
2021最新Java面试题【附答案解析】java面试题及答案2021,java2021最新面试题及答案汇总,2021最Java面试题新答案已经全部更新完了,有些答案是自己总结的,也有些答案是在网上搜集整理的java面试题及答案汇总。这些答案难免会存在一些错误,仅供大家参考。如果发现错误还望大家多多包涵,不吝赐教,谢谢~
其实,博主还整理了,更多大厂面试题,直接下载吧
下载链接:高清172份,累计 7701 页大厂面试题 PDF
1、你有哪些手段来排查 OOM 的问题?
1、 增加两个参数 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof,当 OOM 发生时自动 dump 堆内存信息到指定目录
2、 同时 jstat 查看监控 JVM 的内存和 GC 情况,先观察问题大概出在什么区域
3、 使用 MAT 工具载入到 dump 文件,分析大对象的占用情况,比如 HashMap 做缓存未清理,时间长了就会内存溢出,可以把改为弱引用
2、单例模式了解吗?给我解释一下双重检验锁方式实现单例模式!”
双重校验锁实现对象单例(线程安全)
说明:
双锁机制的出现是为了解决前面同步问题和性能问题,看下面的代码,简单分析下确实是解决了多线程并行进来不会出现重复new对象,而且也实现了懒加载
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
//先判断对象是否已经实例过,没有实例化过才进入加锁代码
if (uniqueInstance == null) {
//类对象加锁
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
另外,需要注意 uniqueInstance 采用 volatile 关键字修饰也是很有必要。
uniqueInstance 采用 volatile 关键字修饰也是很有必要的, uniqueInstance = new Singleton(); 这段代码其实是分为三步执行:
1、 为 uniqueInstance 分配内存空间
2、 初始化 uniqueInstance
3、 将 uniqueInstance 指向分配的内存地址
但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 getUniqueInstance() 后发现 uniqueInstance 不为空,因此返回 uniqueInstance,但此时 uniqueInstance 还未被初始化。
使用 volatile 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
3、如何使session失效
Session.invalidate()
4、Java 中 LinkedHashMap 和 PriorityQueue 的区别是什么?
PriorityQueue 保证最高或者最低优先级的的元素总是在队列头部,但是 LinkedHashMap 维持的顺序是元素插入的顺序。当遍历一个 PriorityQueue 时,没有任何顺序保证,但是 LinkedHashMap 课保证遍历顺序是元素插入的顺序。
5、单例模式使用注意事项:
1、 使用时不能用反射模式创建单例,否则会实例化一个新的对象
2、 使用懒单例模式时注意线程安全问题
3、 饿单例模式和懒单例模式构造方法都是私有的,因而是不能被继承的,有些单例模式可以被继承(如登记式模式)
6、HashMap在JDK1.7和JDK1.8中有哪些不同?HashMap的底层实现
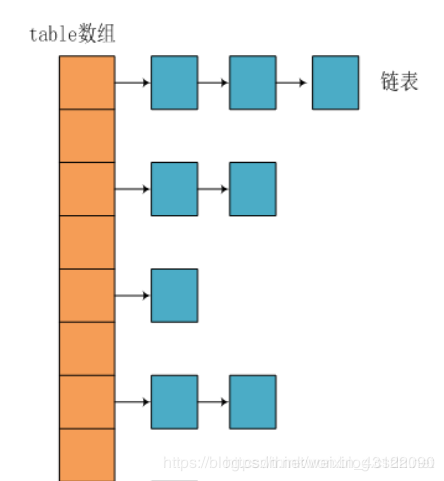
在Java中,保存数据有两种比较简单的数据结构:数组和链表。数组的特点是:寻址容易,插入和删除困难;链表的特点是:寻址困难,但插入和删除容易;所以我们将数组和链表结合在一起,发挥两者各自的优势,使用一种叫做拉链法的方式可以解决哈希冲突。
HashMap JDK1.8之前
JDK1.8之前采用的是拉链法。拉链法:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
HashMap JDK1.8之后
