
开局先来一张某位大哥的图: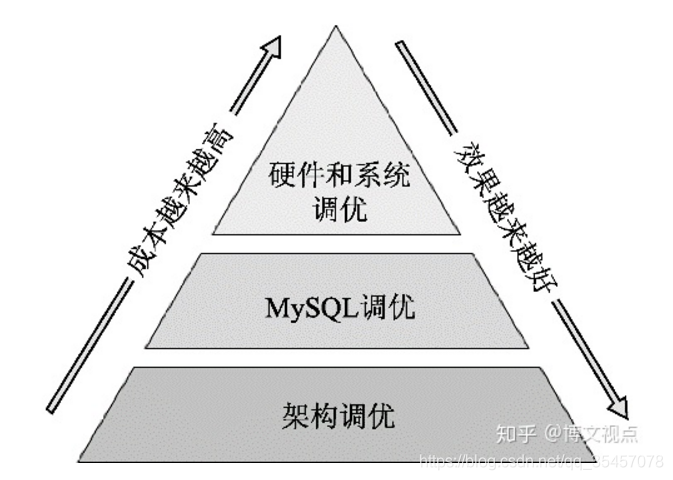
一. 表设计与数据类型
- 尽量遵循数据库设计三大范式,一些场景可适当建立冗余字段,减少连接查询,但这样这样会破坏第三范式,视情况而定。
- 尽量不要设置null类型字段,null类型需要额外的字段来存储,count不会统计,一些场景也会使索引失效。
- 使用UNSIGNED无符号类型,可提高正数的数量上限,在一些不需要存储负数的情况下,将类型设置无符号数。
- 没有太大的必要使用BigDecimal类型,可用bigint,将小数方法10^n存入,这样可以避免浮点数计算不准确和DECIMAL精确计算代价高的问题。
- 表中的列不要太多,如果列太多而实际使用的列又很少的话,有可能会导致CPU占用过高。
- 把IP地址存成 UNSIGNEDINT,IP地址转换成int类型正好是int的有符号取整范围
- 设置固定长度的字段会提高性能,因为MySQL搜寻得会更快一些,因为这些固定的长度是很容易计算下一个数据的偏移量的,所以读取的自然也会很快。而如果字段不是定长的,那么,每一次要找下一条的话,需要程序找到主键。但是固定长度的字段会浪费一些空间
- url 可以将数据倒序存入数据库,或者字符串进行crc32哈希处理
- 分库分表
二. 索引
- 创建适当数量的索引,在创建表的时候就创建好索引,尽量避免在表中有大量数据的时候创建索引。
- 合适的场景创建覆盖索引
- 在区分度高的字段上建立索引
- 控制单个索引的长度,如key(name(8))
- 尽量使用自增id
- 在数据不会重复的列上建立唯一索引
三. SQL
- 每一条sql都尽量使用explain查看执行计划,防止慢sql出现
- 遵循符合索引最左匹配原则
- 尽量不要在索引列上做表达式运算,或使用函数,会使索引失效
- 尽量不要使用多个范围查询,会使索引失效
- 查看执行计划,如果索引的使用优化器优化有问题,可以强制使用想要适应的索引force index
- or查询用union优化代替,如果是相同字段的or,优化为in查询
- 数据类型出现隐式转换的时候不会命中索引,特别是当列类型是字符串,一定要将字符常量值用引号引起来。
