
异地多活到底是什么?为什么需要异地多活?它到底处理了什么问题?事实是怎么处理的?
那些疑问,想必是每个法式看到异地多活那个名词时,都想要搞大白的问题。
有幸,我曾经深度参与过一个中等互联网公司,建立异地多活系统的设想与施行过程。所以今天就来聊一聊异地多活背后的的实现原理。
认实读完那篇文章,相信我们会对异地多活架构,有愈加深入的理解。
 01 系统可用性
01 系统可用性要想理解异地多活,我们需要从架构设想的原则说起。
现现在,我们开发一个软件系统,对其要求越来越高,若是你领会一些「架构设想」的要求,就晓得一个好的软件架构应该遵照以下 3 个原则:
高性能高可用易扩展此中,高性能意味着系统拥有更大流量的处置才能,更低的响应延迟。例如 1 秒可处置 10W 并发恳求,接口响应时间 5 ms 等等。
易扩展暗示系统在迭代新功用时,能以最小的代价去扩展,系统碰到流量压力时,能够在不改动代码的前提下,去扩容系统。
而「高可用」那个概念,看起来很笼统,怎么理解它呢?凡是用 2 个目标来权衡:
均匀毛病间隔 MTBF(Mean Time Between Failure):暗示两次毛病的间隔时间,也就是系统「一般运行」的均匀时间,那个时间越长,申明系统不变性越高毛病恢复时间 MTTR(Mean Time To Repair):暗示系统发作毛病后「恢复的时间」,那个值越小,毛病对用户的影响越小可用性与那两者的关系:
可用性(Availability)= MTBF / (MTBF + MTTR) * 100%
那个公式得出的成果是一个「比例」,凡是我们会用「N 个 9」来描述一个系统的可用性。
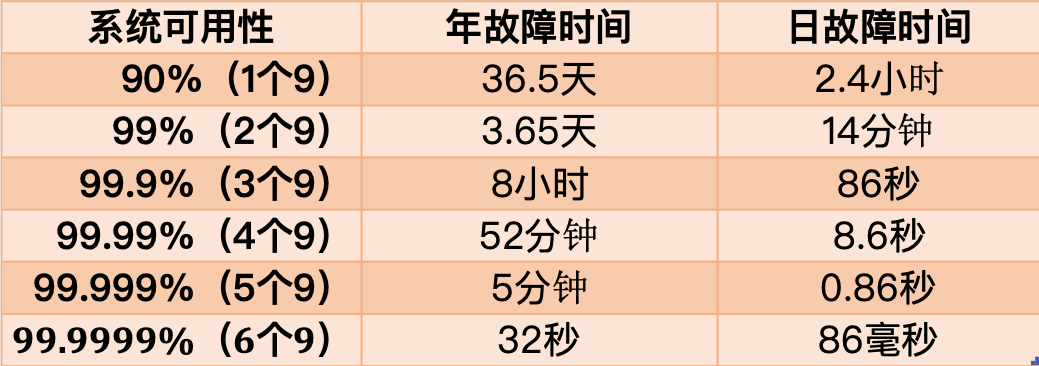
从那张图你能够看到,要想到达 4 个 9 以上的可用性,均匀每天毛病时间必需控造在 10 秒以内。
也就是说,只要毛病的时间「越短」,整个系统的可用性才会越高,每提拔 1 个 9,城市对系统提出更高的要求。
我们都晓得,系统发作毛病其实是不成制止的,尤其是规模越大的系统,发作问题的概率也越大。那些毛病一般表现在 3 个方面:
硬件毛病:CPU、内存、磁盘、网卡、交换机、路由器软件问题:代码 Bug、版本迭代不成抗力:地震、水灾、火灾、战争那些风险随时都有可能发作。所以,在面临毛病时,我们的系统能否以「最快」的速度恢复,就成为了可用性的关键。
可若何做到快速恢复呢?
那篇文章要讲的「异地多活」架构,就是为领会决那个问题,而提出的高效处理计划。
下面,我会从一个最简单的系统动身,带你一步步演化出一个撑持「异地多活」的系统架构。
在那个过程中,你会看到一个系统会碰到哪些可用性问题,以及为什么架构要如许演进,从而理解异地多活架构的意义。
02 单机架构我们从最简单的起头讲起。
假设你的营业处于起步阶段,体量十分小,那你的架构是如许的:
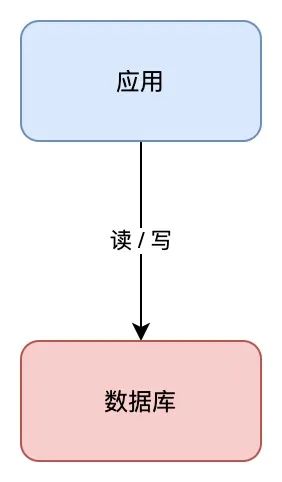
那个架构模子十分简单,客户端恳求进来,营业应用读写数据库,返回成果,十分好理解。
但需要留意的是,那里的数据库是「单机」摆设的,所以它有一个致命的缺点:一旦遭遇不测,例如磁盘损坏、操做系统异常、误删数据,那那意味着所有数据就全数「丧失」了,那个丧失是庞大的。
若何制止那个问题呢?我们很容易想到一个计划:备份。
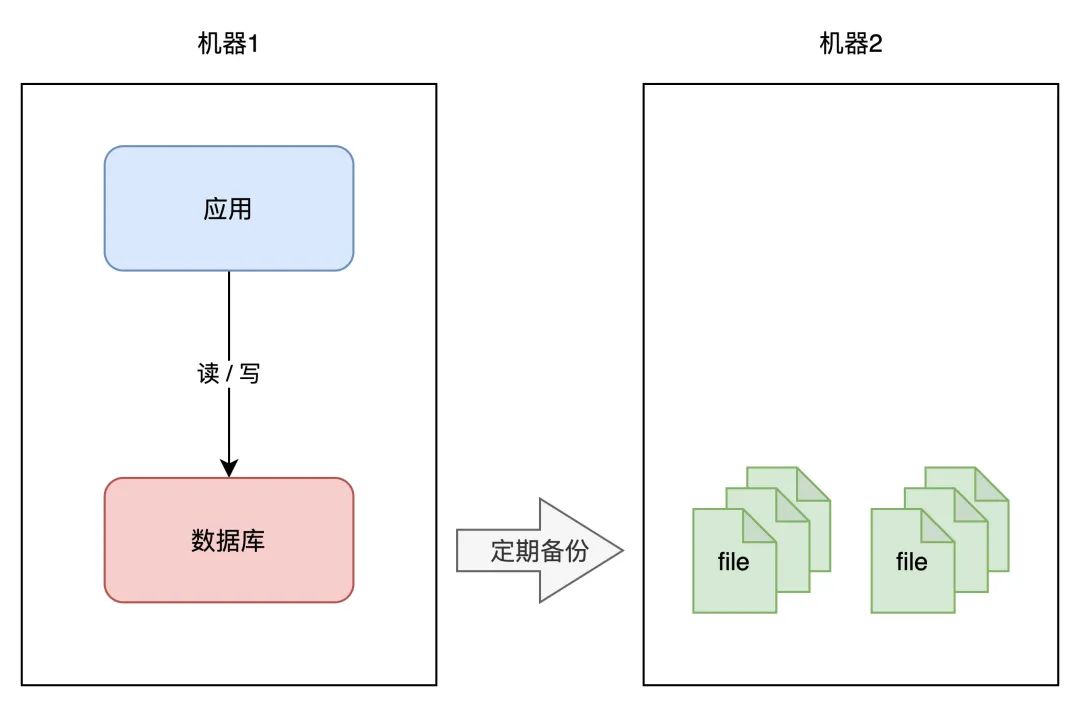
你能够对数据做备份,把数据库文件「按期」cp 到另一台机器上,如许,即便原机器丧失数据,你照旧能够通过备份把数据「恢复」回来,以此包管数据平安。
那个计划施行起来固然比力简单,但存在 2 个问题:
恢复需要时间:营业需先停机,再恢复数据,停机时间取决于恢复的速度,恢复期间办事「不成用」数据不完好:因为是按期备份,数据必定不是「最新」的,数据完好水平取决于备份的周期很明显,你的数据库越大,意味毛病恢复时间越久。那根据前面我们提到的「高可用」尺度,那个计划可能连 1 个 9 都达不到,远远无法满足我们对可用性的要求。
