
在讲到利用hash仍是string存储的选择前,先领会Redis的hash和string构造。
以下材料引自老钱的Redis深度历险。
stringstring和hash都是Redis的一种数据构造。string构造常用来缓存用户信息,凡是将用户信息构造体利用JSON序列化成字符串,然后将序列化后的字符串存入Redis停止缓存。
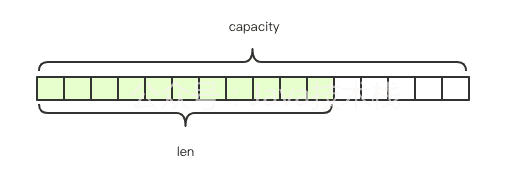
Redis的字符串是动态字符串,能够修改,内部构造类似于Java的ArrayList,接纳预分配冗余空间的体例来削减内存的频繁分配。如上图锁实,内部为当前字符串现实分配的空间capacity,一般高于现实字符串长度len。利用的指令有set, get, mset, mget等
hashRedis的hash相当于Java的HashMap,内部构造实现与HashMap一致,即数组+链表构造
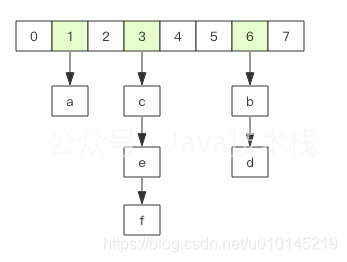
不外Redis的hash的值只能是字符串,rehash体例纷歧样,为了进步性能,Redis保留新旧两个hash构造,接纳渐进式rehash战略,查询时会同事查询两个hash构造,在后续的按时使命中以及hash操做指令中,循序渐进将旧hash的内容迁徙到xinhash中,曲至完全代替旧hash。hash移除最初一个元素后会主动被删除,内存被收受接管。
前面说到string合适存储用户信息,而hash构造也能够存储用户信息,不外是对每个字段零丁存储,因而能够在查询时获取部门字段的信息,节省收集流量。
因而就引出了那篇文章,存储构造体信息是用hash仍是string?
以下信息出自StackOverflow Redis strings vs Redis hashes to represent JSON: efficiency?
I want to store a JSON payload into redis. There's really 2 ways I can do this:1. One using a simple string keys and values.key:user, value:payload (the entire JSON blob which can be 100-200 KB)SET user:1 payload2. Using hashesHSET user:1 username "someone"HSET user:1 location "NY"HSET user:1 bio "STRING WITH OVER 100 lines"Keep in mind that if I use a hash, the value length isn't predictable. They're not all short such as the bio example above.Which is more memory efficient? Using string keys and values, or using a hash?该用户也是同样的疑问,因为值的长度是不确定的,所以不晓得接纳string仍是hash存储更有效率
那个问题底下有个开发者答复的十分好,那里翻译出来供各人一路进修讨论,若是有更好的计划,欢送提出来 起首,答者建议参考redis官方的内存优化的文章:https://redis.io/topics/memory-optimization,用来理解官方的开发者是内存优化方面基于什么考虑。
之后,答者列出了四个计划并给出了各个计划的利弊
1. 存储整个对象,此中JSON序列化过的字符串做为key
INCR id:usersSET user:{id} '{"name":"Fred","age":25}'SADD users {id}优势:能够认为是“更佳理论”,因为每个对象都是全特征的key,JSON解析出格块,尤其是一次性查询良多个字段的时候优势:若是只查询一个字段,速度就显得比力慢了2. 在hash中存储每个对象的属性
INCR id:usersHMSET user:{id} name "Fred" age 25SADD users {id}优势:那也能够认为是更佳时间。每个对象都是一个全特征的key。不需要解析JSON字符串优势:若是要查询对象的全数字段会比力慢。嵌套类型的对象(即对象里面还包着对象)无法随便存储3. 将对象转化为JSON字符串,用hash构造存储
INCR id:usersHMSET users {id} '{"name":"Fred","age":25}'那个计划能够仅用两个key,不需要良多key。但是没法对每个用户对象设置TTL(Time to Live,剩余保存时间),因为对象仅仅是hash中的一个字段,而不是全特征的key
优势:JSON解析很快,尤其是一次查询多个字段时,对主key的定名空间污染更少优势:若是要存储良多对象,那么内存利用和计划1相当。当只需要查询一个字段时,会例如案2速度慢。答者不认为那是一个“更佳理论”4. 存储对象的每个属性做为零丁的key
INCR id:usersSET user:{id}:name "Fred"SET user:{id}:age 25SADD users {id}按照上面的文章,即redis内存优化,那个计划不保举(除非对象的属性需要专门设置TTL或者此外设置)
优势:对象的属性是全特征key,关于应用来说比力益处理优势:慢,内存消耗更大,不是一个“更佳理论”。对主key的定名空间有很大污染总的来说,计划4是最不保举的,计划1和计划2十分类似,也很常见。答者更保举计划1,因为那个计划允许存储更复杂的对象(也就是说对象能够有良多层嵌套)。计划3凡是用在对定名空间比力有要求的场景下,好比说不想要太多key,不关心TTL等参数。
参考材料
《Redis深度历险》
https://juejin.im/book/5afc2e5f6fb9a07a9b362527/section/5afc2e5f51882542714ff291
https://stackoverflow.com/questions/16375188/redis-strings-vs-redis-hashes-to-represent-json-efficiency
原文链接:https://blog.csdn.net/u010145219/article/details/99427693
版权声明:本文为CSDN博主「布鲁斯1990」的原创文章,遵照CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
近期热文保举:
1.1,000+ 道 Java面试题及谜底整理(2022最新版)
2.劲爆!Java 协程要来了。。。
3.Spring Boot 2.x 教程,太全了!
4.别再写满屏的爆爆爆炸类了,尝尝粉饰器形式,那才是文雅的体例!!
5.《Java开发手册(嵩山版)》最新发布,速速下载!
觉得不错,别忘了随手点赞+转发哦!




还没有评论,来说两句吧...