
在上一篇文章,我们分析了 MyBatis 的插件原理,本篇,我们就深入分析一下 PageHelper 到底是如何实现的。
先来看一下 PageHelper 如何使用,首先引入 PageHelper 的依赖包
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.2.3</version>
</dependency>
这里我使用的是 SpringBoot,所以已经有 AutoConfiguration 自动配置好了,没有特殊要求使用默认配置直接使用即可。
使用示例:
// public static <E> Page<E> startPage(int pageNum, int pageSize)
PageHelper.startPage(page,row);
// 这里到底是如何分页的?
List<Article> articles = this.articleDao.selectArticleList(type,ishot,key,year);
// PageInfo 包装结果
PageInfo<Article> pageInfo = new PageInfo<>(articles);
// 从 PageInfo 中获取一些分页信息,比如总条数
int size = pageInfo.getTotal();
1.执行流程
在上一篇文章,我们已经说了插件的调用逻辑是:JDK 动态代理类 => Plugin#invoke() => Interceptor#Intercept(),所以我们直接来看 PageHelper 的 Intercept() 方法:
public Object intercept(Invocation invocation) throws Throwable {
try {
Object[] args = invocation.getArgs();
MappedStatement ms = (MappedStatement) args[0];
Object parameter = args[1];
RowBounds rowBounds = (RowBounds) args[2];
ResultHandler resultHandler = (ResultHandler) args[3];
Executor executor = (Executor) invocation.getTarget();
CacheKey cacheKey;
BoundSql boundSql;
//由于逻辑关系,只会进入一次
if(args.length == 4){
//4 个参数时
boundSql = ms.getBoundSql(parameter);
cacheKey = executor.createCacheKey(ms, parameter, rowBounds, boundSql);
} else {
//6 个参数时
cacheKey = (CacheKey) args[4];
boundSql = (BoundSql) args[5];
}
List resultList;
//调用方法判断是否需要进行分页,如果不需要,直接返回结果
if (!dialect.skip(ms, parameter, rowBounds)) {
//反射获取动态参数
String msId = ms.getId();
