

消费上为了高效地查询数据库中的数据,我们常常会给表中的字段添加索引,各人能否有考虑过若何添加索引才气使索引更高效,考虑如下问题
添加的索引是越多越好吗为啥有时候明明添加了索引却不生效索引有哪些类型若何评判一个索引设想的好坏看了本文相信你会对索引的原理有更明晰的认识。本文将会从以下几个方面来讲述索引的相关常识,相信各人耐心看了之后必定有收成。
什么是索引,索引的感化索引的品种高性能索引战略索引设想原则:三星索引什么是索引,索引的感化当我们要在新华字典里查某个字(如「先」)详细含义的时候,凡是城市拿起一本新华字典来查,你能够先从头至尾查询每一页能否有「先」那个字,如许做(对应数据库中的全表扫描)确实能找到,但效率无疑长短常低下的,更高效的方相信各人也都晓得,就是在首页的索引里先查找「先」对应的页数,然后间接跳到响应的页面查找,如许查询时候大大削减了,能够为是 O(1)。

数据库中的索引也是类似的,通过索引定位到要读取的页,大大削减了需要扫描的行数,能极大的提拔效率,简而言之,索引次要有以下几个感化
即上述所说,索引能极大地削减扫描行数索引能够帮忙办事器制止排序和临时表索引能够将随机 IO 酿成挨次 IO第一点上文已经解释了,我们来看下第二点和第三点
先来看第二点,假设我们不消索引,试想运行如下语句
SELECT * FROM user order by age desc;则 MySQL 的流程是如许的,扫描所有行,把所有行加载到内存后,再按 age 排序生成一张临时表,再把那表排序后将响应行返回给客户端,更糟的,若是那张临时表的大小大于 tmp_table_size 的值(默认为 16 M),内存临时表会转为磁盘临时表,性能会更差,若是加了索引,索引自己是有序的 ,所以从磁盘读的行数自己就是按 age 排序好的,也就不会生成临时表,就不消再额外排序 ,无疑提拔了性能。
再来看随机 IO 和挨次 IO。先来解释下那两个概念。
相信很多人应该吃过扭转暖锅,办事员把一盘盘的菜放在扭转传输带上,然后比及那些菜转到我们面前,我们就能够拿到菜了,假设拆一圈需要 4 分钟,则最短期待时间是 0(即菜就在你跟前),最长期待时间是 4 分钟(菜刚好在你跟前错过),那么均匀期待时间即为 2 分钟,假设我们如今要拿四盘菜,那四盘菜随机分配在传输带上,则可知拿到那四盘菜的均匀期待时间是 8 分钟(随机 IO),若是那四盘菜刚好紧邻着排在一路,则期待时间只需 2 分钟(挨次 IO)。

上述中传输带就类比磁道,磁道上的菜就类比扇区(sector)中的信息,磁盘块(block)是由多个相邻的扇区构成的,是操做系统读取的最小单位,如许若是信息能以 block 的形式聚集在一路,就能极大削减磁盘 IO 时间,那就是挨次 IO 带来的性能提拔,下文中我们将会看到 B+ 树索引就起到如许的感化。
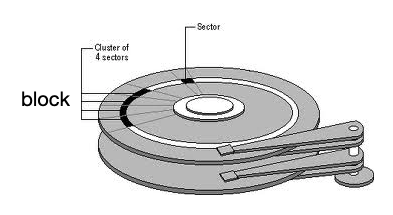
如图示:多个扇区构成了一个 block,若是要读的信息都在那个 block 中,则只需一次 IO 读
而若是信息在一个磁道平分散地散布在各个扇区中,或者散布在差别磁道的扇区上(寻道时间是随机IO次要瓶颈所在),将会形成随机 IO,影响性能。
我们来看一下一个随机 IO 的时间散布:
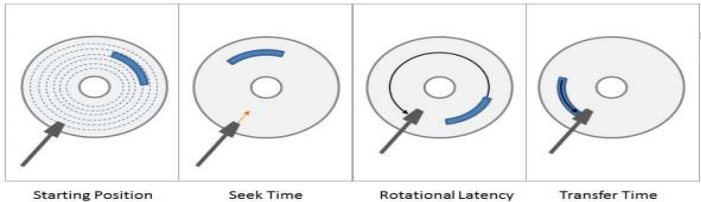 seek Time: 寻道时间,磁头挪动到扇区所在的磁道Rotational Latency:完成步调 1 后,磁头挪动到统一磁道扇区对应的位置所需求时间Transfer Time 从磁盘读取信息传入内存时间
seek Time: 寻道时间,磁头挪动到扇区所在的磁道Rotational Latency:完成步调 1 后,磁头挪动到统一磁道扇区对应的位置所需求时间Transfer Time 从磁盘读取信息传入内存时间那此中寻道时间占据了绝大大都的时间(大要占据随机 IO 时间的占 40%)。
随机 IO 和挨次 IO 大要相差百倍 (随机 IO:10 ms/ page, 挨次 IO 0.1ms / page),可见挨次 IO 性能之高,索引带来的性能提拔显而易见!