那有什么更好的计划,既能够快速恢复营业?还能尽可能包管数据完好性呢?
那时你能够接纳那个计划:主从副本。
03 主从副本你能够在另一台机器上,再摆设一个数据库实例,让那个新实例成为原实例的「副本」,让两者连结「实时同步」,就像如许:
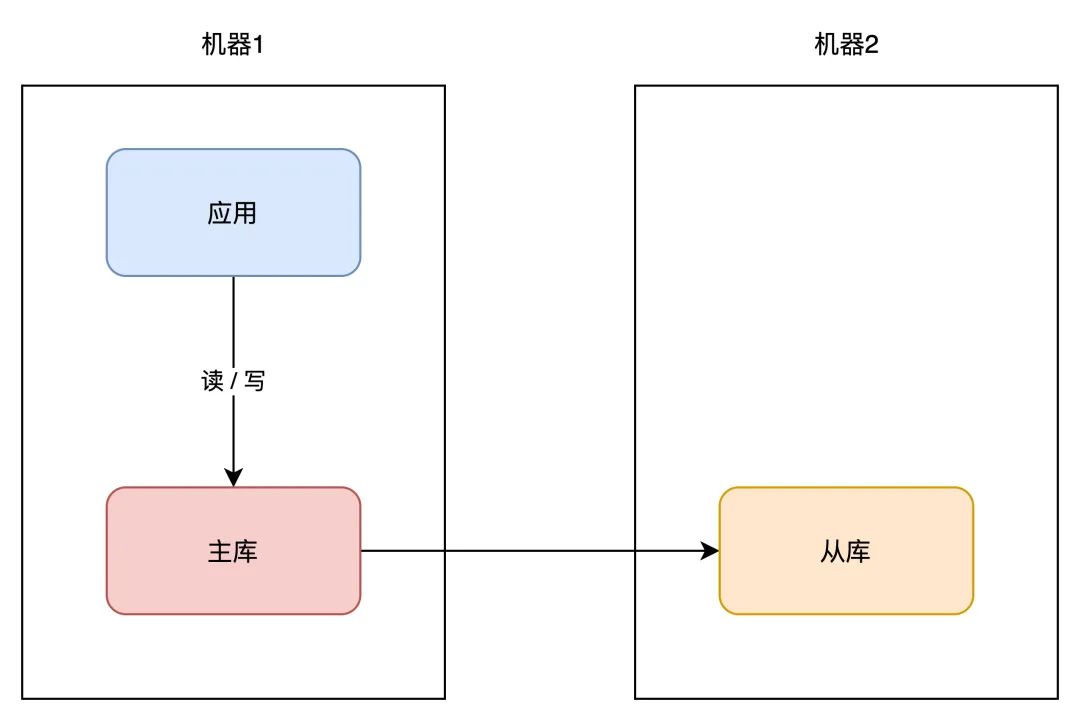
我们一般把原实例叫做主库(master),新实例叫做从库(slave)。那个计划的长处在于:
数据完好性高:主从副本实时同步,数据「差别」很小抗毛病才能提拔:主库有任何异常,从库可随时「切换」为主库,继续供给办事读性能提拔:营业应用可间接读从库,分管主库「压力」读压力那个计划不错,不只大大进步了数据库的可用性,还提拔了系统的读性能。
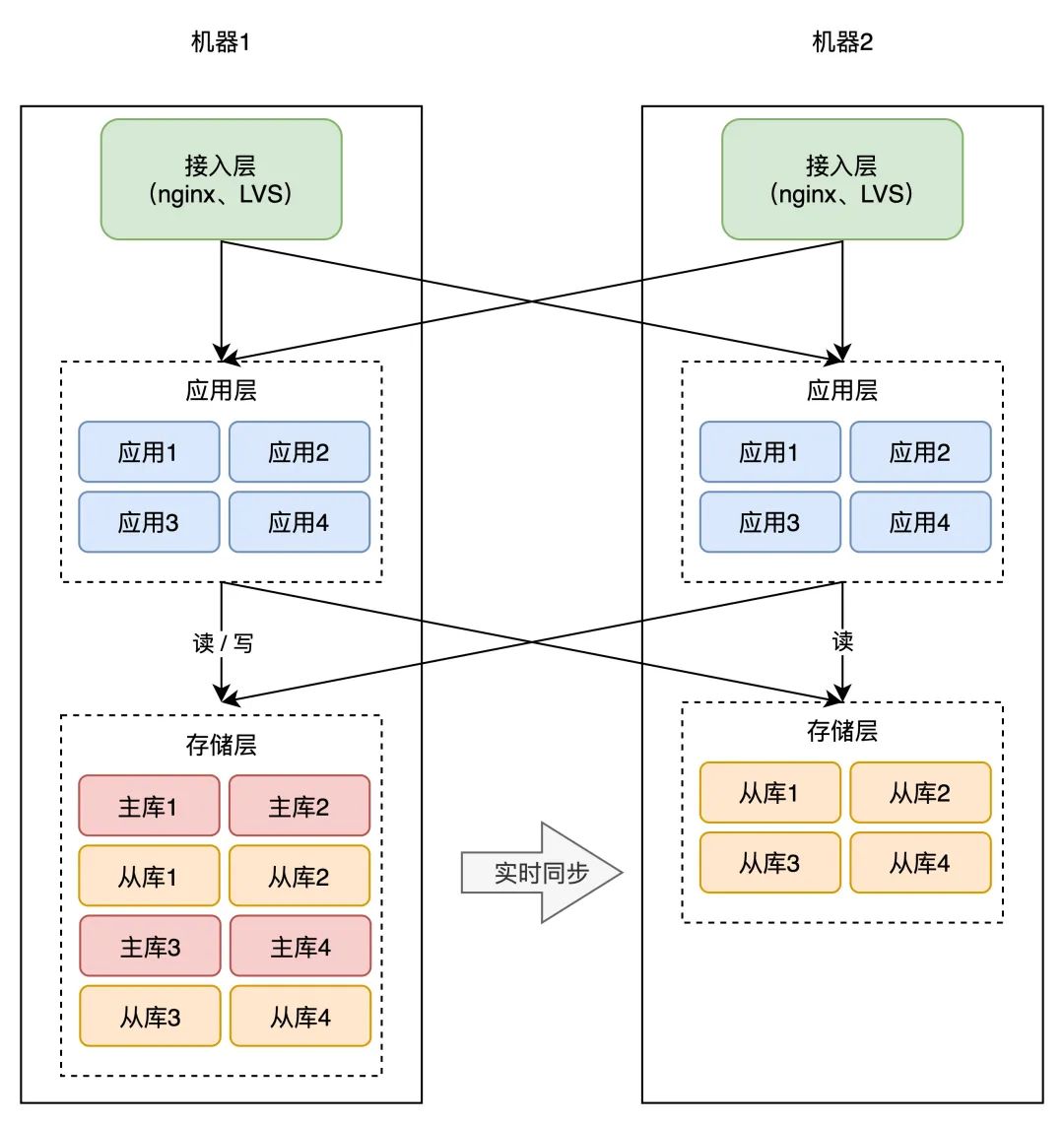
同样的思绪,你的「营业应用」也能够在其它机器摆设一份,制止单点。因为营业应用凡是是「无形态」的(不像数据库那样存储数据),所以间接摆设即可,十分简单。
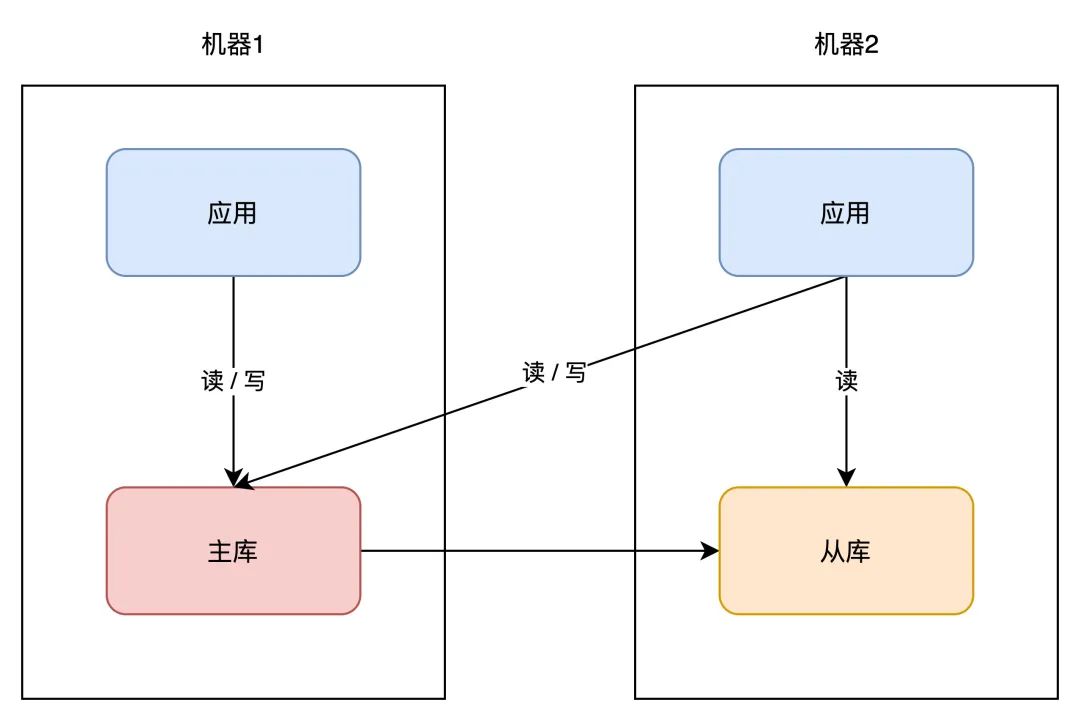
因为营业应用摆设了多个,所以你如今还需要摆设一个「接入层」,来做恳求的「负载平衡」(一般会利用 nginx 或 LVS),如许当一台机器宕机后,另一台机器也能够「接收」所有流量,持续供给办事。
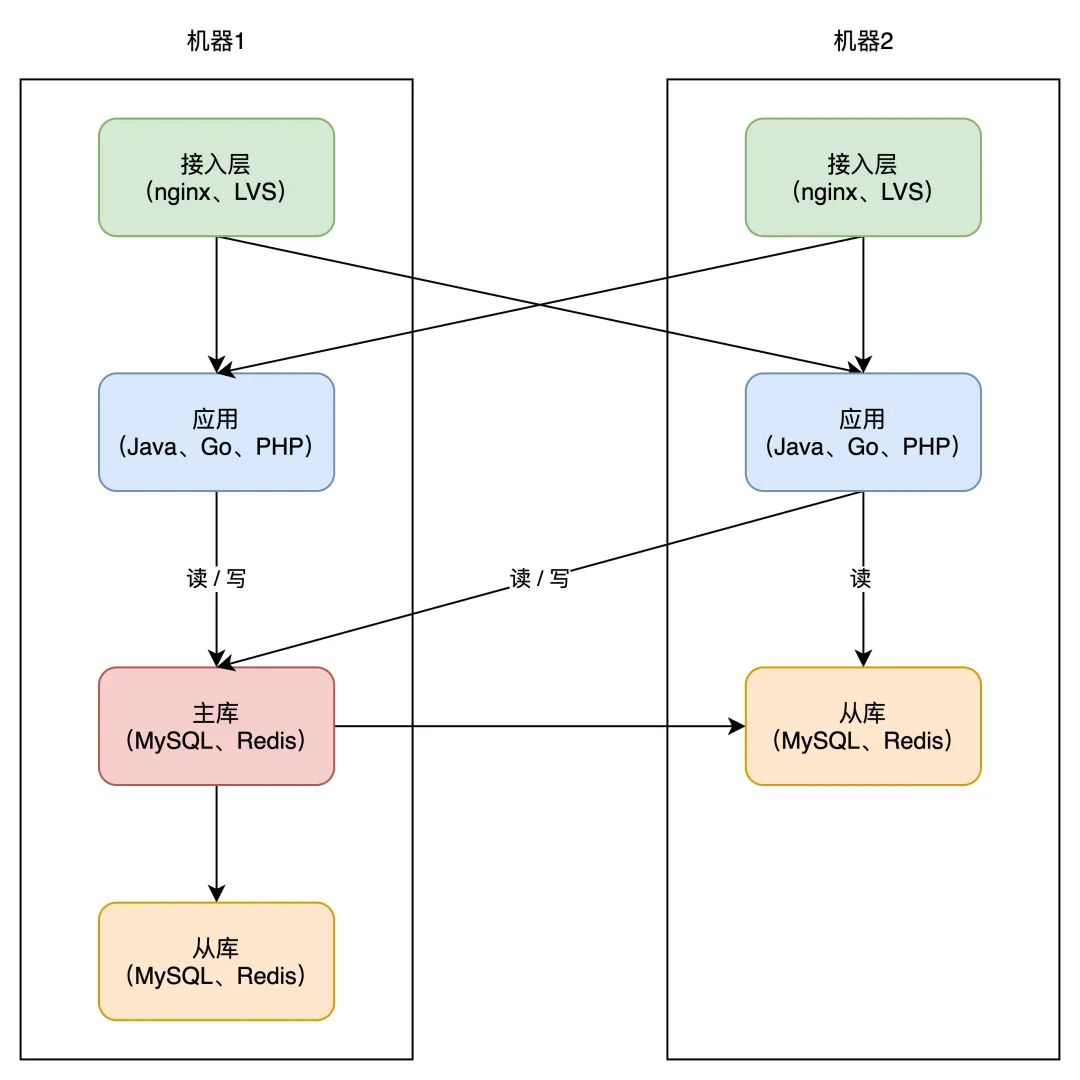
从那个计划你能够看出,提拔可用性的关键思绪就是:冗余。
没错,担忧一个实例毛病,那就摆设多个实例,担忧一个机器宕机,那就摆设多台机器。
到那里,你的架构根本已演酿成支流计划了,之后开发新的营业应用,都能够根据那种形式去摆设。
但那种计划还有什么风险吗?
04 风险不成控如今让我们把视角下放,把焦点放到详细的「摆设细节」上来。
根据前面的阐发,为了制止单点毛病,你的应用固然摆设了多台机器,但那些机器的散布情况,我们并没有去深究。
而一个机房有良多办事器,那些办事器凡是会散布在一个个「机柜」上,若是你利用的那些机器,刚好在一个机柜,仍是存在风险。
若是刚好毗连那个机柜的交换机 / 路由器发作毛病,那么你的应用照旧有「不成用」的风险。
固然交换机 / 路由器也做了道路冗余,但不克不及包管必然不出问题。
摆设在一个机柜有风险,那把那些机器打散,分离到差别机柜上,是不是就没问题了?
如许确实会大大降低出问题的概率。但我们照旧不克不及漫不经心,因为无论怎么分离,它们总偿还是在一个不异的情况下:机房。
那继续诘问,机房会不会发作毛病呢?
一般来讲,建立一个机房的要求其实是很高的,天文位置、温湿度控造、备用电源等等,机房厂商会在各方面做好防护。但即便如许,我们每隔一段时间还会看到如许的新闻:
2015 年 5 月 27 日,杭州市某地光纤被挖断,近 3 亿用户长达 5 小时无法拜候付出宝2021 年 7 月 13 日,B 站部门办事器机房发作毛病,形成整站持续 3 个小时无法拜候2021 年 10 月 9 日,富途证券办事器机房发作电力闪断毛病,形成用户 2 个小时无法登岸、交易...可见,即便机房级此外防护已经做得足够好,但只要有「概率」出问题,那现实情况就有可能发作。固然概率很小,但一旦实的发作,影响之大可见一斑。
看到那里你可能会想,机房呈现问题的概率也太小了吧,工做了那么多年,也没让我碰上一次,有需要考虑得那么复杂吗?
但你有没有思虑如许一个问题:差别体量的系统,它们各自存眷的重点是什么?
体量很小的系统,它会重点存眷「用户」规模、增长,那个阶段获取用户是一切。等用户体量上来了,那个阶段会重点存眷「性能」,优化接口响应时间、页面翻开速度等等,那个阶段更多是存眷用户体验。
等体量再大到必然规模后你会发现,「可用性」就变得尤为重要。像微信、付出宝那种全民级的应用,若是机房发作一次毛病,那整个影响范畴能够说长短常庞大的。
所以,再小概率的风险,我们在进步系统可用性时,也不克不及轻忽。
阐发了风险,再说回我们的架构。那到底该怎么应对机房级此外毛病呢?