Configuration configuration = ms.getConfiguration();
Map<String, Object> additionalParameters = (Map<String, Object>) additionalParametersField.get(boundSql);
//判断是否需要进行 count 查询
if (dialect.beforeCount(ms, parameter, rowBounds)) {
String countMsId = msId + countSuffix;
Long count;
//先判断是否存在手写的 count 查询
MappedStatement countMs = getExistedMappedStatement(configuration, countMsId);
if(countMs != null){
count = executeManualCount(executor, countMs, parameter, boundSql, resultHandler);
} else {
countMs = msCountMap.get(countMsId);
//自动创建
if (countMs == null) {
//根据当前的 ms 创建一个返回值为 Long 类型的 ms
countMs = MSUtils.newCountMappedStatement(ms, countMsId);
msCountMap.put(countMsId, countMs);
}
count = executeAutoCount(executor, countMs, parameter, boundSql, rowBounds, resultHandler);
}
//处理查询总数
//返回 true 时继续分页查询,false 时直接返回
if (!dialect.afterCount(count, parameter, rowBounds)) {
//当查询总数为 0 时,直接返回空的结果
return dialect.afterPage(new ArrayList(), parameter, rowBounds);
}
}
//判断是否需要进行分页查询
if (dialect.beforePage(ms, parameter, rowBounds)) {
//生成分页的缓存 key
CacheKey pageKey = cacheKey;
//处理参数对象
parameter = dialect.processParameterObject(ms, parameter, boundSql, pageKey);
//调用方言获取分页 sql
String pageSql = dialect.getPageSql(ms, boundSql, parameter, rowBounds, pageKey);
BoundSql pageBoundSql = new BoundSql(configuration, pageSql, boundSql.getParameterMappings(), parameter);
//设置动态参数
for (String key : additionalParameters.keySet()) {
