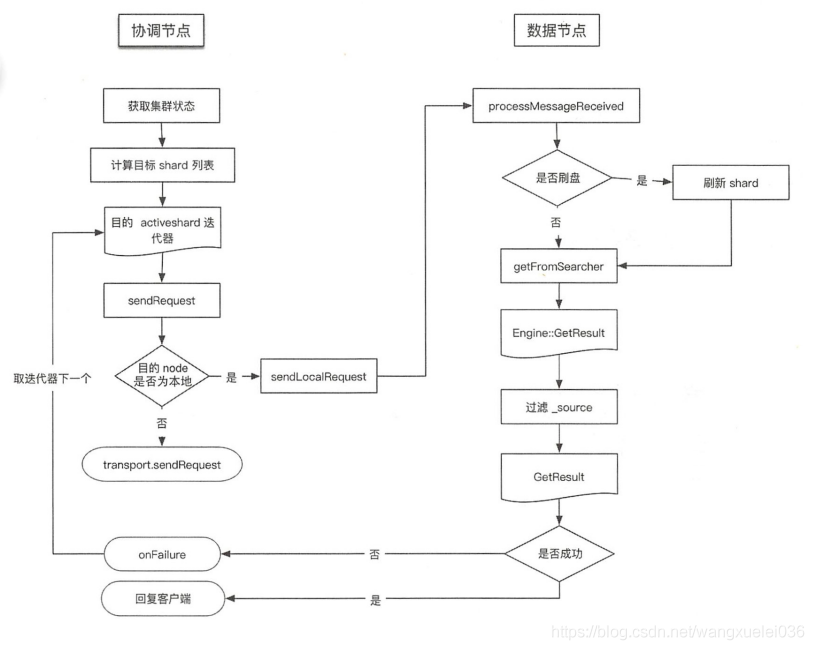
以上我们展示了单个GET获取数据的流程,那么MGET又是什么?
MGET
MGET批量查询,通过封装了单个GET请求实现,处理流程如下:
(1)遍历请求,计算每个doc的路由信息,得到由shardId为key组成的request map。这个过程并没有在TransportSingleShardAction中实现,避免shardId会重复,这也是合并为基于分片的请求过程。
(2)循环处理组织好的每个shard级请求,调用处理GET请求时使用TransportSingleShardAction#AsyncSingleAction处理单个doc(也就是异步调用GET逻辑处理业务)
(3)收集Response,全部Response返回后执行finishHim,可客户端返回结果。
?思考:如果MGET一部分成功,一部分失败怎么办?
同一个批量操作中各项操作时相互独立的(每个操作都会返回一个请求回复,而不是整个批量操作返回一个单独的回复),因此如果部分文档读取失败,则不影响其他结果,检索失败的doc会在回复信息中标出
设计性能的时候,批量的大小很关键,如果批量数据过大,那么他们就会占用过多的内存。如果批量太小,多次请求,网络开销就会变大,最佳的平衡点,取决于文档的大小->如果文档很大,每个批量处理中就少放几篇,如果文档很小,就多放几篇,根据实际项目来判定
下图为示意图:
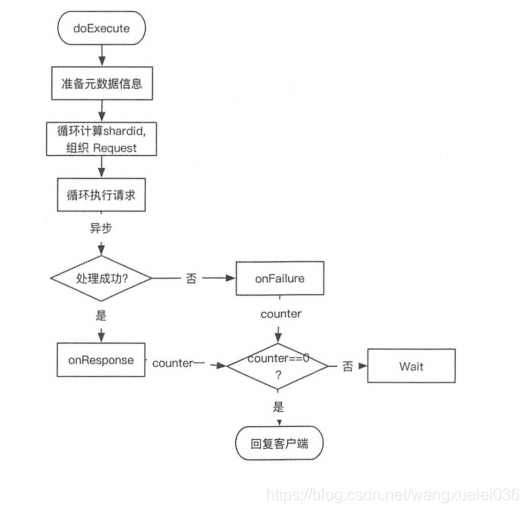
MGET还是很重要的,一般来说,进行查询的时候,如果一次性查询多条数据的话,那么一定要用batch批量操作的api(MGET),尽可能减少网络开销次数,可能可以将性能提升数倍,甚至十倍,非常重要。
GET API默认是实时的,实时的意思是写完了可以立即读取,但仅限于GET,MGET操作,不包括搜索(search)操作。在5.x版本之前,GET/MGET的实时读取依赖于从translog中读取实现,5.x版本之后改为了refresh,因此系统对实时读取的支持会对写入速度有负面影响
")



还没有评论,来说两句吧...