没错,仍是冗余。
05 同城灾备想要抵御「机房」级此外风险,那应对计划就不克不及局限在一个机房内了。
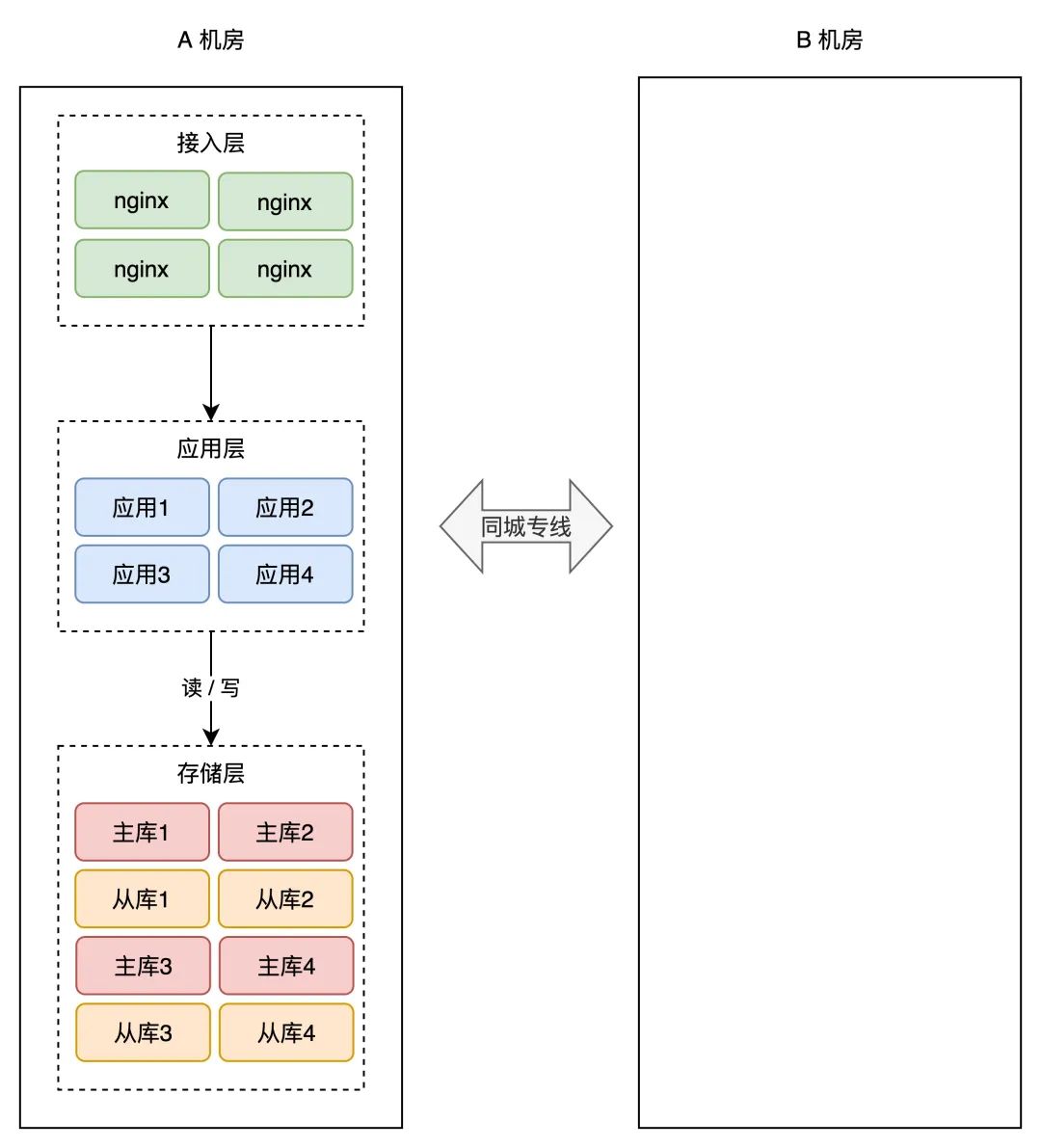
如今,你需要做机房级此外冗余计划,也就是说,你需要再搭建一个机房,来摆设你的办事。
简单起见,你能够在「统一个城市」再搭建一个机房,原机房我们叫做 A 机房,新机房叫 B 机房,那两个机房的收集用一条「专线」连通。
有了新机房,怎么把它用起来呢?那里仍是要优先考虑「数据」风险。
为了制止 A 机房毛病招致数据丧失,所以我们需要把数据在 B 机房也存一份。最简单的计划仍是和前面提到的一样:备份。
A 机房的数据,按时在 B 机房做备份(拷贝数据文件),如许即便整个 A 机房遭到严峻的损坏,B 机房的数据不会丢,通过备份能够把数据「恢复」回来,重启办事。
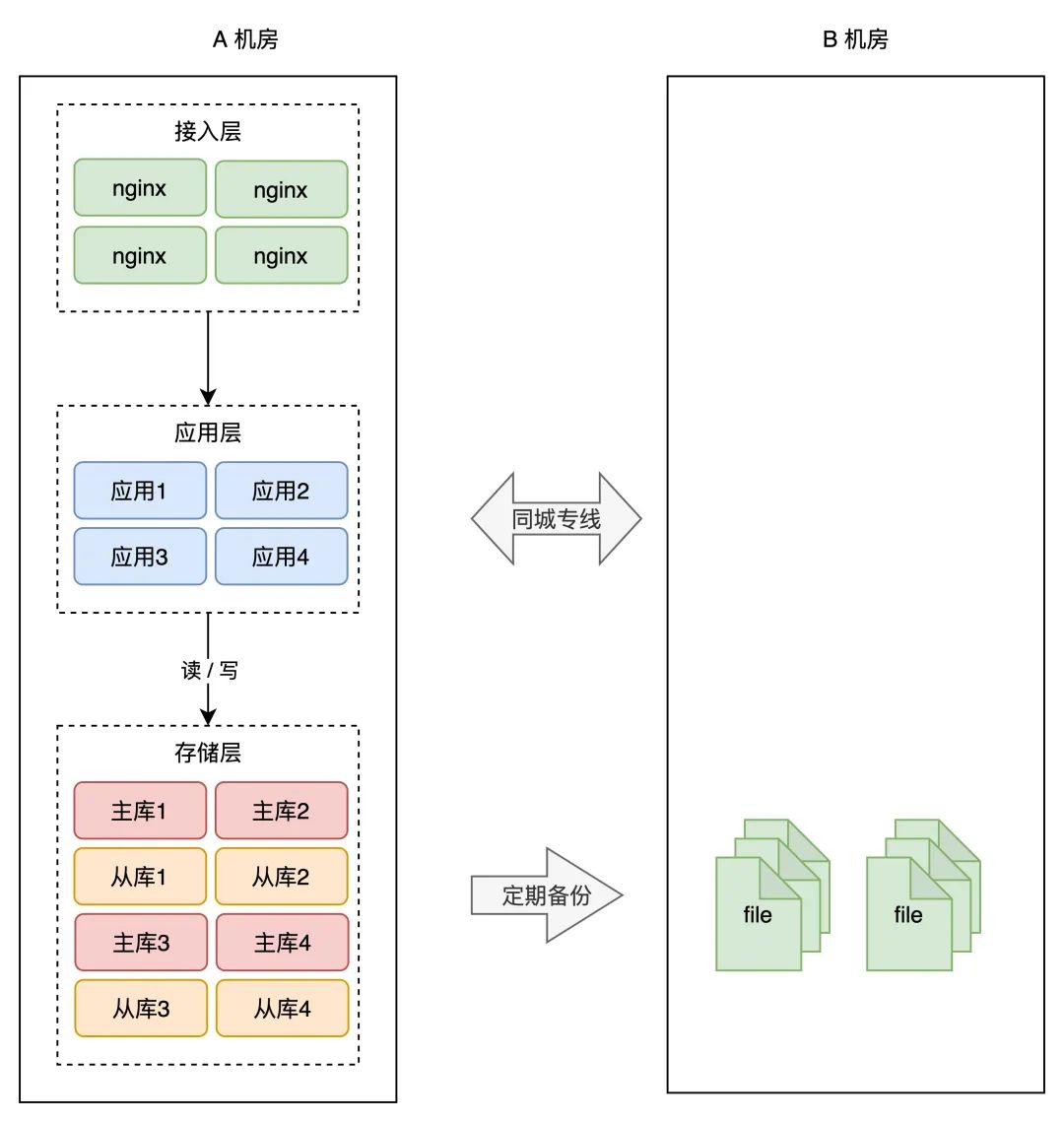
那种计划,我们称之为「冷备」。为什么叫冷备呢?因为 B 机房只做备份,不供给实时办事,它是冷的,只会在 A 机房毛病时才会启用。
但备份的问题照旧和之前描述的一样:数据不完好、恢复数据期间营业不成用,整个系统的可用性仍是无法得到包管。
所以,我们仍是需要用「主从副本」的体例,在 B 机房摆设 A 机房的数据副本,架构就酿成了如许:
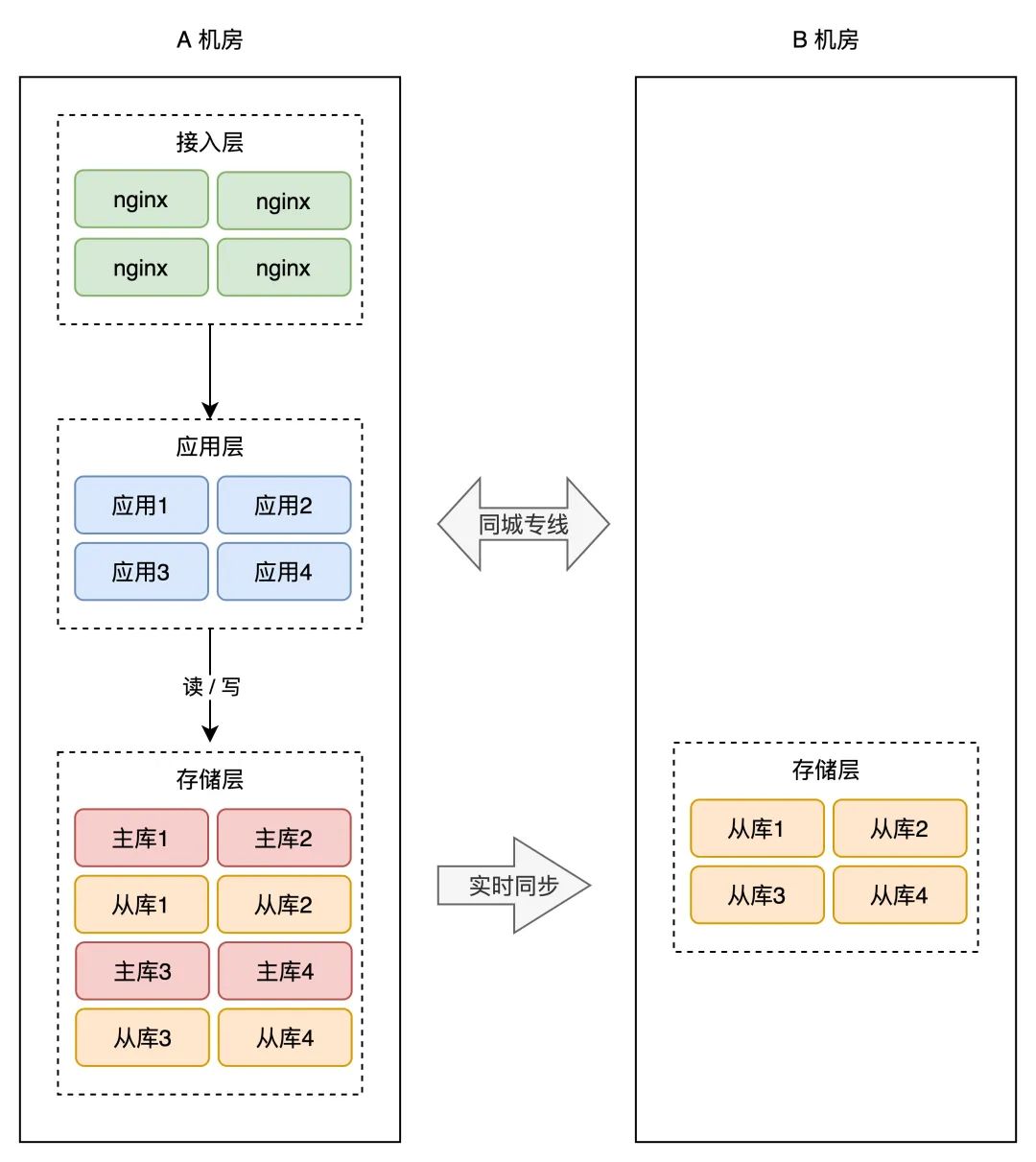
如许,就算整个 A 机房挂掉,我们在 B 机房也有比力「完好」的数据。
数据是保住了,但那时你需要考虑别的一个问题:若是 A 机房实挂掉了,要想包管办事不中断,你还需要在 B 机房「告急」做那些工作:
B 机房所有从库提拔为主库在 B 机房摆设应用,启动办事摆设接入层,设置装备摆设转发规则DNS 指向 B 机房,接入流量,营业恢复看到了么?A 机房毛病后,B 机房需要做那么多工做,你的营业才气完全「恢复」过来。
你看,整个过程需要报酬介入,且需破费大量时间来操做,恢复之前整个办事仍是不成用的,那个计划仍是不太爽,若是能做到毛病后立即「切换」,那就好了。
因而,要想缩短营业恢复的时间,你必需把那些工做在 B 机房「提早」做好,也就是说,你需要在 B 机房提早摆设好接入层、营业应用,期待随时切换。架构就酿成了如许:
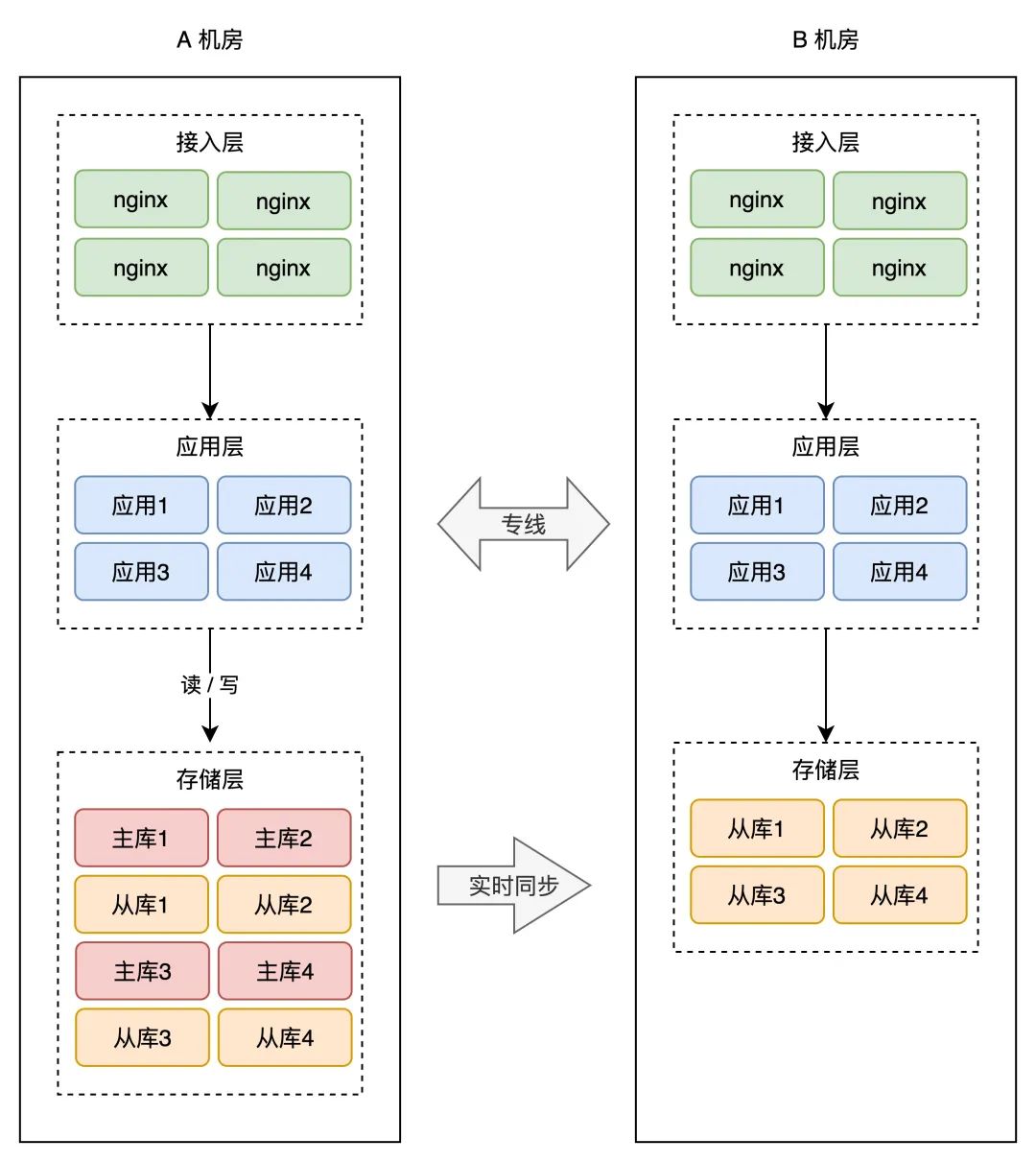
如许的话,A 机房整个挂掉,我们只需要做 2 件事即可:
B 机房所有从库提拔为主库DNS 指向 B 机房,接入流量,营业恢复如许一来,恢复速度快了良多。
到那里你会发现,B 机房从最起头的「一无所有」,演变到如今,几乎是「镜像」了一份 A 机房的所有工具,从最上层的接入层,到中间的营业应用,到最下层的存储。
两个机房独一的区别是,A 机房的存储都是主库,而 B 机房都是从库。
那种计划,我们把它叫做「热备」。
热的意思是指,B 机房处于「待命」形态,A 毛病后 B 能够随时「接收」流量,继续供给办事。热备比拟于冷备更大的长处是:随时可切换。
无论是冷备仍是热备,因为它们都处于「备用」形态,所以我们把那两个计划统称为:同城灾备。
