
前言
在使用PXC架构做mysql集群时,线上出现过一次PXC脑裂的故障,通过问题排查,分析与定位,最终针对这个问题以及解决方法做一次记录
脑裂现象表现
1、产品访问MySQL,出现数据不一致的情况(脑裂后一个集群分裂成两个独立的集群,如PXC前置是通过LVS架构访问,当VIP发生漂移会导致前后访问的集群不一致)
2、出现脑裂时无法进行读写操作
3、 登录生产机器,通过执行命令,show status like ‘%wsrep%’,命令,wsrep_cluster_status 的状态为 non-primary(脑裂状态)且 wsrep_incoming_addresses 的节点地址与部署的节点地址保持一致,如下:显示出来的问题如下图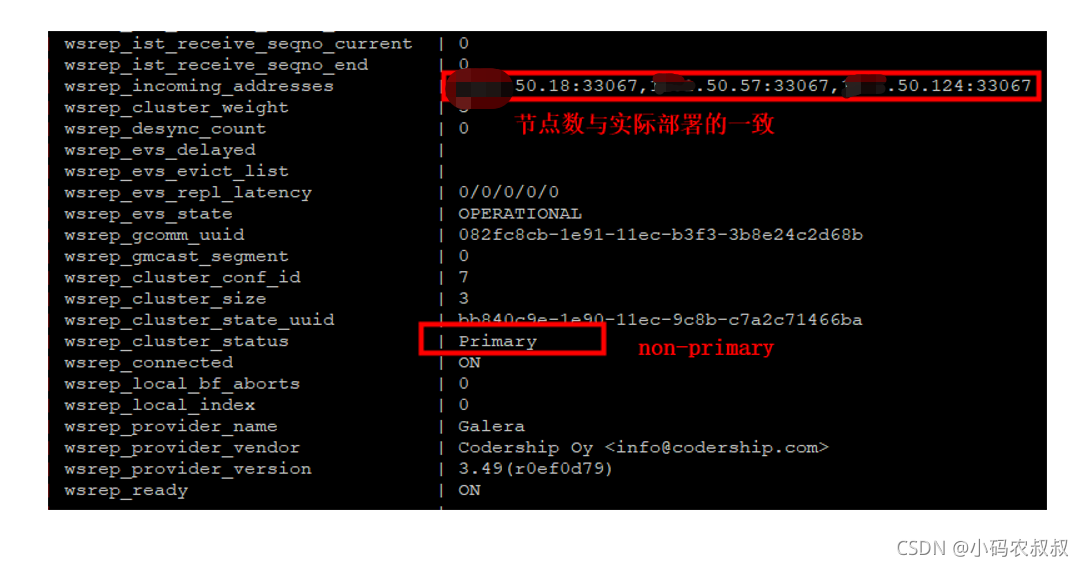
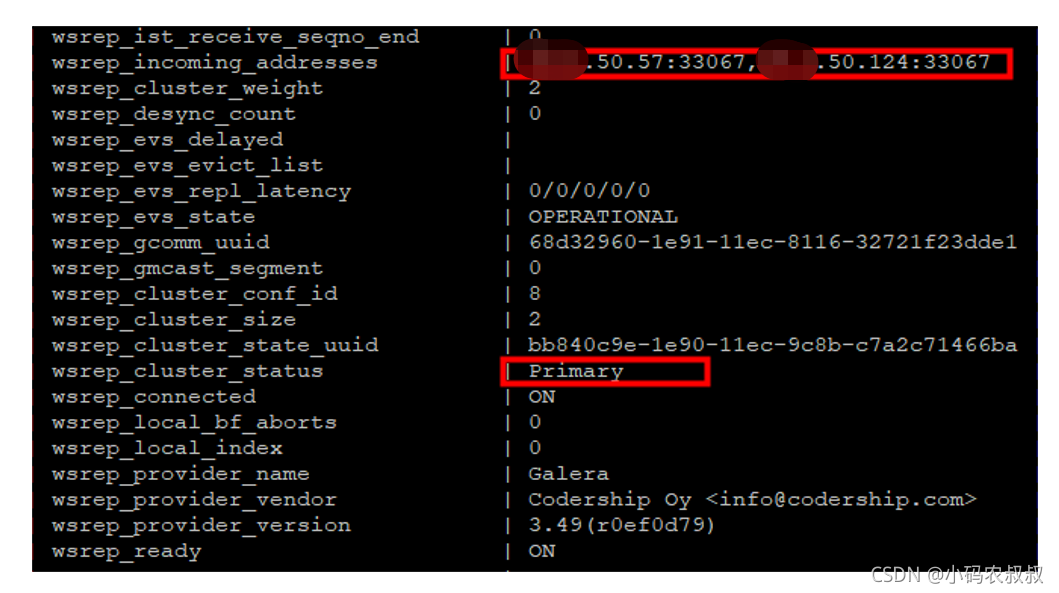
登录MySQL,执行 show status like ‘%wsrep%’; 命令,wsrep_cluster_status 的状态为 primary 且 wsrep_incoming_addresses 的节点地址与部署的节点地址不一致,如下: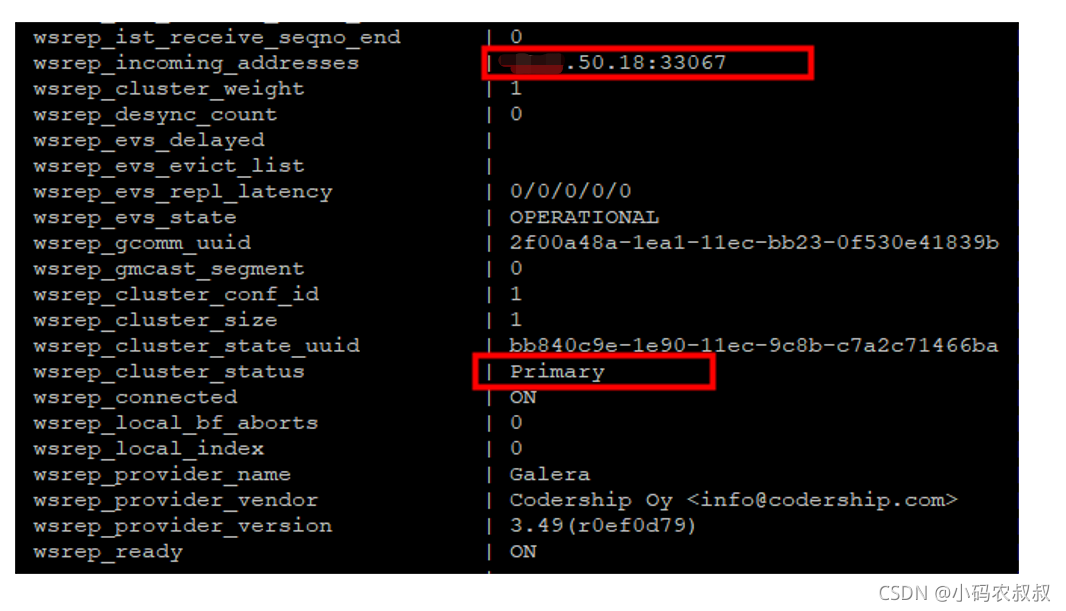
现象1、2为表现,最终都能体现在 2 或 3 上
原因分析
开启了selinux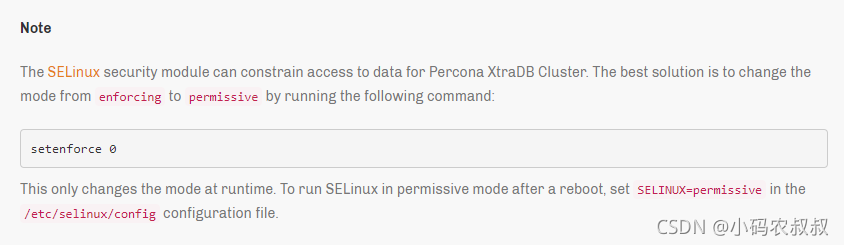
分析入手点:
网络原因
PXC集群内部通过 4567 端口来监听组员状态及组员之间的通信(握手,鉴权,广播,写入集的复制),如果网络不畅、丢包严重会导致各节点无法持续获取其他的节点的状态,并最终从集群中剔除分裂为两个集群。该情况通过 show status like ‘%wsrep%’; 查看,会发现 wsrep_evs_delayed 非空并显示延迟节点的信息
服务器负载高