索引的品种索引次要分为以下几类
B+树索引哈希索引B+树索引B+ 树索引之前在此文中详细论述过,强烈建议各人看一遍,对理解 B+ 树有很大的帮忙,简单回忆一下吧
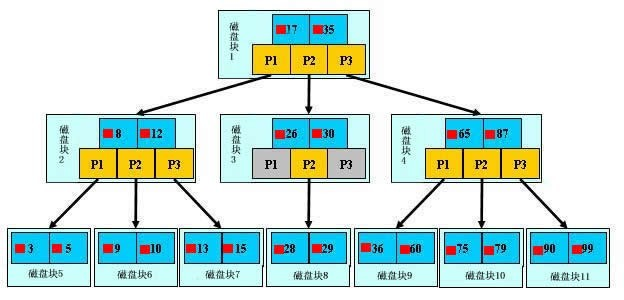
B+ 树是以 N 叉树的形式存在的,如许有效降低了树的高度,查找数据也不需要全表扫描了,顺着根节点层层往下查找能很快地找到我们的目的数据,每个节点的大小即一个磁盘块(页)的大小,一次 IO 会将一个磁盘块的数据都读入(即磁盘预读,法式部分性原理:读到了某个值,很大可能那个值四周的数据也会被用到,痛快一路读入内存),叶子节点通过指针的彼此指向毗连,能有效削减挨次遍历时的随机 IO,并且我们也能够看到,叶子节点都是按索引的挨次排序好的,那也意味着按照索引查找或排序都是排序好了的,不会再在内存中构成临时表。
哈希索引哈希索引根本散列表实现,散列表(也称哈希表)是按照关键码值(Key value)而间接停止拜候的数据构造,它让码值颠末哈希函数的转换映射到散列表对应的位置上,查找效率十分高。假设我们对名字成立了哈希索引,则查找过程如下图所示:
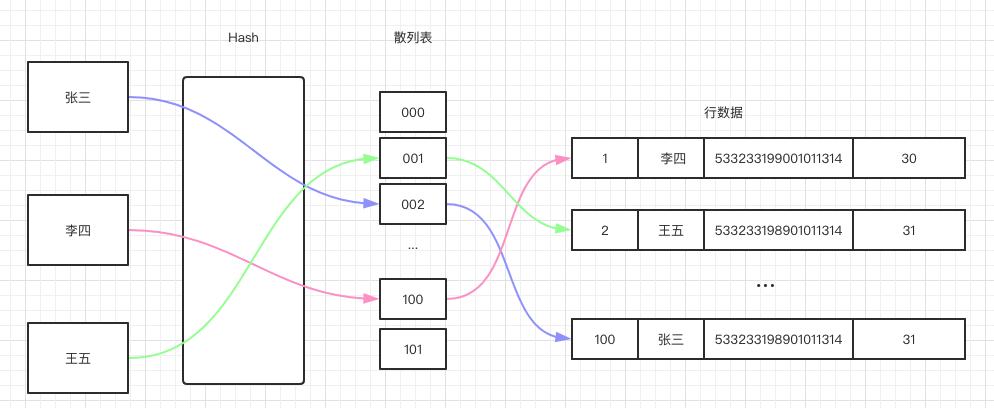
关于每一行数据,存储引擎城市对所有的索引列(上图中的 name 列)计算一个哈希码(上图散列表的位置),散列内外的每个元素指向数据行的指针,因为索引本身只存储对应的哈希值,所以索引的构造非常紧凑,那让哈希索引查找速度十分快!