同城灾备的更大优势在于,我们再也不消担忧「机房」级此外毛病了,一个机房发作风险,我们只需把流量切换到另一个机房即可,可用性再次进步,是不是很爽?(后面还有更爽的)
06 同城双活我们继续来看那个架构。
固然我们有了应对机房毛病的处理计划,但那里有个问题是我们不克不及轻忽的:A 机房挂掉,全数流量切到 B 机房,B 机房能否实的如我们所愿,一般供给办事?
那是个值得思虑的问题。
那就比如有两收戎行 A 和 B,A 戎行历经疆场,做战经历丰硕,而 B 戎行只是后备军,除了有军人的根本素养之外,并没有实战经历,战斗经历根本为 0。
若是 A 戎行丧失战斗才能,需要 B 戎行立即顶上时,做为批示官的你,必定也会担忧 B 戎行能否实的担此重任吧?
我们的架构也是如斯,此时的 B 机房固然是随时「待命」形态,但 A 机房实的发作毛病,我们要把全数流量切到 B 机房,其实是不敢百分百包管它能够「如期」工做的。
你想,我们在一个机房内摆设办事,还老是发作各类各样的问题,例如:发布应用的版本纷歧致、系统资本不敷、操做系统参数纷歧样等等。如今多摆设一个机房,那些问题只会增加,不会削减。
别的,从「成本」的角度来看,我们新摆设一个机房,需要购置办事器、内存、硬盘、带宽资本,破费成本也长短常昂扬的,只让它当一个后备军,不免难免也太「牛鼎烹鸡」了!
因而,我们需要让 B 机房也接入流量,实时供给办事,如许做的益处,一是能够实时训练那收后备军,让它到达与 A 机房不异的做战程度,随时可切换,二是 B 机房接入流量后,能够分管 A 机房的流量压力。那才是把 B 机房资本优势,阐扬更大化的更好计划!
那怎么让 B 机房也接入流量呢?很简单,就是把 B 机房的接入层 IP 地址,参加到 DNS 中,如许,B 机房从上层就能够有流量进来了。
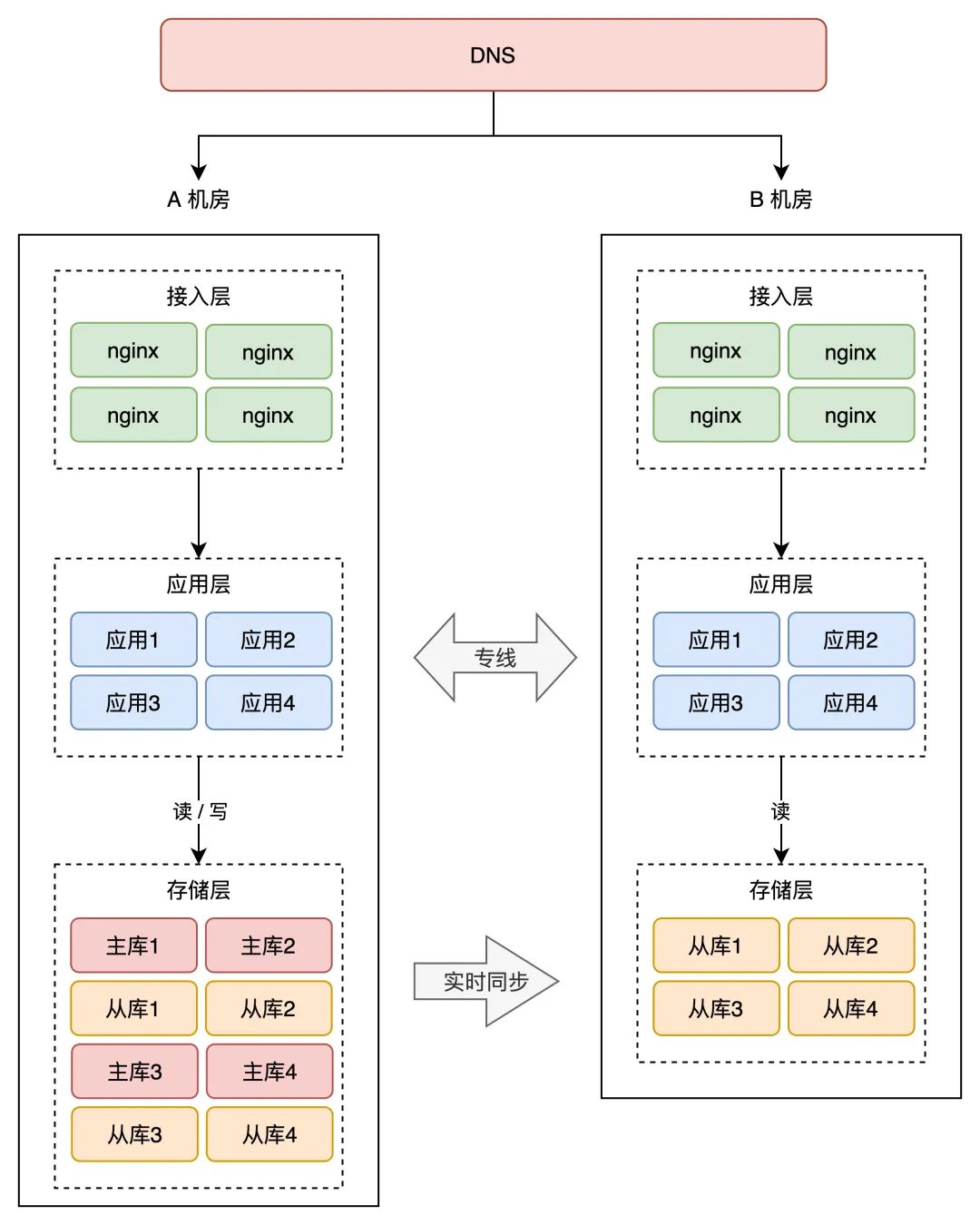
但那里有一个问题:别忘了,B 机房的存储,如今可都是 A 机房的「从库」,从库默承认都是「不成写」的,B 机房的写恳求打到本机房存储上,必定会报错,那仍是不契合我们预期。怎么办?
那时,你就需要在「营业应用」层做革新了。
你的营业应用在操做数据库时,需要区分「读写别离」(一般用中间件实现),即两个机房的「读」流量,能够读肆意机房的存储,但「写」流量,只允许写 A 机房,因为主库在 A 机房。
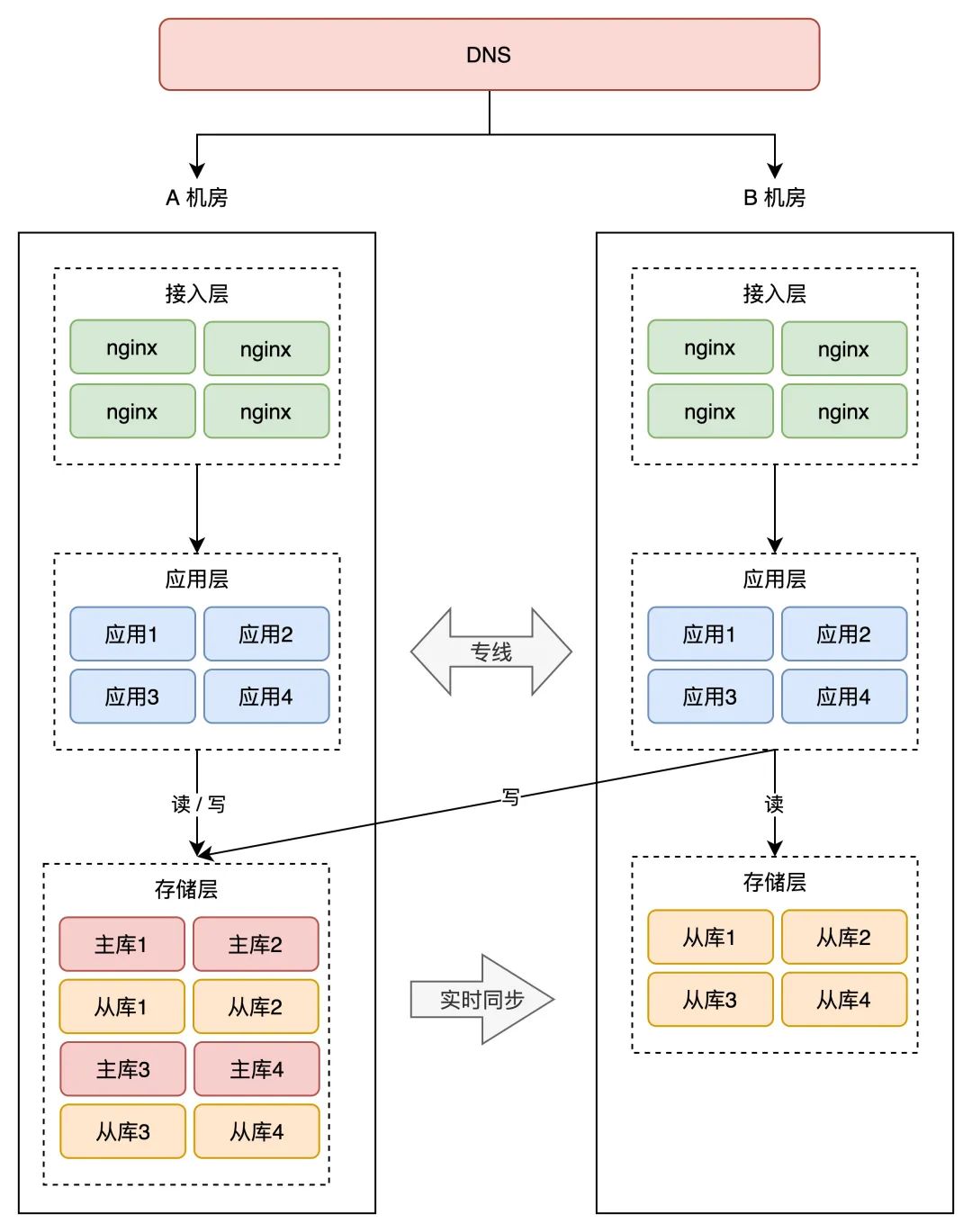
那会涉及到你用的所有存储,例如项目顶用到了 MySQL、Redis、MongoDB 等等,操做那些数据库,都需要区分读写恳求,所以那块需要必然的营业「革新」成本。
因为 A 机房的存储都是主库,所以我们把 A 机房叫做「主机房」,B 机房叫「从机房」。
两个机房摆设在「同城」,物理间隔比力近,并且两个机房用「专线」收集毗连,固然跨机房拜候的延迟,比单个机房内要大一些,但整体的延迟仍是能够承受的。
营业革新完成后,B 机房能够渐渐接入流量,从 10%、30%、50% 逐步笼盖到 100%,你能够持续察看 B 机房的营业能否存在问题,有问题及时修复,逐步让 B 机房的工做才能,到达和 A 机房不异程度。
如今,因为 B 机房实时接入了流量,此时若是 A 机房挂了,那我们就能够「斗胆」地把 A 的流量,全数切换到 B 机房,完成快速切换!
