
1.面向流与面向缓冲
Java NIO 和 BIO 之间第一个最大的区别是,BIO 是面向流的,NIO 是面向缓冲区的。
- Java BIO 面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。
- Java NIO 的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
2.阻塞与非阻塞
Java BIO 的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。
Java NIO 是非阻塞模式,一个线程从某通道发送请求读取数据,它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。
PS:线程通常将非阻塞 IO 的空闲时间用于在其它通道上执行IO 操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
3.选择器
Java NIO 的选择器(Selector)允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
| BIO | NIO | |
|---|---|---|
| 通信 | 面向流(乡村公路) | 面向缓冲(高速公路,多路复用技术) |
| 处理 | 阻塞IO(多线程) | 非阻塞IO(反应堆 Reactor) |
| 触发 | 无 | 选择器(轮询机制) |
除了上面三点之外,我们对 BIO,NIO 感受最深应该就是在程序编写时的不同。
4.应用程序设计
无论选择BIO 或NIO 工具箱,可能会影响应用程序设计的以下几个方面:
- 对NIO 或BIO 类的 API 调用
- 数据处理逻辑
- 用来处理数据的线程数
1.API调用
使用 NIO 的 API 时看起来与使用 BIO 时有所不同,但这并不意外,因为并不是仅从一个 InputStream 逐字节读取,而是数据必须先读入缓冲区再处理。
2.数据处理
使用纯粹的NIO 设计相较BIO 设计,数据处理也受到影响。在BIO 设计中,我们从 InputStream 或 Reader 逐字节读取数据。假设你正在处理一基于行的文本数据流,例如有如下一段文本:
Name:Zhangsan
Age:30
Email: zs@163.com
Phone:12345678910
该文本行的流可以这样处理
FileInputStream input = new FileInputStream("C://info.txt");
BufferedReader reader = new BufferedReader(new InputStreamReader(input));
String nameLine = reader.readLine();
String ageLine = reader.readLine();
String emailLine = reader.readLine();
String phoneLine = reader.readLine();
请注意,处理状态由程序执行多久决定。换句话说,一旦reader.readLine()方法返回,你就知道肯定文本行就已读完,readline() 阻塞直到整行读完,这就是原因。你也知道此行包含名称;同样,第二个 readline() 调用返回的时候,你知道这行包含年龄等。 正如你可以看到,该处理程序仅在有新数据读入时运行,并知道每步的数据是什么。
(Java BIO: 从一个阻塞的流中读数据) 而一个NIO 的实现会有所不同,下面是一个简单的例子:
ByteBuffer buffer = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buffer)
注意第二行,从通道读取字节到ByteBuffer。当这个方法调用返回时,你不知道你所需的所有数据是否在缓冲区内。你所知道的是,该缓冲区包含一些字节,这使得处理有点困难。
假设第一次 read(buffer)调用后,读入缓冲区的数据只有半行,例如,“Name:Zhang”,你能处理数据吗?显然不能,需要等待,直到整行数据读入缓存,在此之前,对数据的任何处理毫无意义。所以,你怎么知道是否该缓冲区包含足够的数据可以处理呢?好了,你不知道。发现的方法只能查看缓冲区中的数据。
其结果是,在你知道所有数据都在缓冲区里之前,你必须检查几次缓冲区的数据。这不仅效率低下,而且可以使程序设计方案杂乱不堪。
3.设置处理线程数
NIO 可只使用一个(或几个)单线程管理多个通道(网络连接或文件),但付出的代价是解析数据可能会比从一个阻塞流中读取数据更复杂。
如果需要管理同时打开的成千上万个连接,这些连接每次只是发送少量的数据,例如聊天服务器,实现 NIO 的服务器可能是一个优势。同样,如果你需要维持许多打开的连接到其他计算机上,如 P2P 网络中,使用一个单独的线程来管理你所有出站接,可能是一个优势。一个线程多个连接的设计方案如
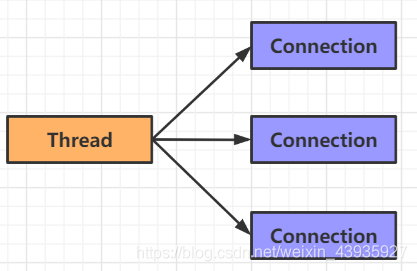
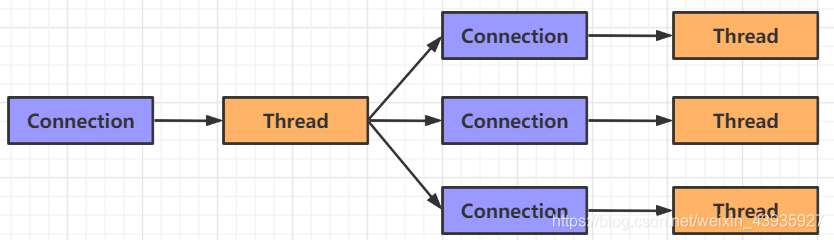
如果你有少量的连接使用非常高的带宽,一次发送大量的数据,也许典型的IO 服务器实现可能非常契合。下图说明了一个典型的IO 服务器设计:
总结
| 同步阻塞IO(BIO) | 伪异步IO | 非阻塞IO(NIO) | 异步IO(AIO) | |
|---|---|---|---|---|
| 客户端数:IO 线程数 | 1:1 | M:N(M>=N) | M:1 | M:0 |
| 阻塞类型 | 阻塞 | 阻塞 | 非阻塞 | 非阻塞 |
| 同步 | 同步 | 同步 | 同步(多路复用) | 异步 |
| API使用难度 | 简单 | 简单 | 复杂 | 一般 |
| 调试难度 | 简单 | 简单 | 复杂 | 复杂 |
| 可靠性 | 非常差 | 差 | 高 | 高 |
| 吞吐量 | 低 | 中 | 高 | 高 |
:Tomcat 打破双亲委派")



还没有评论,来说两句吧...