- like查询尽量使用左匹配
- join查询,on连接的字段上一定要建立索引
- 避免select *,避免返回无用字段
- insert批量插入,不要单条插入
- 当仅需要获取一条数据时,使用limit 1
四. 程序层面
- 使用数据库连接池连接数据库
- 使用缓存对查询数据做缓存,如MyBatis的一二级缓存、redis缓存
五. innodb参数
-
max_connections:允许客户端并发连接的最大数量,默认值是151,一般将该参数设置为300-1000
-
max_connect_errors:如果客户端尝试连接的错误数量超过这个参数设置的值,则服务器不再接受新的客户端连接。可以通过清空主机的缓存来解除服务器的这种阻止新连接的状态,通过FLUSH HOSTS或mysqladmin flush-hosts命令来清空缓存。这个参数的默认值是100,一般将该参数设置为100000。
-
innodb_buffer_pool_size 缓存索引和行数据,在专属mysql服务器上,可设置为内存的80%左右,可减少索引存储在磁盘上,减少IO
-
innodb_thread_concurrency(5.7版本中已废除) InnoDB内核中允许的线程数,这个值取决于,硬件,应用,OS scheduler properties,设置的太高会线程上下文切换频繁,降低效率,所以不要设置的太高。推荐4核4线程(4C4T)值设置为4-8即可,最大不建议超过线程数*2
-
innodb_write_io_threads: 限制写相关的线程,缺省值为4
-
innodb_read_io_threads: 限制写相关的线程,缺省值为4
还有很多其他相关参数,可视情况设置。
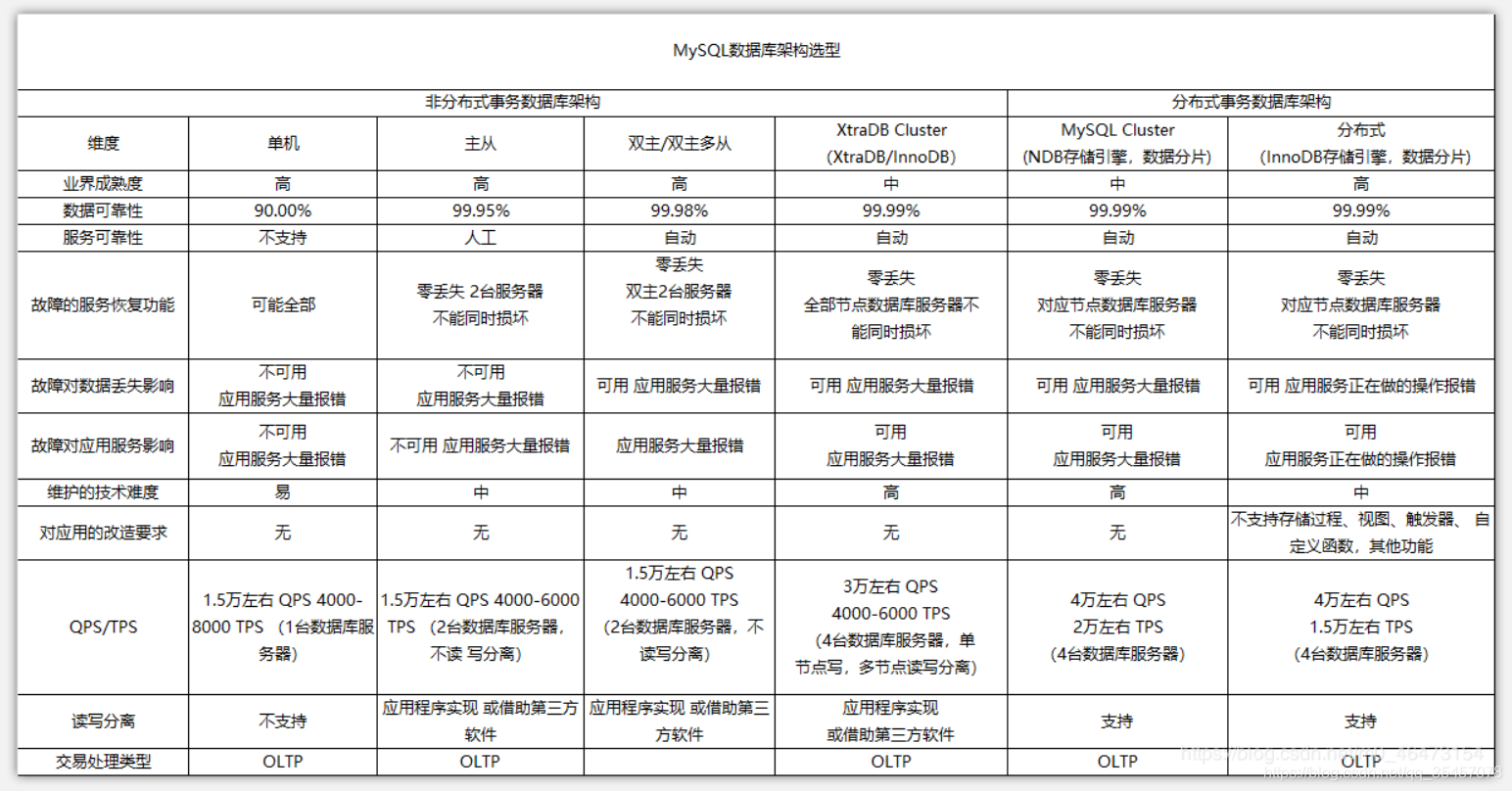
六. 架构
- 主从架构,读写分离。
- 参考如下:
本文标题:MySQL调优总结
本文链接:https://blog.quwenai.cn/post/1887.html
版权声明:本文不使用任何协议授权,您可以任何形式自由转载或使用。




还没有评论,来说两句吧...