到那里你能够看到,我们摆设的 B 机房,在物理上固然与 A 有必然间隔,但整个系统从「逻辑」上来看,我们是把那两个机房看做一个「整体」来规划的,也就是说,相当于把 2 个机房当做 1 个机房来用。
那种架构计划,比前面的同城灾备更「进了一步」,B 机房实时接入了流量,还能应对随时的毛病切换,那种计划我们把它叫做「同城双活」。
因为两个机房都能处置营业恳求,那对我们系统的内部维护、革新、晋级供给了更多的可施行空间(流量随时切换),如今,整个系统的弹性也变大了,是不是更爽了?
那那种架构有什么问题呢?
07 两地三中心仍是回到风险上来说。
固然我们把 2 个机房当做一个整体来规划,但那 2 个机房在物理层面上,仍是处于「一个城市」内,若是是整个城市发作天然灾祸,例如地震、水灾(河南水灾刚过去不久),那 2 个机房照旧存在「全局覆没」的风险。
实是防不堪防啊?怎么办?没法子,继续冗余。
但此次冗余机房,就不克不及摆设在统一个城市了,你需要把它放到间隔更远的处所,摆设在「异地」。
凡是建议两个机房的间隔要在 1000 公里以上,如许才气应对城市级此外灾难。
假设之前的 A、B 机房在北京,那此次新摆设的 C 机房能够放在上海。
根据前面的思绪,把 C 机房用起来,最简单粗暴的计划还就是做「冷备」,即按时把 A、B 机房的数据,在 C 机房做备份,避免数据丧失。
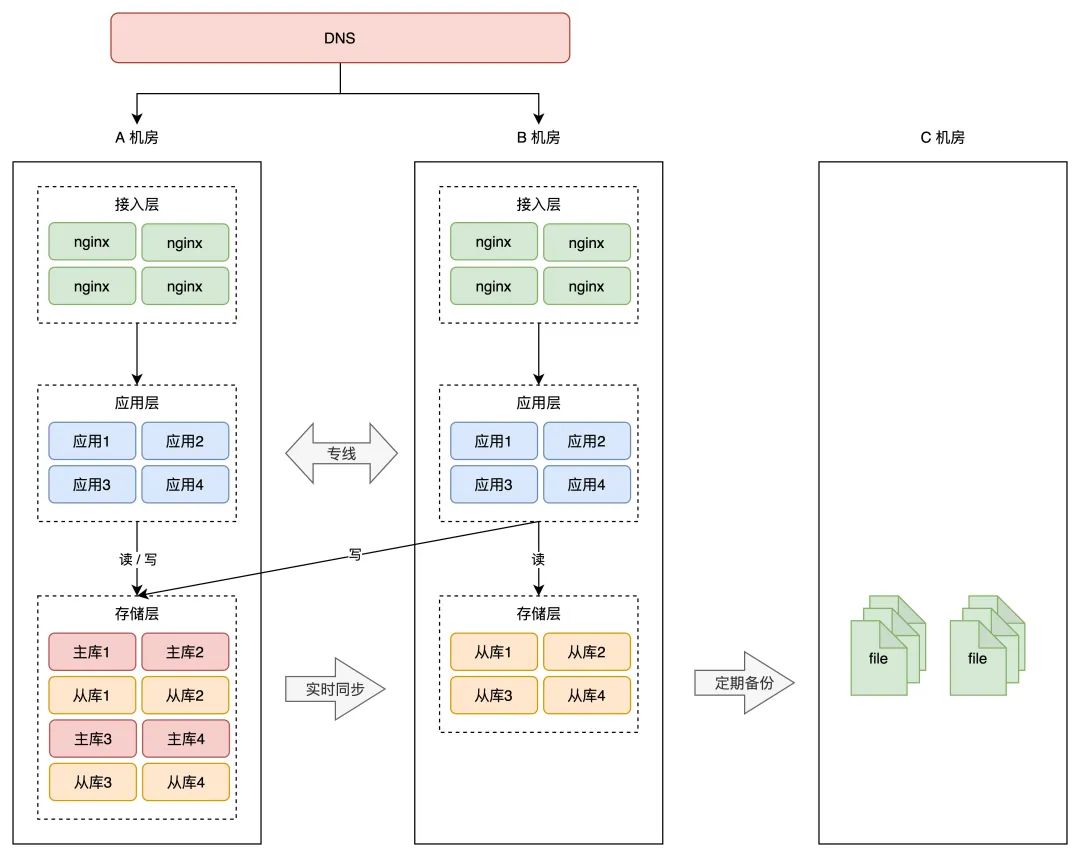
那种计划,就是我们经常听到的「两地三中心」。
两地是指 2 个城市,三中心是指有 3 个机房,此中 2 个机房在统一个城市,而且同时供给办事,第 3 个机房摆设在异地,只做数据灾备。
那种架构计划,凡是用在银行、金融、政企相关的项目中。它的问题仍是前面所说的,启用灾备机房需要时间,并且启用后的办事,不确定能否如期工做。
所以,要想实正的抵御城市级此外毛病,越来越多的互联网公司,起头施行「异地双活」。
08 伪异地双活那里,我们仍是阐发 2 个机房的架构情况。我们不再把 A、B 机房摆设在统一个城市,而是分隔摆设,例如 A 机房放在北京,B 机房放在上海。
前面我们讲了同城双活,那异地双活是不是间接「照搬」同城双活的形式去摆设就能够了呢?
工作没你想的那么简单。
若是仍是根据同城双活的架构来摆设,那异地双活的架构就是如许的:
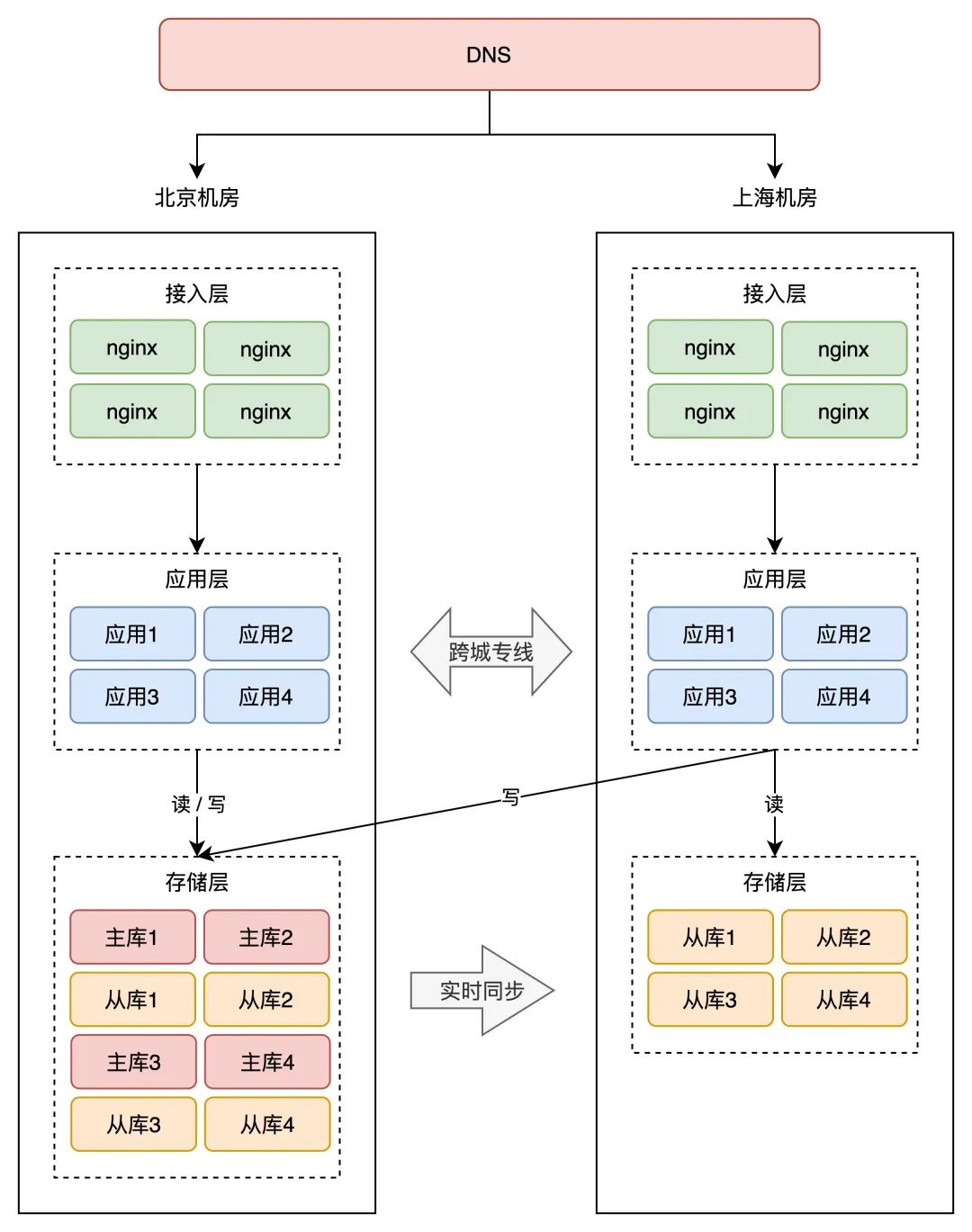
留意看,两个机房的收集是通过「跨城专线」连通的。
此时两个机房都接入流量,那上海机房的恳求,可能要去读写北京机房的存储,那里存在一个很大的问题:收集延迟。
因为两个机房间隔较远,遭到物理间隔的限造,如今,两地之间的收集延迟就酿成了「不成轻忽」的因素了。
北京到上海的间隔大约 1300 公里,即便架设一条高速的「收集专线」,光纤以光速传输,一个来回也需要近 10ms 的延迟。
况且,收集线路之间还会履历各类路由器、交换机等收集设备,现实延迟可能会到达 30ms ~ 100ms,若是收集发作颤动,延迟以至会到达 1 秒。
不行是延迟,远间隔的收集专线量量,是远远达不到机房内收集量量的,专线收集经常会发作延迟、丢包、以至中断的情况。总之,不克不及过度信赖和依赖「跨城专线」。
你可能会问,那点延迟对营业影响很大吗?影响十分大!
试想,一个客户端恳求打到上海机房,上海机房要去读写北京机房的存储,一次跨机房拜候延迟就到达了 30ms,那大致是机房内网收集(0.5 ms)拜候速度的 60 倍(30ms / 0.5ms),一次恳求慢 60 倍,来回往返就要慢 100 倍以上。
而我们在 App 翻开一个页面,可能会拜候后端几十个 API,每次都跨机房拜候,整个页面的响应延迟有可能就到达了秒级,那个性能几乎惨绝人寰,难以承受。
看到了么,固然我们只是简单的把机房摆设在了「异地」,但「同城双活」的架构模子,在那里就不适用了,仍是根据那种体例摆设,那是「伪异地双活」!