本质也是导致 4567 端口监听失败,因为负载或IO持续过高(过高经验值:uptime > cpu_cores*0.7),会导致socket连接失败或超时
批量启动时指定引导节点启动
正常情况初始安装,第一个节点启动是以引导模式启动,接下来的其他节点以非引导模式启动并以引导节点的数据为准进行同步(待所有节点加入集群后无引导非引导节点之分)。后续如果涉及到节点的停止,最后一个停止的节点 PXC 自动会将其标识为引导节点,后续启动时需先启动引导节点再启动其他节点(因为最后停止的节点数据最全所以将其标识为引导节点,极端情况如断电,可能会导致集群所有节点均为非引导节点,这种情况就需要显示指定一个节点为引导节点启动 sh
处理过程
1、环境检查
如果开启了 selinux,关闭 selinux,root账户执行如下命令
sed -i "s/^SELINUX=.*/SELINUX=disabled/g" /etc/selinux/config
sudo setenforce 0
如网络有问题,需会同现场运维人员进行排查并及时解决
2、备份各节点数据
如通过 mysql_bak.sh 备份失败,可通过 mysqlkit_5.7.tgz 做一次全量备份及binlog备份
3、启停节点
如是现象4(wsrep_cluster_status 的状态为 primary 且 wsrep_incoming_addresses 的节点地址与部署的节点地址不一致),停止非 VIP 所在机器节点然后以 normal 方式进行启动;如是2、3(wsrep_cluster_status 的状态为 non-primary(脑裂状态)且 wsrep_incoming_addresses 的节点地址与部署的节点地址保持一致),可先停止其他节点只保留一个节点对外提供服,然后以 normal 方式重启停止的节点
注意事项
如果脑裂时间持续较长且期间出现了VIP漂移的情况(数据写入到不同节点但集群内部数据同步失败),恢复可能会出现数据不一致的情况,如出现改情况需要及时会同研发和运维同事先做数据恢复工作




还没有评论,来说两句吧...