当然了哈希表的优势也是比力明显的,不撑持区间查找,不撑持排序,所以更多的时候哈希表是与 B Tree等一路利用的,在 InnoDB引擎中就有一种名为「自适应哈希索引」的特殊索引,当 innoDB 留意到某些索引值利用十分频繁时,就会内存中基于 B-Tree 索引之上再创建哈希索引,如许也就让 B+ 树索引也有了哈希索引的快速查找等长处,那是完全主动,内部的行为,用户无法控造或设置装备摆设,不外若是有需要,能够封闭该功用。
innoDB 引擎自己是不撑持显式创建哈希索引的,我们能够在 B+ 树的根底上创建一个伪哈希索引,它与实正的哈希索引不是一回事,它是以哈希值而非键自己来停止索引查找的,那种伪哈希索引的利用场景是如何的呢,假设我们在 db 某张表中有个 url 字段,我们晓得每个 url 的长度都很长,若是以 url 那个字段创建索引,无疑要占用很大的存储空间,若是能通过哈希(好比CRC32)把此 url 映射成 4 个字节,再以此哈希值做索引 ,索引占用无疑大大缩短!不外在查询的时候要记得同时带上 url 和 url_crc,次要是为了制止哈希抵触,招致 url_crc 的值可能一样
SELECT id FROM url WHERE url = "http://www.baidu.com" AND url_crc = CRC32("http://www.baidu.com")如许做把基于 url 的字符串索引改成了基于 url_crc 的整型索引,效率更高,同时索引占用的空间也大大削减,一箭双雕,当然人可能会说需要手动维护索引太费事了,那能够改良触发器实现。
除了上文说的两个索引 ,还有空间索引(R-Tree),全文索引等,由消费中不是很常用,那里不做过多论述
高性能索引战略差别的索引设想选择能对性能产生很大的影响,有人可能会发现消费中明明加了索引却不生效,有时候加了固然生效但对搜刮性能并没有提拔几,关于多列结合索引,哪列在前,哪列在后也是有讲究的,我们一路来看看
加了索引,为何却不生效加了索引却不生效可能会有以下几种原因
1、索引列是暗示式的一部门,或是函数的一部门
如下 SQL:
SELECT book_id FROM BOOK WHERE book_id + 1 = 5;或者
SELECT book_id FROM BOOK WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(gmt_create) <=>10上述两个 SQL 固然在列 book_id 和 gmt_create 设置了索引 ,但因为它们是表达式或函数的一部门,招致索引无法生效,最末招致全表扫描。
2、隐式类型转换
以上两种情况相信很多人都晓得索引不克不及生效,但下面那种隐式类型转换估量会让很多人栽跟头,来看下下面那个例子:
假设有以下表:
CREATE TABLE `tradelog` ( `id` int(11) NOT NULL, `tradeid` varchar(32) DEFAULT NULL, `operator` int(11) DEFAULT NULL, `t_modified` datetime DEFAULT NULL, PRIMARY KEY (`id`), KEY `tradeid` (`tradeid`), KEY `t_modified` (`t_modified`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;施行 SQL 语句
SELECT * FROM tradelog WHERE tradeid=110717;交易编号 tradeid 上有索引,但用 EXPLAIN 施行却发现利用了全表扫描,为啥呢,tradeId 的类型是 varchar(32), 而此 SQL 用 tradeid 一个数字类型停止比力,发作了隐形转换,会隐式地将字符串转成整型,如下:
mysql> SELECT * FROM tradelog WHERE CAST(tradid AS signed int) = 110717;如许也就触发了上文中第一条的规则 ,即:索引列不克不及是函数的一部门。
3、隐式编码转换
那种情况十分隐蔽,来看下那个例子
CREATE TABLE `trade_detail` ( `id` int(11) NOT NULL, `tradeid` varchar(32) DEFAULT NULL, `trade_step` int(11) DEFAULT NULL, `step_info` varchar(32) DEFAULT NULL, PRIMARY KEY (`id`), KEY `tradeid` (`tradeid`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;trade_defail 是交易详情, tradelog 是操做此交易详情的记录,如今要查询 id=2 的交易的所有操做步调信息,则我们会接纳如下体例
SELECT d.* FROM tradelog l, trade_detail d WHERE d.tradeid=l.tradeid AND l.id=2;因为 tradelog 与 trade_detail 那两个表的字符集差别,且 tradelog 的字符集是 utf8mb4,而 trade_detail 字符集是 utf8, utf8mb4 是 utf8 的超集,所以会主动将 utf8 转成 utf8mb4。即上述语句会发作如下转换:
SELECT d.* FROM tradelog l, trade_detail d WHERE (CONVERT(d.traideid USING utf8mb4)))=l.tradeid AND l.id=2;天然也就触发了 「索引列不克不及是函数的一部门」那条规则。怎么处理呢,第一种计划当然是把两个表的字符集改成一样,若是营业量比力大,消费上不便利改的话,还有一种计划是把 utf8mb4 转成 utf8,如下
mysql> SELECT d.* FROM tradelog l , trade_detail d WHERE d.tradeid=CONVERT(l.tradeid USING utf8) AND l.id=2;如许索引列就生效了。
4、利用 order by 形成的全表扫描
SELECT * FROM user ORDER BY age DESC上述语句在 age 上加了索引,但仍然形成了全表扫描,那是因为我们利用了 SELECT *,招致回表查询,MySQL 认为回表的代价比全表扫描更大,所以不选择利用索引,若是想利用到 age 的索引,我们能够用笼盖索引来取代:
SELECT age FROM user ORDER BY age DESC或者加上 limit 的前提(数据比力小)
SELECT * FROM user ORDER BY age DESC limit 10如许就能操纵到索引。
无法制止对索引列利用函数,怎么利用索引有时候我们无法制止对索引列利用函数,但如许做会招致全表索引,能否有更好的体例呢。
好比我如今就是想记录 2016 ~ 2018 所丰年份 7月份的交易记录总数
mysql> SELECT count(*) FROM tradelog WHERE month(t_modified)=7;因为索引列是函数的参数,所以显然无法用到索引,我们能够将它革新成根本字段区间的查找如下
SELECT count(*) FROM tradelog WHERE -> (t_modified >= '2016-7-1' AND t_modified<'2016-8-1') or -> (t_modified >= '2017-7-1' AND t_modified<'2017-8-1') or -> (t_modified >= '2018-7-1' AND t_modified<'2018-8-1');前缀索引与索引选择性之前我们说过,如于长字符串的字段(如 url),我们能够用伪哈希索引的形式来创建索引,以制止索引变得既大又慢,除此之外其实还能够用前缀索引(字符串的部门字符)的形式来到达我们的目标,那么那个前缀索引应该若何拔取呢,那叫涉及到一个叫索引选择性的概念
索引选择性:不反复的索引值(也称为基数,cardinality)和数据表的记录总数的比值,比值越高,代表索引的选择性越好,独一索引的选择性是更好的,比值是 1。
画外音:我们能够通过 SHOW INDEXES FROM table 来查看每个索引 cardinality 的值以评估索引设想的合理性
怎么选择那个比例呢,我们能够别离取前 3,4,5,6,7 的前缀索引,然后再比力下选择那几个前缀索引的选择性,施行以下语句
SELECT COUNT(DISTINCT LEFT(city,3))/COUNT(*) as sel3, COUNT(DISTINCT LEFT(city,4))/COUNT(*) as sel4, COUNT(DISTINCT LEFT(city,5))/COUNT(*) as sel5, COUNT(DISTINCT LEFT(city,6))/COUNT(*) as sel6, COUNT(DISTINCT LEFT(city,7))/COUNT(*) as sel7FROM city_demo得成果如下
sel3sel4sel5sel6sel70.02390.02930.03050.03090.0310能够看到当前缀长度为 7 时,索引选择性提拔的比例已经很小了,也就是说应该选择 city 的前六个字符做为前缀索引,如下
ALTER TABLE city_demo ADD KEY(city(6))我们当前是以均匀选择性为目标的,有时候如许是不敷的,还得考虑最坏情况下的选择性,以那个 demo 为例,可能一些人看到选择 4,5 的前缀索引与选择 6,7 的选择性相差不大,那就得看下选择 4,5 的前缀索引散布能否平均了
SELECT COUNT(*) AS cnt, LEFT(city, 4) AS pref FROM city_demo GROUP BY pref ORDER BY cnt DESC LIMIT 5可能会呈现以下成果
cntpref305Sant200Toul90Chic20Chan能够看到散布极不平均,以 Sant,Toul 为前缀索引的数量极多,那两者的选择性都不是很抱负,所以要选择前缀索引时也要考虑最差的选择性的情况。
前缀索引固然能实现索引占用空间小且快的效果,但它也有明显的弱点,MySQL 无法利用前缀索引做 ORDER BY 和 GROUP BY ,并且也无法利用前缀索引做笼盖扫描,前缀索引也有可能增加扫描行数。
假设有以下表数据及要施行的 SQL