那若何做到实正的异地双活呢?
09 实正的异地双活既然「跨机房」挪用延迟是不容轻忽的因素,那我们只能尽量制止跨机房「挪用」,躲避那个延迟问题。
也就是说,上海机房的应用,不克不及再「跨机房」去读写北京机房的存储,只允许读写上海当地的存储,实现「就近拜候」,如许才气制止延迟问题。
仍是之前提到的问题:上海机房存储都是从库,不允许写入啊,除非我们只允许上海机房接入「读流量」,不领受「写流量」,不然无法满足不再跨机房的要求。
很显然,只让上海机房领受读流量的计划不现实,因为很少有项目是只要读流量,没有写流量的。所以那种计划仍是不可,那怎么办?
此时,你就必需在「存储层」做革新了。
要想上海机房读写本机房的存储,那上海机房的存储不克不及再是北京机房的从库,而是也要变成「主库」。
你没看错,两个机房的存储必需都是「主库」,并且两个机房的数据还要「互不异步」数据,即客户端无论写哪一个机房,都能把那条数据同步到另一个机房。
因为只要两个机房都拥有「全量数据」,才气撑持肆意切换机房,持续供给办事。
怎么实现那种「双主」架构呢?它们之间若何互不异步数据?
若是你对 MySQL 有所领会,MySQL 自己就供给了双主架构,它撑持双向复造数据,但日常平凡用的其实不多。并且 Redis、MongoDB 等数据库并没有供给那个功用,所以,你必需开发对应的「数据同步中间件」来实现双向同步的功用。
此外,除了数据库那种有形态的软件之外,你的项目凡是还会利用到动静队列,例如 RabbitMQ、Kafka,那些也是有形态的办事,所以它们也需要开发双向同步的中间件,撑持肆意机房写入数据,同步至另一个机房。
看到了么,那一会儿复杂度就上来了,单单针对每个数据库、队列开发同步中间件,就需要投入很大精神了。
业界也开源出了良多数据同步中间件,例如阿里的 Canal、RedisShake、MongoShake,可别离在两个机房同步 MySQL、Redis、MongoDB 数据。
良多有才能的公司,也会接纳自研同步中间件的体例来做,例如饿了么、协程、美团都开发了本身的同步中间件。
我也有幸参与设想开发了 MySQL、Redis/Codis、MongoDB 的同步中间件,有时间写一篇文章详细聊聊实现细节,欢送持续存眷。:)
如今,整个架构就酿成了如许:
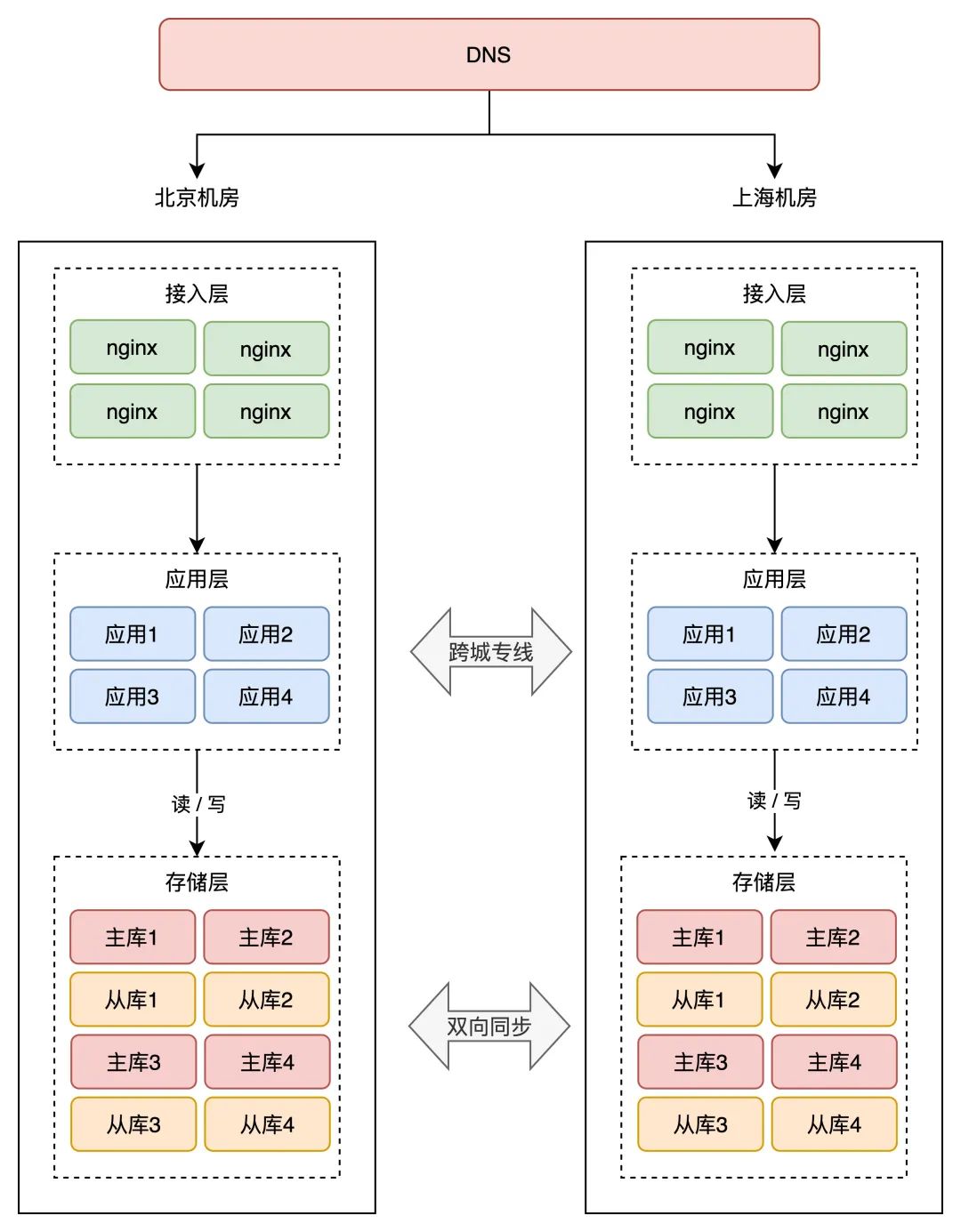
留意看,两个机房的存储层都互不异步数据的。有了数据同步中间件,就能够到达如许的效果:
北京机房写入 X = 1上海机房写入 Y = 2数据通过中间件双向同步北京、上海机房都有 X = 1、Y = 2 的数据那里我们用中间件双向同步数据,就不消再担忧专线问题,专线出问题,我们的中间件能够主动重试,曲到胜利,到达数据最末一致。
但那里还会碰到一个问题,两个机房都能够写,操做的不是统一条数据那还好,若是修改的是统一条的数据,发作抵触怎么办?
用户短时间内发了 2 个修改恳求,都是修改统一条数据一个恳求落在北京机房,修改 X = 1(还未同步到上海机房)另一个恳求落在上海机房,修改 X = 2(还未同步到北京机房)两个机房以哪个为准?也就是说,在很短的时间内,统一个用户修改统一条数据,两个机房无法确认谁先谁后,数据发作「抵触」。
那是一个很严峻的问题,系统发作毛病其实不可怕,可怕的是数据发作「错误」,因为批改数据的成本太高了。我们必然要制止那种情况的发作。处理那个问题,有 2 个计划。
第一个计划,数据同步中间件要有主动「合并」数据、处理「抵触」的才能。
那个计划实现起来比力复杂,要想合并数据,就必需要区分出「先后」挨次。我们很容易想到的计划,就是以「时间」为标尺,以「后抵达」的恳求为准。
但那种计划需要两个机房的「时钟」严酷连结一致才行,不然很容易呈现问题。例如:
第 1 个恳求落到北京机房,北京机房时钟是 10:01,修改 X = 1第 2 个恳求落到上海机房,上海机房时钟是 10:00,修改 X = 2因为北京机房的时间「更晚」,那最末成果就会是 X = 1。但那里其实应该以第 2 个恳求为准,X = 2 才对。
可见,完全「依赖」时钟的抵触处理计划,不太严谨。
所以,凡是会接纳第二种计划,从「泉源」就制止数据抵触的发作。