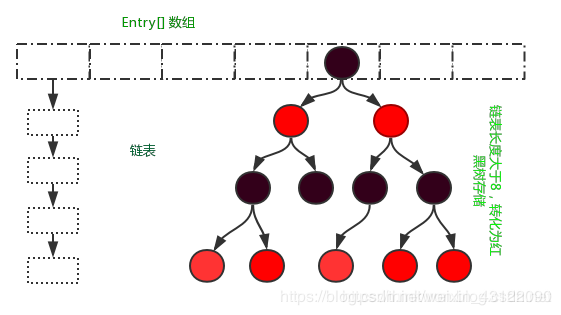
相比于之前的版本,jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
JDK1.7 VS JDK1.8 比较
JDK1.8主要解决或优化了一下问题:
1、 resize 扩容优化
2、 引入了红黑树,目的是避免单条链表过长而影响查询效率,红黑树算法请参考
3、 解决了多线程死循环问题,但仍是非线程安全的,多线程时可能会造成数据丢失问题。
| 不同 | JDK 1.7 | JDK 1.8 |
|---|---|---|
| 存储结构 | 数组 + 链表 | 数组 + 链表 + 红黑树 |
| 初始化方式 | 单独函数:inflateTable() | 直接集成到了扩容函数resize()中 |
| hash值计算方式 | 扰动处理 = 9次扰动 = 4次位运算 + 5次异或运算 | 扰动处理 = 2次扰动 = 1次位运算 + 1次异或运算 |
| 存放数据的规则 | 无冲突时,存放数组;冲突时,存放链表 | 无冲突时,存放数组;冲突 & 链表长度 < 8:存放单链表;冲突 & 链表长度 > 8:树化并存放红黑树 |
| 插入数据方式 | 头插法(先讲原位置的数据移到后1位,再插入数据到该位置) | 尾插法(直接插入到链表尾部/红黑树) |
| 扩容后存储位置的计算方式 | 全部按照原来方法进行计算(即hashCode ->> 扰动函数 ->> (h&length-1)) | 按照扩容后的规律计算(即扩容后的位置=原位置 or 原位置 + 旧容量) |
7、HashMap 与 HashTable 有什么区别?
1、 线程安全: HashMap 是非线程安全的,HashTable 是线程安全的;HashTable 内部的方法基本都经过 synchronized 修饰。(如果你要保证线程安全的话就使用 ConcurrentHashMap );
2、 效率: 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;(如果你要保证线程安全的话就使用 ConcurrentHashMap );
3、 对Null key 和Null value的支持: HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。但是在 HashTable 中 put 进的键值只要有一个 null,直接抛NullPointerException。
4、 初始容量大小和每次扩充容量大小的不同 :
1、 创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。
2、 创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小。也就是说 HashMap 总是使用2的幂作为哈希表的大小,后面会介绍到为什么是2的幂次方。
底层数据结构:
JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
推荐使用:
在 Hashtable 的类注释可以看到,Hashtable 是保留类不建议使用,推荐在单线程环境下使用 HashMap 替代,如果需要多线程使用则用 ConcurrentHashMap 替代。
8、Java应用程序与小程序之间有那些差别?
简单说应用程序是从主线程启动(也就是main()方法)。applet小程序没有main方法,主要是嵌在浏览器页面上运行(调用init()线程或者run()来启动),嵌入浏览器这点跟flash的小游戏类似。
9、使用集合框架的好处
1、 容量自增长;
2、 提供了高性能的数据结构和算法,使编码更轻松,提高了程序速度和质量;
3、 可以方便地扩展或改写集合,提高代码复用性和可操作性。
4、 通过使用JDK自带的集合类,可以降低代码维护和学习新API成本。
10、Java 中,怎样才能打印出数组中的重复元素?
解决方案
http://Javarevisited.blogspot.com/2015/06/3-ways-to-find-duplicate-elements-in-array-Java.html

还没有评论,来说两句吧...