pageBoundSql.setAdditionalParameter(key, additionalParameters.get(key));
}
//执行分页查询
resultList = executor.query(ms, parameter, RowBounds.DEFAULT, resultHandler, pageKey, pageBoundSql);
} else {
//不执行分页的情况下,也不执行内存分页
resultList = executor.query(ms, parameter, RowBounds.DEFAULT, resultHandler, cacheKey, boundSql);
}
} else {
//rowBounds用参数值,不使用分页插件处理时,仍然支持默认的内存分页
resultList = executor.query(ms, parameter, rowBounds, resultHandler, cacheKey, boundSql);
}
return dialect.afterPage(resultList, parameter, rowBounds);
} finally {
dialect.afterAll();
}
}
其中跟分页的核心代码是: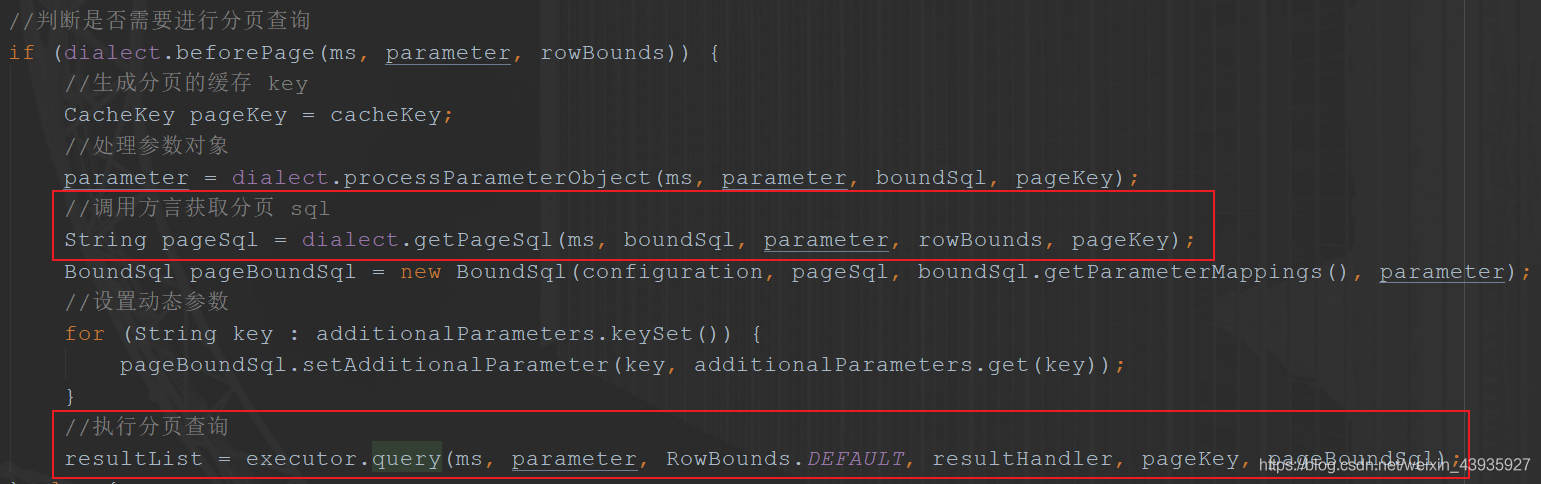
可以看到,通过 getPageSql() 根据原 sql 取新的分页 sql,然后直接调用 Executor 去执行 sql。
注:这里没有像我们上一篇说的那样,调用 Invocation#proceed() 去执行原方法,因为要执行新的添加了分页的 sql,所以是直接拿出 Executor(target)去执行。
点进去 getPage() 方法,最后走到了 AbstractHelperDialect#getPageSql()
注:这里其实还有一个 AbstractRowBoundDialect,是内存分页,我们这里要选择 AbstractHelperDialect
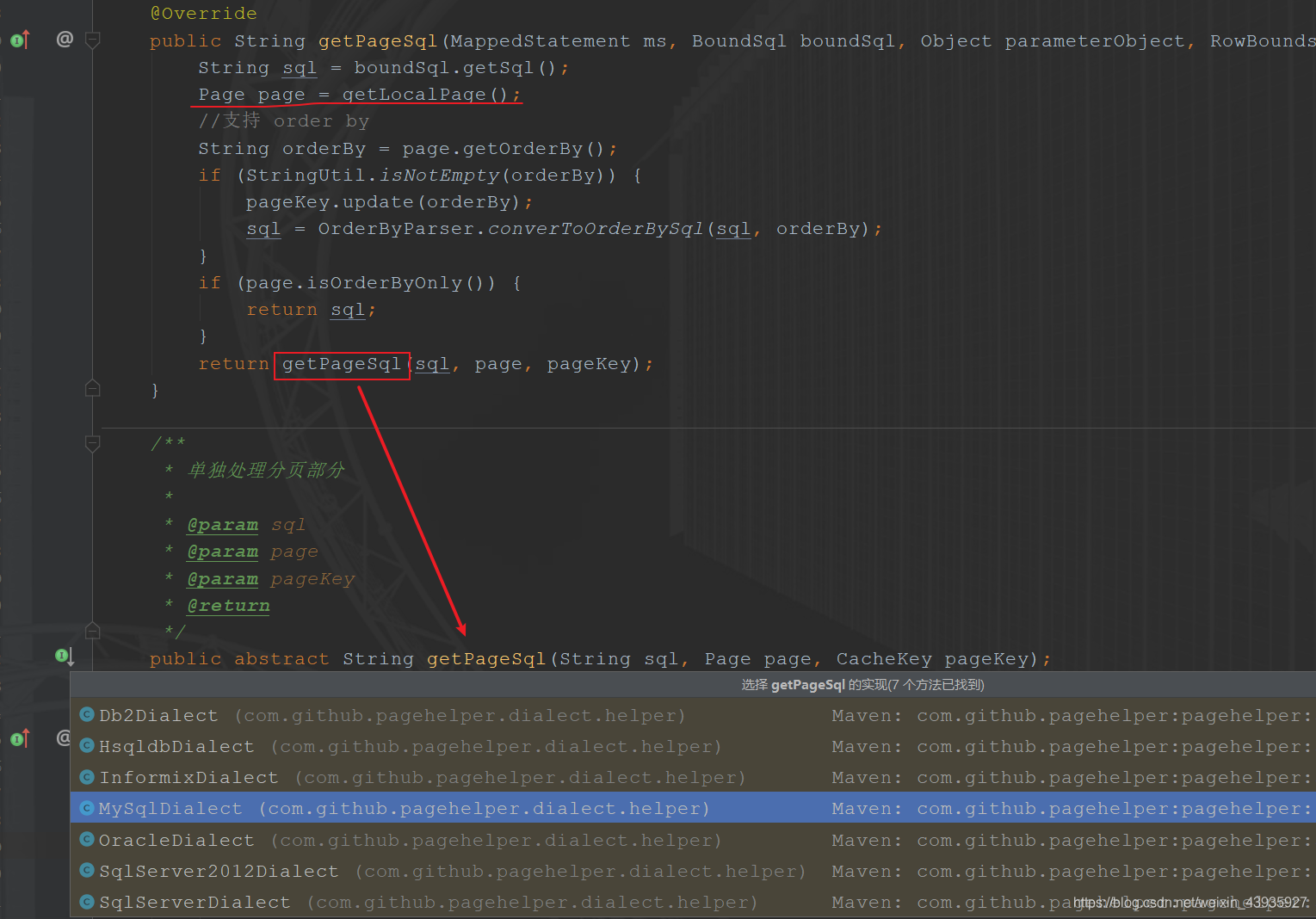
然后点进 MysqlDialect,看看它是怎么实现 getPageSql()
@Override
public String getPageSql(String sql, Page page, CacheKey pageKey) {
StringBuilder sqlBuilder = new StringBuilder(sql.length() + 14);
sqlBuilder.append(sql);
if (page.getStartRow() == 0) {
sqlBuilder.append(" LIMIT ? ");
} else {
sqlBuilder.append(" LIMIT ?, ? ");
}
pageKey.update(page.getPageSize());
return sqlBuilder.toString();
}
可以看到,是在这里对 SQL 语句进行了改写,即拼接了 Limit;
我们已经看到了,PageHelper 本质是对要执行的 SQL 语句进行了改写,但是这里其实还有三个问题
- 分页的参数是保存在哪里呢?
- PageHelper.startPage() 设置的分页参数是如何传递到 MysqlDialect 的?