10 若何施行异地双活既然主动合并数据的计划实现成本高,那我们就要想,能否从泉源就「制止」数据抵触呢?
那个思绪十分棒!
从泉源制止数据抵触的思绪是:在最上层接入流量时,就不要让抵触的情况发作。
详细来讲就是,要在最上层就把用户「区分」开,部门用户恳求固定打到北京机房,其它用户恳求固定打到上海 机房,进入某个机房的用户恳求,之后的所有营业操做,都在那一个机房内完成,从根源上制止「跨机房」。
所以那时,你需要在接入层之上,再摆设一个「路由层」(凡是摆设在云办事器上),本身能够设置装备摆设路由规则,把用户「分流」到差别的机房内。
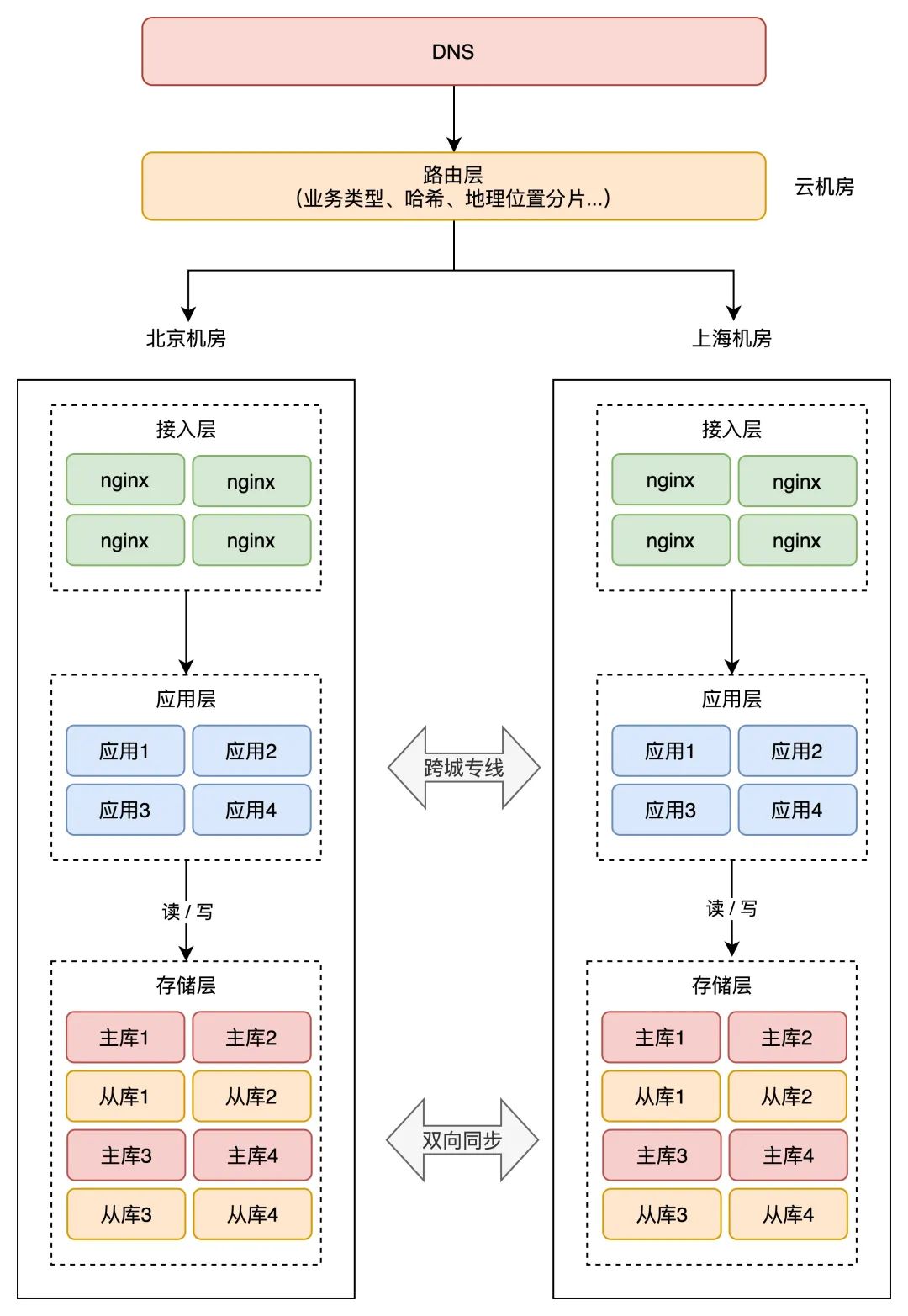
但那个路由规则,详细怎么定呢?有良多种实现体例,最常见的我总结了 3 类:
按营业类型分片间接哈希分片按天文位置分片1、按营业类型分片
那种计划是指,按应用的「营业类型」来划分。
举例:假设我们一共有 4 个应用,北京和上海机房都摆设那些应用。但应用 1、2 只在北京机房接入流量,在上海机房只是热备。应用 3、4 只在上海机房接入流量,在北京机房是热备。
如许一来,应用 1、2 的所有营业恳求,只读写北京机房存储,应用 3、4 的所有恳求,只会读写上海机房存储。
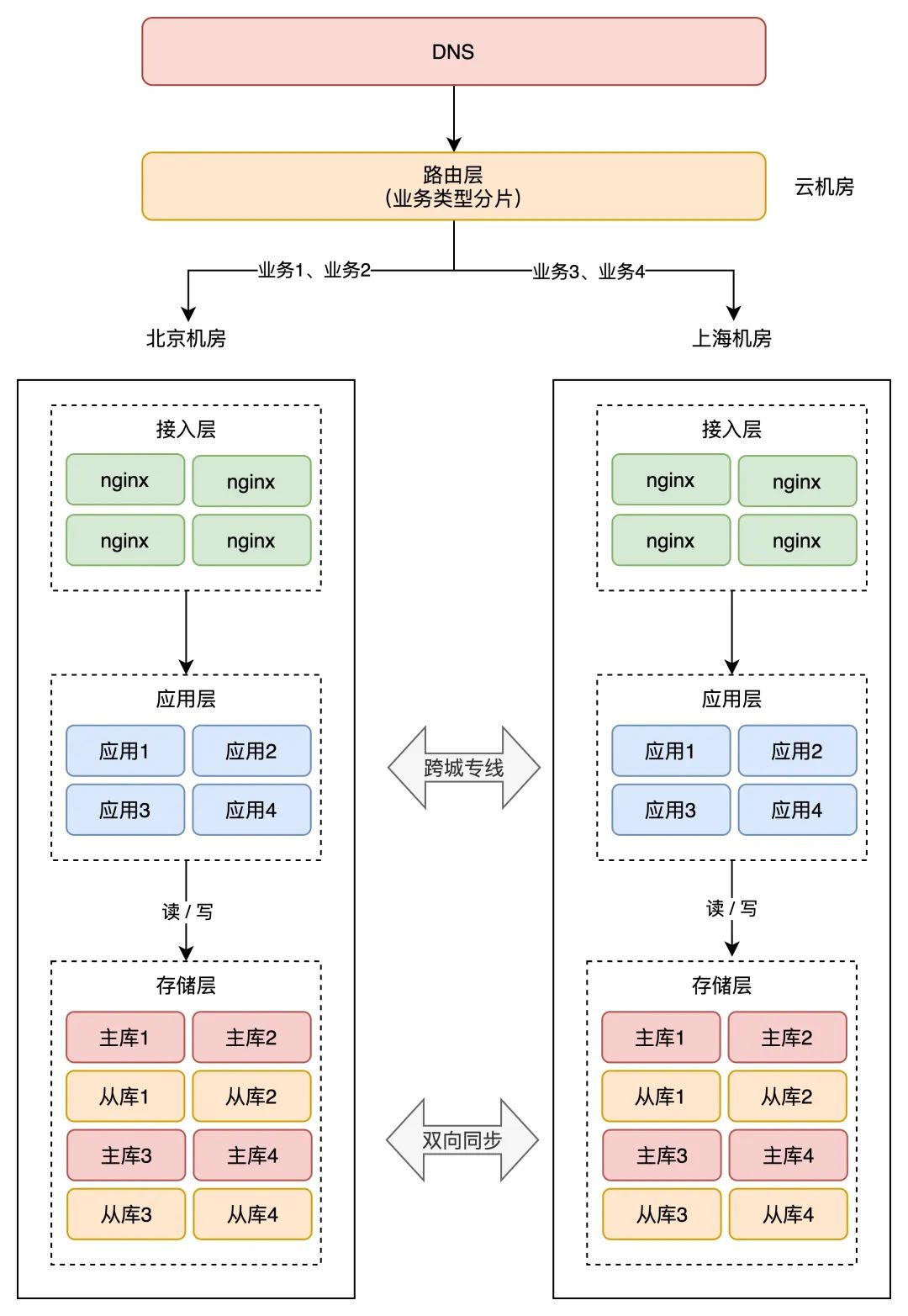
如许按营业类型分片,也能够制止统一个用户修改统一条数据。
那里按营业类型在差别机房接入流量,还需要考虑多个应用之间的依赖关系,要尽可能的把完成「相关」营业的应用摆设在统一个机房,制止跨机房挪用。
例如,订单、付出办事有依赖关系,会产生互相挪用,那那 2 个办事在 A 机房接入流量。社区、发服帖务有依赖关系,那那 2 个办事在 B 机房接入流量。
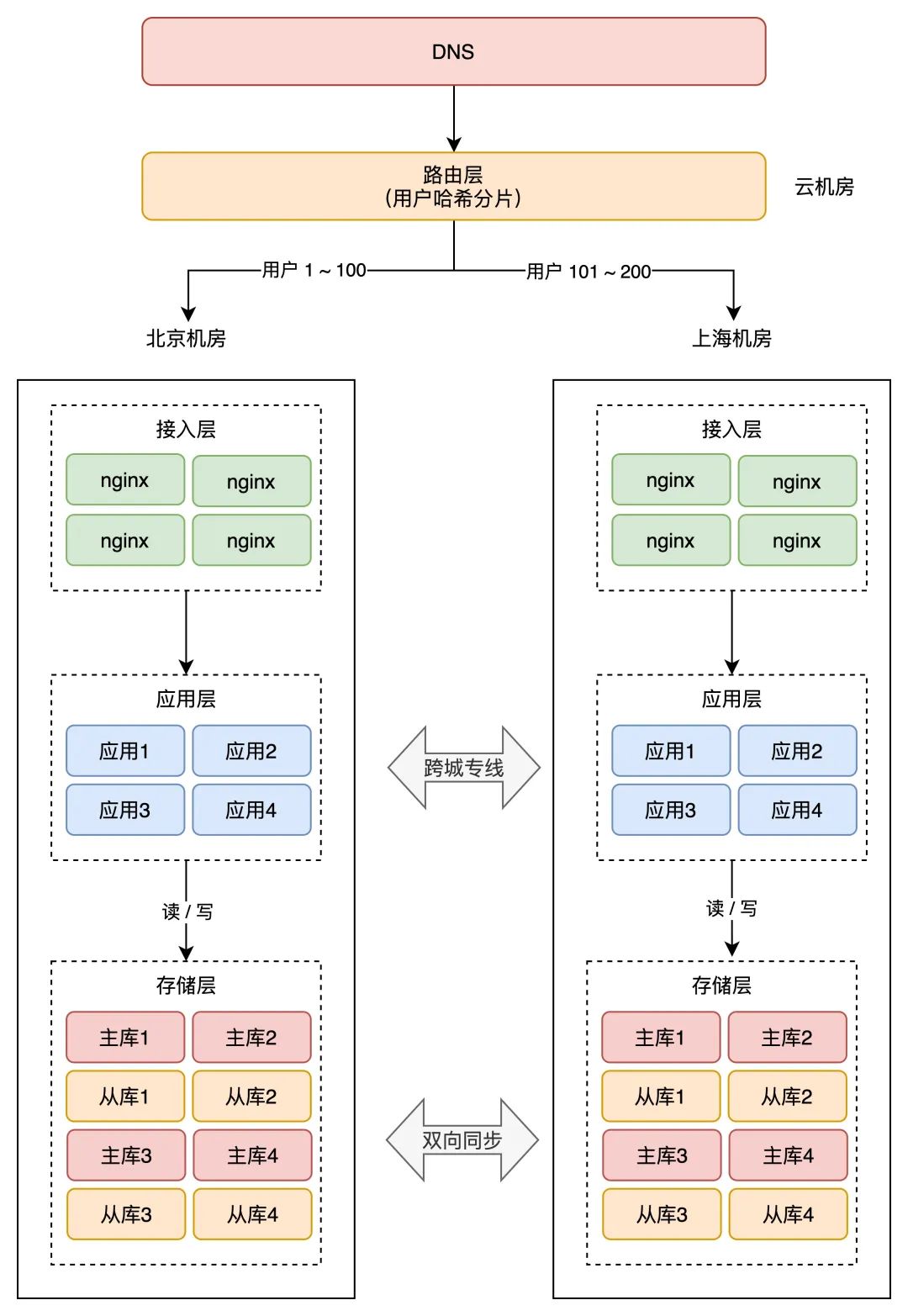
2、间接哈希分片
那种计划就是,最上层的路由层,会按照用户 ID 计算「哈希」取模,然后从路由表中找到对应的机房,之后把恳求转发到指定机房内。
举例:一共 200 个用户,按照用户 ID 计算哈希值,然后按照路由规则,把用户 1 - 100 路由到北京机房,101 - 200 用户路由到上海机房,如许,就制止了统一个用户修改统一条数据的情况发作。
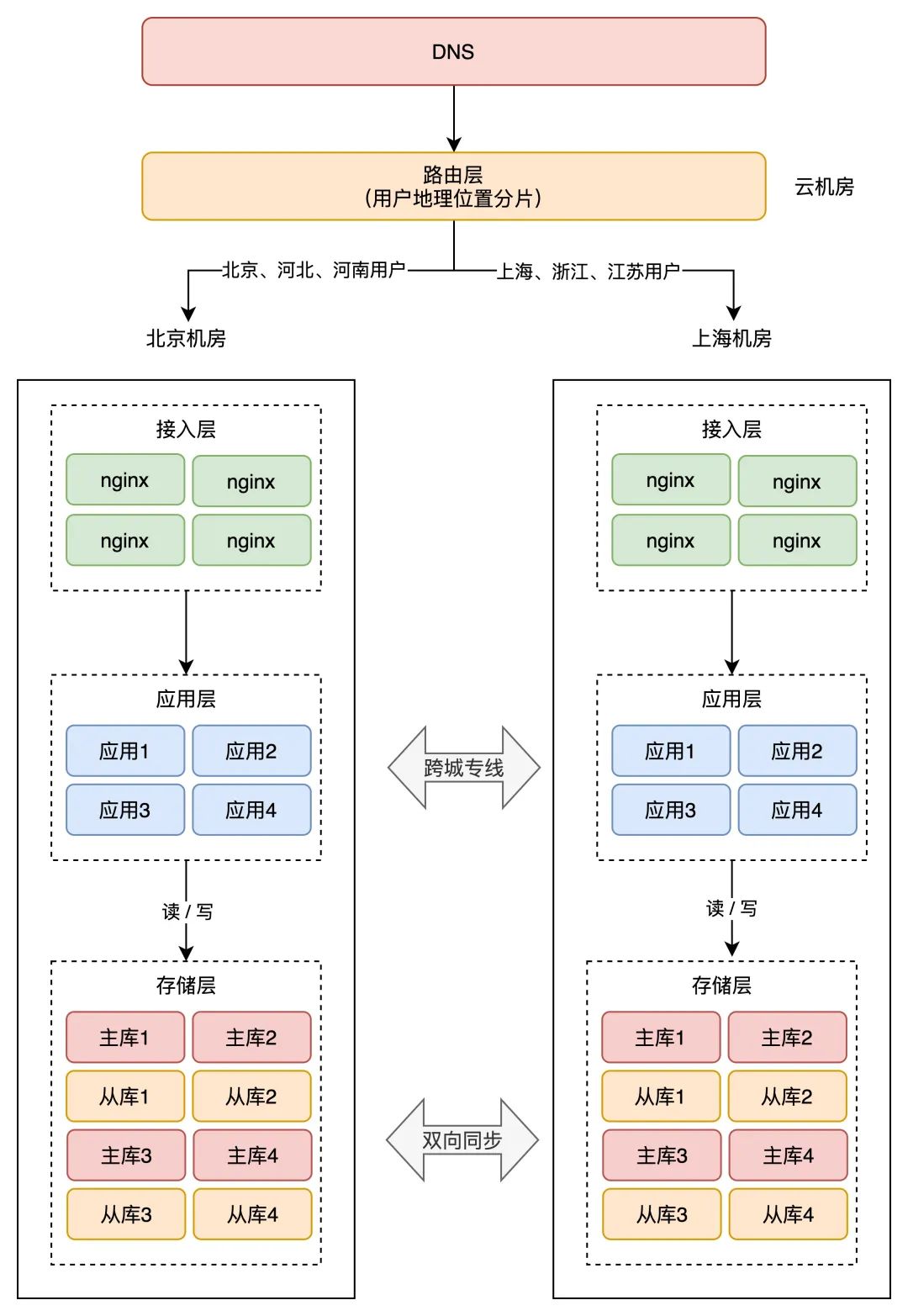
3、按天文位置分片
那种计划,十分合适与天文位置亲近相关的营业,例如打车、外卖办事就十分合适那种计划。
拿外卖办事举例,你要点外卖必定是「就近」点餐,整个营业范畴相关的有商家、用户、骑手,它们都是在不异的天文位置内的。
针对那种特征,就能够在最上层,按用户的「天文位置」来做分片,分离到差别的机房。
举例:北京、河北地域的用户点餐,恳求只会打到北京机房,而上海、浙江地域的用户,恳求则只会打到上海机房。如许的分片规则,也能制止数据抵触。
提醒:那 3 种常见的分片规则,第一次看不太好理解,建议共同图多理解几遍。搞懂那 3 个分片规则,你才气实正大白怎么做异地多活。
总之,分片的核心思绪在于,让统一个用户的相关恳求,只在一个机房内完成所有营业「闭环」,不再呈现「跨机房」拜候。
阿里在施行那种计划时,给它起了个名字,叫做「单位化」。
当然,最上层的路由层把用户分片后,理论来说统一个用户只会落在统一个机房内,但不排除法式 Bug 招致用户会在两个机房「漂移」。
平安起见,每个机房在写存储时,还需要有一套机造,可以检测「数据归属」,应用层操做存储时,需要通过中间件来做「兜底」,制止不应写本机房的情况发作。(篇幅限造,那里不展开讲,理解思绪即可)
如今,两个机房就能够都领受「读写」流量(做好分片的恳求),底层存储连结「双向」同步,两个机房都拥有全量数据,当肆意机房毛病时,另一个机房就能够「接收」全数流量,实现快速切换,几乎不要太爽。
不只如斯,因为机房摆设在异地,我们还能够更细化地「优化」路由规则,让用户拜候就近的机房,如许整个系统的性能也会大大提拔。
那里还有一种情况,是无法做数据分片的:全局数据。例如系统设置装备摆设、商品库存那类需要强一致的数据,那类办事照旧只能接纳写主机房,读从机房的计划,不做双活。
双活的重点,是要优先包管「核心」营业先实现双活,并非「全数」营业实现双活。
至此,我们才算实现了实正的「异地双活」!
