
前言
在某些业务场景下,需要对原始的数据进行合理的分类输出,减少后续的程序处理数据带来的麻烦,其实这也属于ETL中的一种,比如,我们收集到了一份原始的日志,主体字段为区域编码,需要根据这个编码将这份日志分割输出到不同的文件中
在前面的一篇自定义分区中,可以将原始的文件在自定义的Partioner类中结合实际业务需求,将数据最终输出到不同的分区文件下,这属于一种解决方案,但使用这种方式也有一定的弊端,因为分区数量增大了,必然带来MapTask 数量的增加,带来的是服务器资源的更多开销
与分区输出不同的是,自定义OutputFormat更加灵活,相当于是MapReduce之外的扩展,可以在自定义OutputFormat中编写更复杂的业务逻辑定制化业务场景,同时,更重要的是,真正做到按照业务字段,将原始的文件最终输出到不同的文件中去。
OutputFormat使用场景
输出数据到中间件,例如mysql,es,hbase等
自定义OutputFormat步骤
- 自定义一个OutputFormat类
- 重写里面的RecordWriter方法,具体改造输出数据的write方法
业务场景
有下面的一个日志文件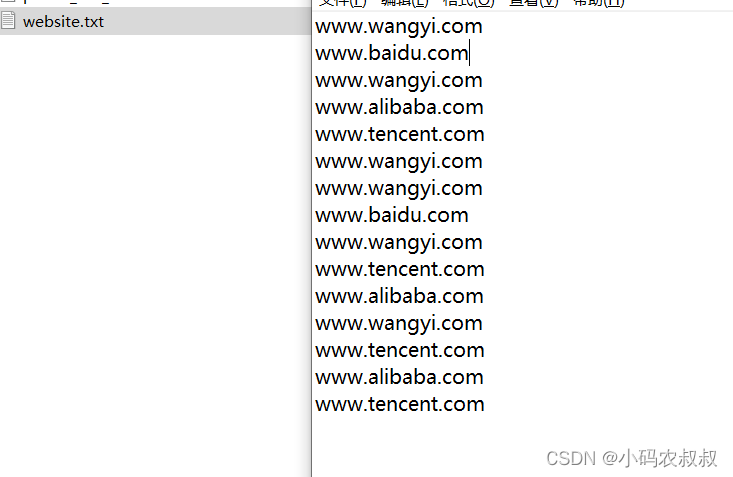
需求是,将这份文件中,包含 "www.wangyi.com"的内容输出到一个文件,其他的输出到另一个文件
编码实现
1、自定义Mapper类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class LogMapper extends Mapper<LongWritable,Text,Text,NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value,NullWritable.get());
}
}
2、自定义Reduce类
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class LogReducer extends Reducer<Text,NullWritable,Text,NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
for (NullWritable nullWritable : values){
context.write(key,NullWritable.get());
}
}
}
3、自定义OutputFormat类
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class LogOutputFormat extends FileOutputFormat<Text,NullWritable> {
@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
LogRecordWriter recordWriter = new LogRecordWriter(taskAttemptContext);
return recordWriter;
}
}
LogRecordWriter
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import java.io.IOException;
public class LogRecordWriter extends RecordWriter<Text,NullWritable> {
private FSDataOutputStream data1 ;
private FSDataOutputStream data2 ;
public LogRecordWriter(TaskAttemptContext context){
try {
FileSystem fileSystem = FileSystem.get(context.getConfiguration());
data1 = fileSystem.create(new Path("F:\\网盘\\csv\\logs\\wangyi.log"));
data2 = fileSystem.create(new Path("F:\\网盘\\csv\\logs\\other.log"));
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 执行写逻辑
* @param text
* @param nullWritable
* @throws IOException
* @throws InterruptedException
*/
@Override
public void write(Text text, NullWritable nullWritable) throws IOException, InterruptedException {
String value = text.toString();
if(value.trim().contains("www.wangyi.com")){
data1.writeBytes(value.trim() + "\n");
}else {
data2.writeBytes(value.trim() + "\n");
}
}
@Override
public void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
IOUtils.closeStream(data1);
IOUtils.closeStream(data2);
}
}
4、job类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LogJob {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(LogJob.class);
job.setMapperClass(LogMapper.class);
job.setReducerClass(LogReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置自定义的outputformat
job.setOutputFormatClass(LogOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path("F:\\网盘\\csv\\website.txt"));
//虽然我们自定义了outputformat,但是因为我们的outputformat继承自fileoutputformat
//而fileoutputformat要输出一个_SUCCESS文件,所以在这还得指定一个输出目录
FileOutputFormat.setOutputPath(job, new Path("F:\\网盘\\csv\\logs"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
运行上面的程序,观察输出目录文件,这样就可以满足上面的需求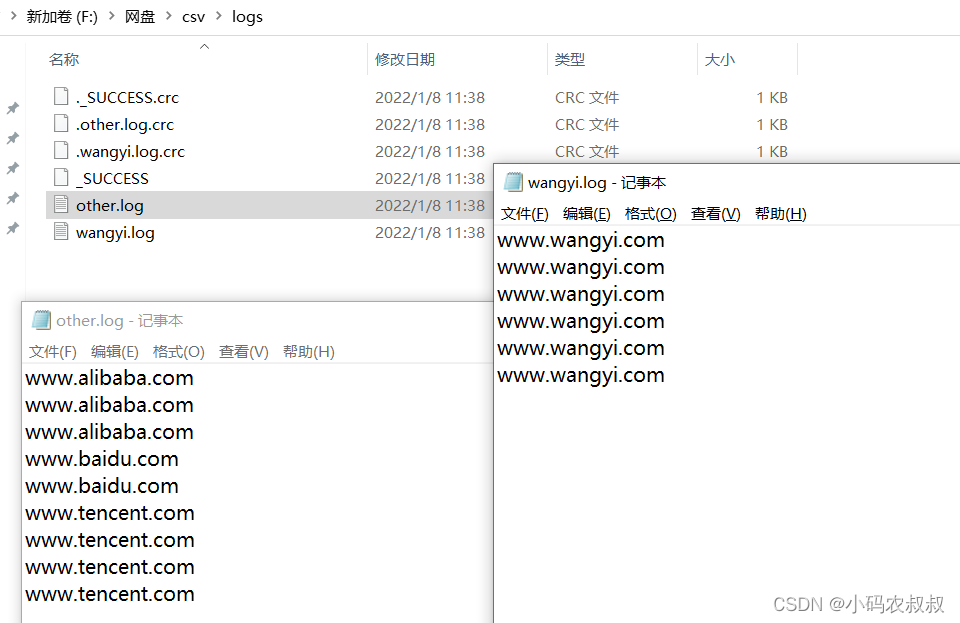
本文标题:hadoop 自定义OutputFormat
本文链接:https://blog.quwenai.cn/post/2063.html
版权声明:本文不使用任何协议授权,您可以任何形式自由转载或使用。



")
还没有评论,来说两句吧...