- PageInfo 为什么能拿到返回结果的其余分页信息呢?
2.分页参数保存哪里?
分页相关参数,在 PageHelper 这个插件中,是新封装了一个 Page 对象来保存的。Page 本质就是一个 List,只不过自定义了一些分页相关的成员变量。
public class Page<E> extends ArrayList<E> implements Closeable {
private static final long serialVersionUID = 1L;
/**
* 页码,从1开始
*/
private int pageNum;
/**
* 页面大小
*/
private int pageSize;
/**
* 起始行
*/
private int startRow;
/**
* 末行
*/
private int endRow;
/**
* 总数
*/
private long total;
/**
* 总页数
*/
private int pages;
/**
* 包含count查询
*/
private boolean count = true;
/**
* 分页合理化
*/
private Boolean reasonable;
/**
* 当设置为true的时候,如果pagesize设置为0(或RowBounds的limit=0),就不执行分页,返回全部结果
*/
private Boolean pageSizeZero;
/**
* 进行count查询的列名
*/
private String countColumn;
/**
* 排序
*/
private String orderBy;
/**
* 只增加排序
*/
private boolean orderByOnly;
// getter...
}
PS:正是因为 Page 是 List,保存的就是原来 SQL 查找的元素,所以,才能满足代理后返回结果的类型与原 SQL 返回类型相同。
3.拼接 SQL 时如何获取分页参数?
我们点进 startPage() 方法,它走到了 PageMethod 类中(它是 PageHelper 的父类);另外,startPage() 有多个重载方法,而最终是走到了全参的方法
/**
* 开始分页
*
* @param pageNum 页码
* @param pageSize 每页显示数量
* @param count 是否进行count查询
* @param reasonable 分页合理化,null时用默认配置
* @param pageSizeZero true且pageSize=0时返回全部结果,false时分页,null时用默认配置
*/
public static <E> Page<E> startPage(int pageNum, int pageSize, boolean count, Boolean reasonable, Boolean pageSizeZero) {
// 利用分页参数构造 Page 对象
Page<E> page = new Page<E>(pageNum, pageSize, count);
page.setReasonable(reasonable);
page.setPageSizeZero(pageSizeZero);
// 当已经执行过orderBy的时候
Page<E> oldPage = getLocalPage();
if (oldPage != null && oldPage.isOrderByOnly()) {
page.setOrderBy(oldPage.getOrderBy());
}
// 将 Page 对象保存到 ThreadLocal
setLocalPage(page);
return page;
}
/**
* 设置 Page 参数
*
* @param page
*/
protected static void setLocalPage(Page page) {
LOCAL_PAGE.set(page);
}
上面的 LOCAL_PAGE 是一个 ThreadLocal 变量

下面我们回到 MysqlDialect#getPageSql() 方法,可以看到,它的 Page 是在被调用时作为参数传入的;所以再来看 AbstractHelperDialect#getPageSql() ,不难发现,Page 对象就是通过 getLocalPage() 方法获取的(上面的图已经标出),而它最终也是从 PageMethod 的 LOCAL_PAGE 中获取的:

这也正是为什么当我们要使用分页时,不用修改原有的 Dao 层接口。
小结一下,PageHelper.startPage(pageNum, pageSize) 实际做的事情是在 ThreadLocal中设置了分页参数,之后在查询执行的时候,获取当线程中的分页参数,执行查询的时候通过拦截器在 sql 语句中添加分页参数,之后实现分页查询,查询结束后在 finally 语句中清除ThreadLocal中的查询参数。
4.如何获取查询结果的分页信息?