到那里你能够看出,完成如许一套架构,需要投入的成本是庞大的。
路由规则、路由转发、数据同步中间件、数据校验兜底战略,不只需要开发强大的中间件,同时还要营业共同革新(营业鸿沟划分、依赖拆分)等一些列工做,没有足够的人力物力,那套架构很难施行。
11 异地多活理解了异地双活,那「异地多活」望文生义,就是在异地双活的根底上,摆设多个机房即可。架构酿成了如许:
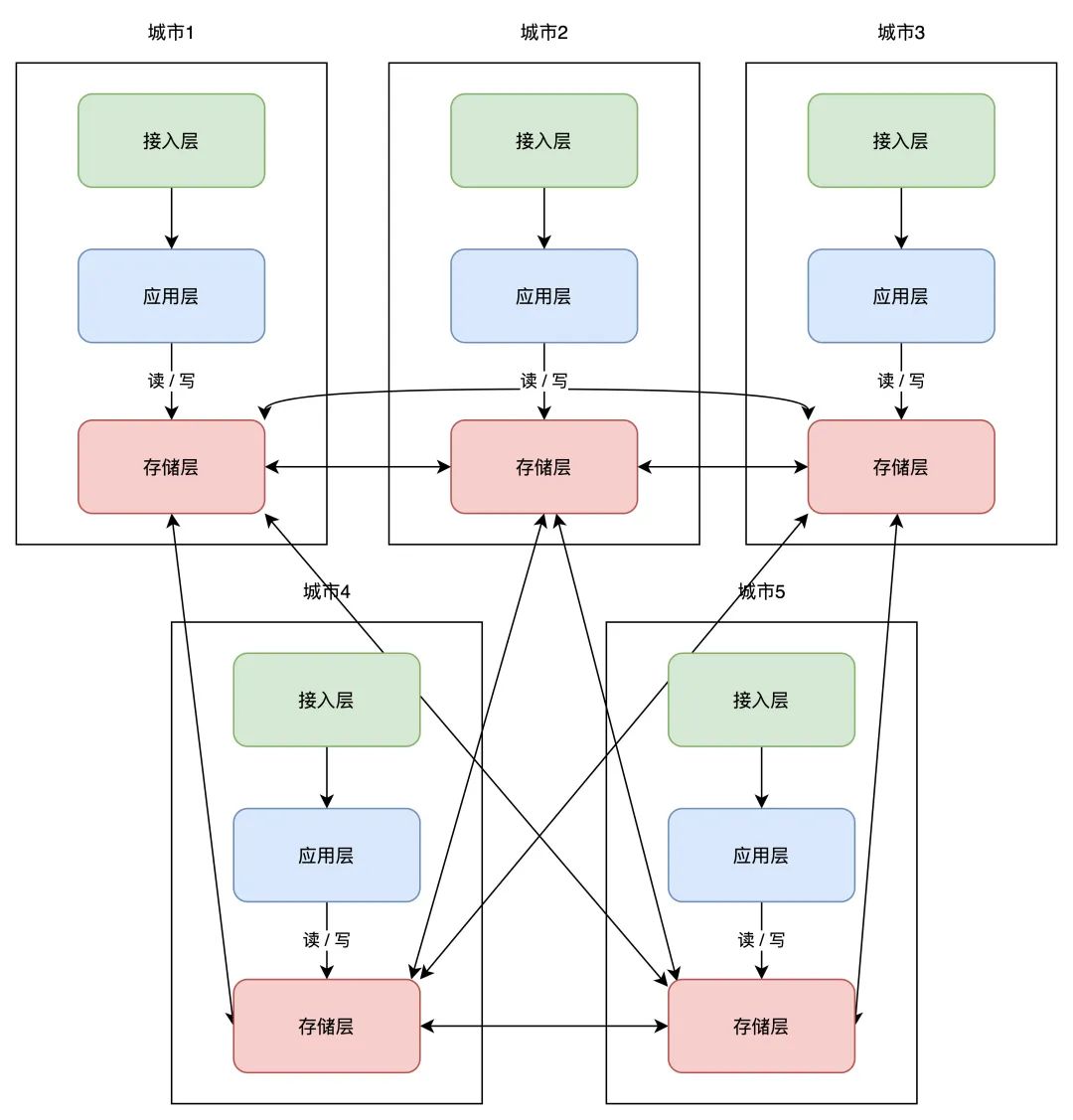
那些办事根据「单位化」的摆设体例,能够让每个机房摆设在肆意地域,随时扩展新机房,你只需要在最上层定义好分片规则就好了。
但那里还有一个小问题,跟着扩展的机房越来越多,当一个机房写入数据后,需要同步的机房也越来越多,那个实现复杂度会比力高。
所以业界又把那一架构又做了进一步优化,把「网状」架构晋级为「星状」:
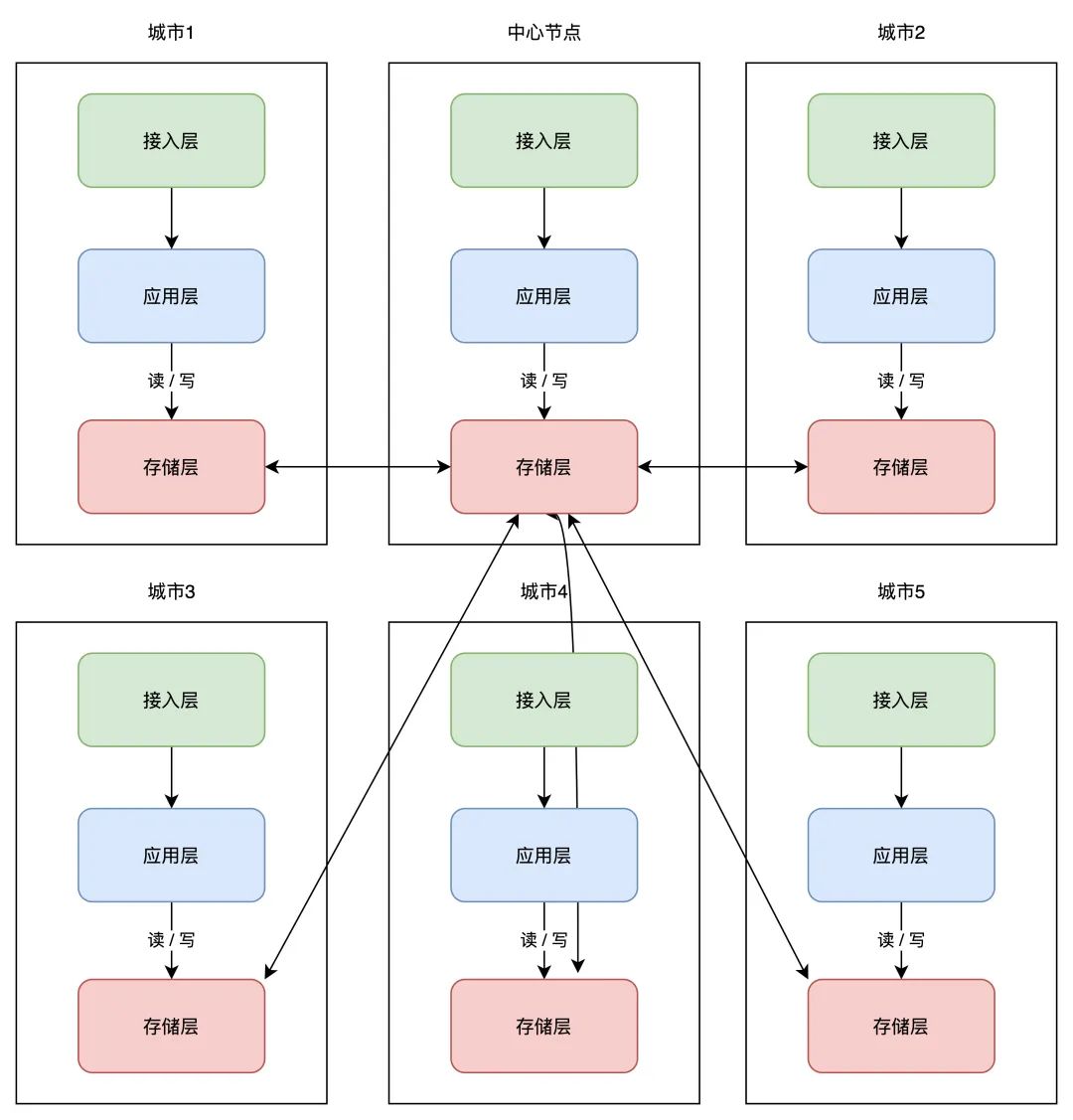
那种计划必需设立一个「中心计心情房」,肆意机房写入数据后,都只同步到中心计心情房,再由中心计心情房同步至其它机房。
如许做的益处是,一个机房写入数据,只需要同步数据到中心计心情房即可,不需要再关心一共摆设了几个机房,实现复杂度大大「简化」。
但与此同时,那个中心计心情房的「不变性」要求会比力高。不外也还好,即便中心计心情房发作毛病,我们也能够把肆意一个机房,提拔为中心计心情房,继续根据之前的架构供给办事。
至此,我们的系统彻底实现了「异地多活」!
多活的优势在于,能够肆意扩展机房「就近」摆设。肆意机房发作毛病,能够完成快速「切换」,大大进步了系统的可用性。
同时,我们也再也不消担忧系统规模的增长,因为那套架构具有极强的「扩展才能」。
怎么样?我们从一个最简单的应用,一路优化下来,到最末的架构计划,有没有帮你彻底理解异地多活呢?
总结好了,总结一下那篇文章的重点。
1、一个好的软件架构,应该遵照高性能、高可用、易扩展 3 大原则,此中「高可用」在系统规模变得越来越大时,变得尤为重要
2、系统发作毛病其实不可怕,能以「最快」的速度恢复,才是高可用逃求的目的,异地多活是实现高可用的有效手段
3、提拔高可用的核心是「冗余」,备份、主从副本、同城灾备、同城双活、两地三中心、异地双活,异地多活都是在做冗余
4、同城灾备分为「冷备」和「热备」,冷备只备份数据,不供给办事,热备实时同步数据,并做好随时切换的筹办
5、同城双活比灾备的优势在于,两个机房都能够接入「读写」流量,进步可用性的同时,还提拔了系统性能。固然物理上是两个机房,但「逻辑」上仍是当做一个机房来用
6、两地三中心是在同城双活的根底上,额外摆设一个异地机房做「灾备」,用来抵御「城市」级此外灾祸,但启用灾备机房需要时间
7、异地双活才是抵御「城市」级别灾祸的更好计划,两个机房同时供给办事,毛病随时可切换,可用性高。但实现也最复杂,理解了异地双活,才气彻底理解异地多活
8、异地多活是在异地双活的根底上,肆意扩展多个机房,不只又进步了可用性,还能应对更大规模的流量的压力,扩展性最强,是实现高可用的最末计划
以上,我们下篇见。
:Tomcat 打破双亲委派")



还没有评论,来说两句吧...