idemail1zhangssxyz@163.com2zhangs1@163.com3zhangs1@163.com4zhangs1@163.comSELECT id,email FROM user WHERE email='zhangssxyz@xxx.com';若是我们针对 email 设置的是整个字段的索引,则上表中按照 「zhangssxyz@163.com」查询到相关记记录后,再查询此记录的下一笔记录,发现没有,停行扫描,此时可知只扫描一行记录,若是我们以前六个字符(即 email(6))做为前缀索引,则显然要扫描四行记录,而且获得行记录后不能不回到主键索引再判断 email 字段的值,所以利用前缀索引要评估它带来的那些开销。
别的有一种情况我们可能需要考虑一下,若是前缀根本都是不异的该怎么办,好比如今我们为某市的市民成立一小我口信息表,则那个市生齿的身份证固然差别,但身份证前面的几位数都是不异的,那种情况该怎么成立前缀索引呢。
一种体例就是我们上文说的,针对身份证成立哈希索引,另一种体例比力巧妙,将身份证倒序存储,查的时候能够按如下体例查询:
SELECT field_list FROM t WHERE id_card = reverse('input_id_card_string');如许就能够用身份证的后六位做前缀索引了,是不是很巧妙 ^_^
现实上上文所述的索引选择性同样适用于结合索引的设想,若是没有特殊情况,我们一般建议在成立结合索引时,把选择性更高的列放在最前面,好比,关于以下语句:
SELECT * FROM payment WHERE staff_id = xxx AND customer_id = xxx;单就那个语句而言, (staff_id,customer_id) 和 (customer_id, staff_id) 那两个结合索引我们应该建哪一个呢,能够统计下那两者的选择性。
SELECT COUNT(DISTINCT staff_id)/COUNT(*) as staff_id_selectivity, COUNT(DISTINCT customer_id)/COUNT(*) as customer_id_selectivity, COUNT(*)FROM payment成果为: ;
staff_id_selectivity: 0.0001customer_id_selectivity: 0.0373COUNT(*): 16049从中能够看出 customer_id 的选择性更高,所以应该选择 customer_id 做为第一列。
索引设想原则:三星索引上文我们得出了一个索引列挨次的经历 法例:将选择性更高的列放在索引的最前列,那种成立在某些场景可能有用,但凡是不如制止随机 IO 和 排序那么重要,那里引入索引设想中十分出名的一个原则:三星索引。
若是一个查询满足三星索引中三颗星的所有索引前提,理论上能够认为我们设想的索引是更好的索引。什么是三星索引
第一颗星:WHERE 后面参与查询的列能够构成了单列索引或结合索引
第二颗星:制止排序,即若是 SQL 语句中呈现 order by colulmn,那么取出的成果集就已经是根据 column 排序好的,不需要再生成临时表
第三颗星:SELECT 对应的列应该尽量是索引列,即尽量制止回表查询。
所以关于如下语句:
SELECT age, name, city where age = xxx and name = xxx order by age设想的索引应该是 (age, name,city) 或者 (name, age,city)
当然 了三星索引是一个比力抱负化的尺度,现实操做往往只能满足期望中的一颗或两颗星,考虑如下语句:
SELECT age, name, city where age >= 10 AND age <=>20 and city = xxx order by name desc假设我们别离为那三列建了结合索引,则显然它契合第三颗星(利用了笼盖索引),若是索引是(city, age, name),则固然满足了第一颗星,但排序无法用到索引,不满足第二颗星,若是索引是 (city, name, age),则第二颗星满足了,但此时 age 在 WHERE 中的搜刮前提又无法满足第一星,
别的第三颗星(尽量利用笼盖索引)也无法完全满足,试想我要 SELECT 多列,要把那多列都设置为结合索引吗,那对索引的维护是个问题,因为每一次表的 CURD 都陪伴着索引的更新,很可能频繁陪伴着页团结与页合并。
综上所述,三星索引只是给我们构建索引供给了一个参考,索引设想应该尽量靠近三星索引的尺度,但现实场景我们一般无法同时满足三星索引,一般我们会优先选择满足第三颗星(因为回表代价较大)至于第一,二颗星就要依赖于现实的成本及现实的营业场景考虑。
总结本文简述了索引的根本原理,索引的几品种型,以及阐发了一下设想索引尽量应该遵照的一些原则,相信我们对索引的理解又更深了一步。别的强烈建议各人去进修一下附录中的几本书。文中的挺多例子都是在文末的参考材料中总结出来的,读典范册本,相信各人会收获颇丰!
巨人的肩膀
《高性能 MySQL》
《Relational Database index design and the optimizers》
《MySQL 实战 45讲》https://time.geekbang.org/column/article/71492
:Tomcat 打破双亲委派")



还没有评论,来说两句吧...