在上面我们也说了,Page 本质是一个 List,保存的查找的元素,另外,又额外保存了分页相关的一些信息。而 PageInterceptor#Intercept() 返回的就是 Page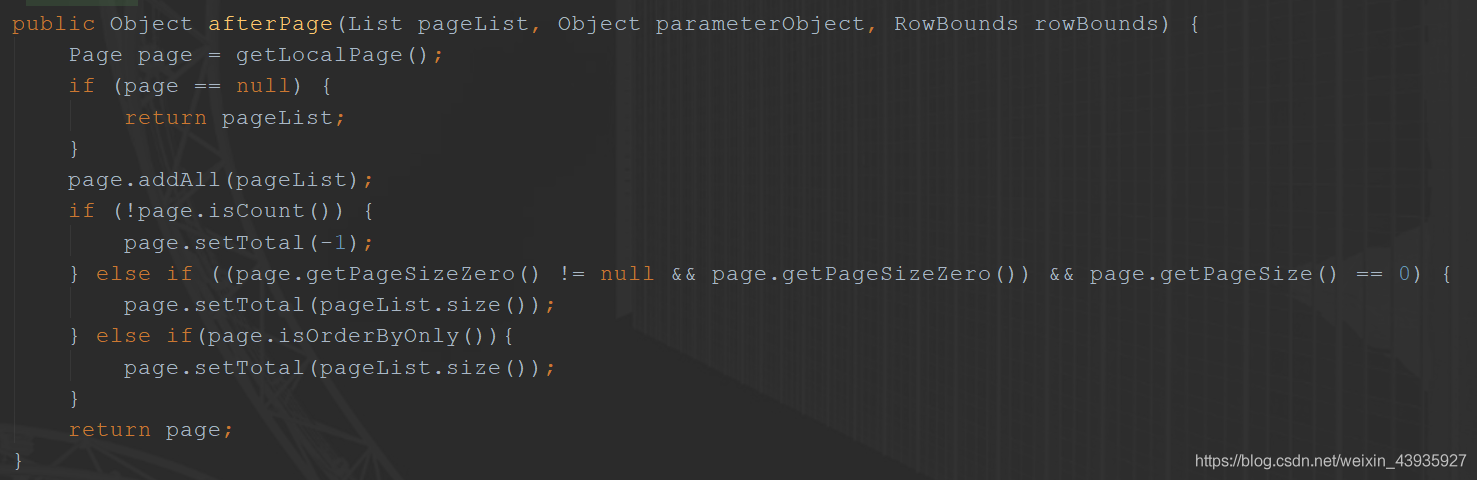
下面,我们点看 PageInfo 的构造函数看看
/**
* 包装Page对象
*
* @param list page结果
* @param navigatePages 页码数量
*/
public PageInfo(List<T> list, int navigatePages) {
// 如果该 List 是 Page 的实例
// 注:当通过 PageHelper 进行分页查询后返回的 List 就是 Page 的实例
if (list instanceof Page) {
Page page = (Page) list;
this.pageNum = page.getPageNum();
this.pageSize = page.getPageSize();
this.pages = page.getPages();
this.list = page;
this.size = page.size();
this.total = page.getTotal();
//由于结果是>startRow的,所以实际的需要+1
if (this.size == 0) {
this.startRow = 0;
this.endRow = 0;
} else {
this.startRow = page.getStartRow() + 1;
//计算实际的endRow(最后一页的时候特殊)
this.endRow = this.startRow - 1 + this.size;
}
// 如果该 List 就是一个普通的 List
} else if (list instanceof Collection) {
this.pageNum = 1;
this.pageSize = list.size();
this.pages = this.pageSize > 0 ? 1 : 0;
this.list = list;
this.size = list.size();
this.total = list.size();
this.startRow = 0;
this.endRow = list.size() > 0 ? list.size() - 1 : 0;
}
if (list instanceof Collection) {
this.navigatePages = navigatePages;
//计算导航页
calcNavigatepageNums();
//计算前后页,第一页,最后一页
calcPage();
//判断页面边界
judgePageBoudary();
}
}
上面代码一看其实就一目了然了,通过 PageHelper 分页查询出的 List 是 Page 的实例,而 PageInfo 就是做了这么个判断,然后拿出 Page 的其余成员变量罢了。
5.核心对象小结
| 对象 | 作用 |
|---|---|
| PageHelper | 工具类 |
| PageInterceptor | 自定义拦截器 |
| Page | 包装分页参数 |
| PageInfo | 包装结果 |
:如何实现一个插件")
:插件实现逻辑分析")
:编程式使用(单用)及核心对象生命周期")
:创建会话工厂(SqlSessionFactory) --配置解析源码分析")
还没有评论,来说两句吧...